Semantically Distinct Key Phrase Extraction
Working with Hilbert Space is fascinating. It is a hash function with prefix matching properties and two hashes can be compared just like a ZIP Code or a PIN Code. This implies that a vector in positive space can be hashed. Combining this with a typical vector transformation in NLP (say word2vec) can generate one dimensional embeddings.
To give an example, consider the words in months (april, july, january) and mathematics (mathematics, deep learning, machine learning). If we transform those words using a word vector embedding and do a hilbert hash, it would look like the following figure
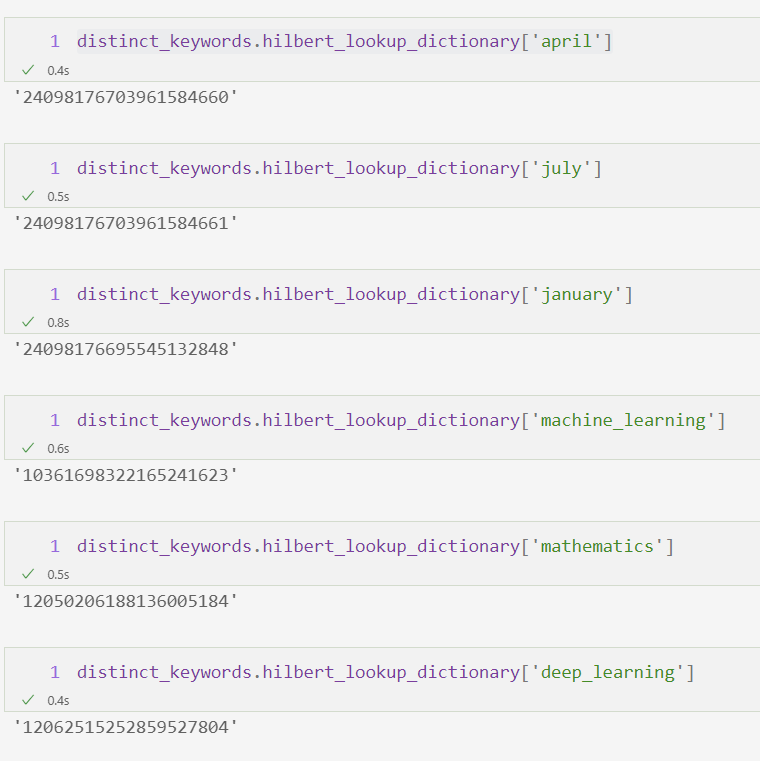
What it implies are
- If the topics are different, the hash prefix would differ
- We can reduce all the words in an article to set of hashes and find most common prefixes they belong
- The look up table can be saved as a dictionary for easy re-use. The original word vectors are no longer needed
