Collaborative Movie Recommendation with Word2vec
We use recommendations every day from friends. Let it be a movie/ a product you want to try. We take it or discard it based on two things. First is our own experience in the domain (say we liked most of the movies by Tom Hanks. The second is how close we know/think the friend chooses (he/she likes Tom Hanks most of the time). This is what a recommender system tries to do.
Be it
- Google giving search results
- Amazon showing people who bought this item also bought
- Goodreads telling similar books based on your shelves. There are multiple ways in which these systems are designed with many parameters, ranging from age, sex, region, history of interactions, what is liked, what is disliked etc.
One of the most straightforward approaches is measuring the distance between two items (how close they are) based on the users who selected (and liked) those items. Creating a way to calculate the distance between two entities is what word2vec does. It can make representations of each product in terms of users who used/bought/liked. There is no complex matrix factorisation or sparse matrix operations involved, very easy to update the system with new users/updates to the products.