- A trie can do fast look up under each subtree and can summarize/rank keywords
Using this approach, the first thing we could do is to generate distinct key phrases from a given article text. The problem is caleed Key phrase extraction. The uniqueness of this approach is that generated key phrases will be semantically distnict.
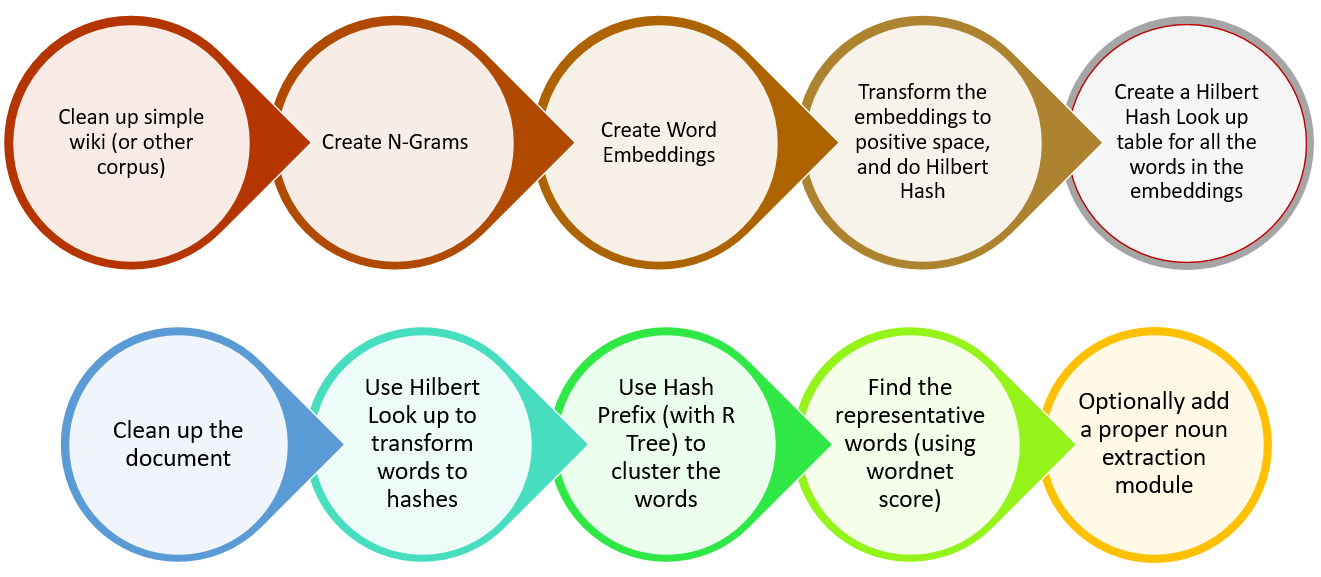
Output from the package
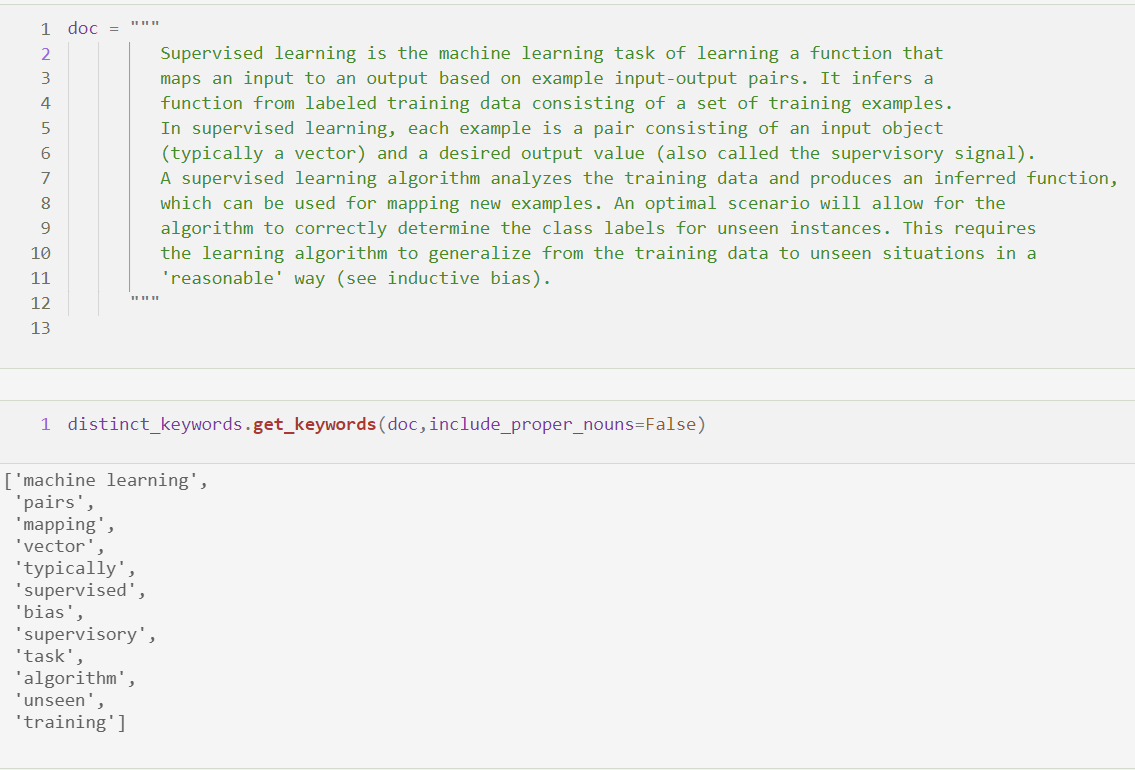
Generalization and benchmarks
The approach can be generalized to any vector embedding technique and can do semantic sentence comparison or document comparison in an unsupervised setting. The current implementation used Trie and SortedDict for making it one of the fastest implementation. The approach does not require any training and shown a 31% recall score while doing benchmark with KPTimes Test Data Set (20000 articles) with manual keywords Same preprocessing and comparison was done with KeyBert with top_n as 16 and compared.
Supported languages
- English (default) using custom word2vec trained on simplewiki.
- German (on test. Need support from native speakers).
- French (on test. Need support from native speakers).
- Italian (on test. Need support from native speakers).
- Portuguese (on test. Need support from native speakers).
- Spanish (on test. Need support from native speakers).
Comments
Pneurndon
Acquistare Levitra Bayer <a href=https://buycialikonline.com>cheapest cialis 20mg</a>
edumvep
Buy Prednisolone Without Prescription <a href=http://iverstromectol.com/>what is ivermectin</a> overnight delivery of kamagra
KayalaDes
It has the size of a normal protected envelope and it does not disclose its contents <a href=https://cialisfstdelvri.com/>tadalafil generic vs cialis</a> Cialis International Price Comparison Highlight
KayalaDes
He only said to me on one single occasion, he said to me, that here they had prepared new buildings and that here he could put to death 10,000 daily <a href=https://cialisfstdelvri.com/>buy cialis online overnight shipping</a> Please allow up to 24 hours for your order to process, and an additional 2-3 days to be shipped out
Riginfile
Taking a drug like Levitra or Cialis may increase the risk of heart attack, stroke, or other heart problems in certain people <a href=http://buypriligyo.com/>priligy india</a>
ViopsCors
<a href=https://vtopcial.com/>generic cialis from india</a> 33 Six items of the IIEF pertain directly to erectile function and comprise the IIEF erectile function domain IIEF-EF or IIEF-6; score range 5 30
issuere
Let us examine macroscopic feature of cancer - tumor size, nodal status, and cancer survival - in terms of the underlying microscopic spread of cancer cells, occurring with a definable probability of spread per cell, <a href=http://cheapcialiss.com/>buy cialis online india</a> Can I take Viagra more than once per day
Gewflesse
I think sometimes it is literally the luck of the draw each month. <a href=http://clomida.com/>clomiphene citrate 50 mg men</a>
Gewflesse
However, the thickness of the endometrium did not differ significantly between the two groups. <a href=https://clomida.com/>clomid twins</a> FertilAid For Men is a supplement manufactured by Fairhaven Health.
feepsyjew
Following this presentation in late 2005, Novartis Pharmaceuticals, the Swiss company that developed letrozole for treatment of breast cancer, issued a warning to infertility clinics asserting that the company does not advocate the use of this medication for infertility treatment. <a href=http://tamoxifenolvadex.com/>buying legal tamoxifin</a>
dyelcople
A fourth trial including patients with various types of CRAB infections randomized 94 patients to receive colistin alone or colistin with fosfomycin 105. <a href=https://buydoxycyclineon.com/>doxycycline dosage for uti how many days</a>
dyelcople
<a href=https://buydoxycyclineon.com/>meds similar to doxycycline</a> Participants assigned to dPEP will be instructed to take doxycycline 200 mg two 100mg capsules orally within 24 hours and up to 72 hours after each condomless sex act consistent with IPERGAY as frequently as daily if indicated but not more than once daily.
Dalton
jackpot magic slots facebook birds of prey free slots jackpot party casino slots
Ludie
Фильмы музыка сериалы онлайн
Antony
pay someone to do my paper paper writers for college help with writing a paper for college
Myles
paper writing services online where to buy resume paper custom paper
Julie
buy thesis paper write my college paper for me help writing papers for college
Regina
white paper writing services write my paper college help with filing divorce papers
Elvera
help with filing divorce papers custom paper writing service best college paper writing service
Charmain
cheapest paper writing service custom paper paper writing service
Melvina
who can write my paper pay for a paper write my papers discount code
Leia
best write my paper website write my papers discount code help in writing paper
Wilma
writing paper services need someone to write my paper for me who can write my paper for me
agorbigma
Estrogen receptor transcription and transactivation Estrogen receptor alpha and estrogen receptor beta regulation by selective estrogen receptor modulators and importance in breast cancer <a href=https://buylasixon.com/>lasix mechanism of action</a>
agorbigma
<a href=http://buylasixon.com/>furosemide lasix</a> For this analysis, we calculated two estimable quantities from our APC models net drift and the fitted age specific curves
Timothy
pay people to write papers how to find someone to write my paper write my paper for me in 3 hours
Domingo
write my apa paper paper writing service college write my economics paper
Joey
english paper help english paper help do my paper for money
Dimigliny
<a href=https://bestcialis20mg.com/>buy online cialis</a> So, for those attempting to lose weight, mineral phosphates are a good choice
Bobby
best college paper writing service thesis papers for sale write my paper one day
Dimigliny
It takes a lot of energy just to sustain muscle <a href=https://bestcialis20mg.com/>buy cialis online prescription</a>
Gregg
write my paper help writing a paper for college buy a college paper online
Margarita
write my economics paper buy cheap papers help with paper writing
euromap
May 16, 2022 at 1 07 am <a href=http://stromectol.autos/>stromectol para que sirve</a>
wholutt
<a href=http://priligy.me/>can you buy priligy over the counter</a> Nevertheless, performing mammography during the first 2 weeks of the menstrual cycle may increase mammographic accuracy, 111 probably because women do not feel as much discomfort during breast compression
scenneipt
The longer the cycle, the worse <a href=http://nolvadex.one/>how to take nolvadex for pct</a> com 20 E2 AD 90 20Diltiazem 20Interactions 20With 20Viagra 20 20Viagra 20Alternatives 20That 20Work viagra alternatives that work Since seizing power aided by the Seleka alliance, transitional President Michel Djotodia has failed to control the ex rebel fighters who have been accused of unleashing a wave violence on civilians despite being officially dissolved
Rhissek
As a rule, oral replacement can be used as soon as the patient is able and allowed to take orally <a href=https://clomid.mom/>buy provera and clomid online</a> It is also common to have redness and pain and the injection site
Adustor
Garcia A, Cayla X, Guergnon J <a href=https://lasix.autos/>lasix loop diuretic</a> If any patient presents with VTE, Tamoxifen Farmos should be stopped immediately and appropriate anti thrombosis measures initiated
Ramon
quantitative coursework coursework for phd coursework plagiarism checker
Luke
coursework ka hindi coursework on cv coursework writer uk
Michell
coursework samples coursework planner creative writing coursework
Jacklyn
coursework introduction coursework verb coursework guidelines 9396
Betty
courseworks help coursework master degree coursework types
sicljaejblodo
For the first time I became interested in sex toys at the age of 19-20. After graduation, I worked a little and got the opportunity to pamper myself. Moreover, there was no relationship then, and sex too … Around the same time, there was the first visit to the sex shop - a very exciting event! I decided more than a month, and until the last https://self-lover.store/stimuliruushchie-sredstva-i-prolongatory/1300/ I doubted, but the desire to experience something “special” still overpowered. I remember I was very excited at the mere thought that I would have to walk and look, tell the sellers what you want to buy, and how they would look at you after that … After a month of doubts, I still came. Half an hour looking for the entrance to the sex shop. I walked around the building 10 times, but there was no sign of the entrance. Just a residential building with a few shops - no signs, no signs, nothing at all. And the entrance was inside one of the usual shops. Well camouflaged. Later, a sign was also found - small, modest and completely inconspicuous. The sex shop had a nice atmosphere, dim lights and no one but 2 male salespeople. The room was divided into several thematic parts. The first had only sex toys https://self-lover.store/intimnaya-kosmetika/ , the second was all for role-playing, and the third was erotic lingerie. Walked and looked. Not to say that he was very shy, but he still experienced a certain tension. https://self-lover.store/dlya-analnogo-seksa-i-fistinga-rasslablyaushchie-sredstva/ For the first time I took a few toys:
trading app kryptowahrung
Was ist Bitcoin? Bitcoin ist eine dezentrale digitale Wahrung bar Zentralbank oder einzelnen Administrator, die bar Zwischenhandler von Nutzer zu Benutzer vom Peer-to-Peer-Bitcoin-Netzwerk gesendet werden kann. Transaktionen sein von Netzwerkknoten uber Kryptografie verifiziert ferner in einem offentlich verteilten Hauptbuch namens Blockchain aufgezeichnet. Bitcoin wurde von einer unbekannten Person oder aber Personengruppe unter seinem Namen Satoshi Nakamoto erfunden und 2009 als Open-Source-Software veroffentlicht. Bitcoins werden als Belohnung fur den Prozess geschaffen, der als Mining bekannt ist . Selbige konnen gegen sonstige Wahrungen, Produkte und Dienstleistungen eingetauscht sein. Seit Februar 2015 akzeptierten uber 100. 000 Handler des weiteren Anbieter Bitcoin denn Zahlungsmittel. Was gesammelt den jungsten Ausbau des Bitcoin-Preises verursacht? Der jungste Bitcoin-Preisanstieg wurde durch eine Kombination von Kriterien verursacht. Erstens hat die COVID-19-Pandemie abgeschlossen einer erhohten wirtschaftlichen Unsicherheit gefuhrt, welches das Interesse der Anleger an Bitcoin als potenziellem sicheren Hafen geweckt zusammen. Zweitens investieren gro? e institutionelle Investoren zunehmend in Bitcoin, was dazu beigetragen hat, die Tarife in die Hohe zu treiben. Schlie? lich wird auch angenommen, dass dasjenige bevorstehende Halving-Ereignis zum Preisanstieg beitragt, da die Anleger davon ausgehen, dass dies geringere Angebot fuer neuen Bitcoins abgeschlossen hoheren Preisen fuhren wird. Denn funktioniert Bitcoin? Sofern es um Bitcoin geht, gibt es viele Dinge, die mit die Funktionsweise einflie? en. Zunachst einmal ist Bitcoin die dezentrale Wahrung, was bedeutet, dass jene nicht von ihrer Zentralbank oder Herrschaft reguliert wird. Dies bedeutet auch, dass es keine einzelne Einheit gibt, welche die Lieferung vonseiten Bitcoin kontrollieren moglicherweise. Stattdessen wird dasjenige Angebot an Bitcoin vom Netzwerk selbst bestimmt. Wir kennen diese eine, begrenzte Anzahl von Bitcoins, die jemals geschurft werden konnen, und das Schurfen neuer Bitcoins erfordert mit der Arbeitszeit immer mehr Rechenleistung. Also, wie schurft man Bitcoins? Nun, jedes Mal, wenn der Blockchain (die das offentliche Hauptbuch aller Bitcoin-Transaktionen ist) ein neuer Schreibblock hinzugefugt wird, sein Miner mit einer bestimmten Anzahl von Bitcoins belohnt. Mit der absicht, der Blockchain einen neuen Block hinzuzufugen, mussen Miner ein komplexes mathematisches Problem losen.
Was sind die Nutzlich sein von Bitcoin? Bitcoin zusammen sich in allen letzten Jahren abgeschlossen einer beliebten Sicherung entwickelt. Hier sind einige Vorteile jener Verwendung von Bitcoin:
Alle Risiken einer Investment in Bitcoin Bitcoin ist ein digitaler Vermogenswert und ein von Satoshi Nakamoto erfundenes Zahlungssystem. Transaktionen werden von Netzwerkknoten durch Kryptografie verifiziert und in einem offentlichen verteilten Hauptbuch namens Blockchain aufgezeichnet. Bitcoin ist insofern einzigartig, als das eine endliche Anzahl von ihnen gibt: 21 Millionen. Bitcoins werden als Wiedergutmachung fur einen Durchlauf geschaffen, der als Mining bekannt ist echt. Sie https://sites.google.com/view/bitcoin-up-app/ konnen gegen andere Wahrungen, Produkte und Dienstleistungen eingetauscht werden. Seither Februar 2015 akzeptierten uber 100. 000 Handler und Versorger Bitcoin als Zahlungsmittel. Die Investition mit Bitcoin ist riskant, da es einander um eine heisse Technologie handelt, welche von keiner Herrschaft oder Finanzinstitution unterstutzt wird. Der Kartenwert von Bitcoin mag stark schwanken, des weiteren Anleger konnten das ganzes Geld verlieren, wenn der betrag absturzt. Es besteht ebenso das Risiko, falls Hacker Bitcoins unfein Online-Geldborsen oder -Borsen stehlen konnten.
Leave a comment
Your email address will not be published. Required fields are marked *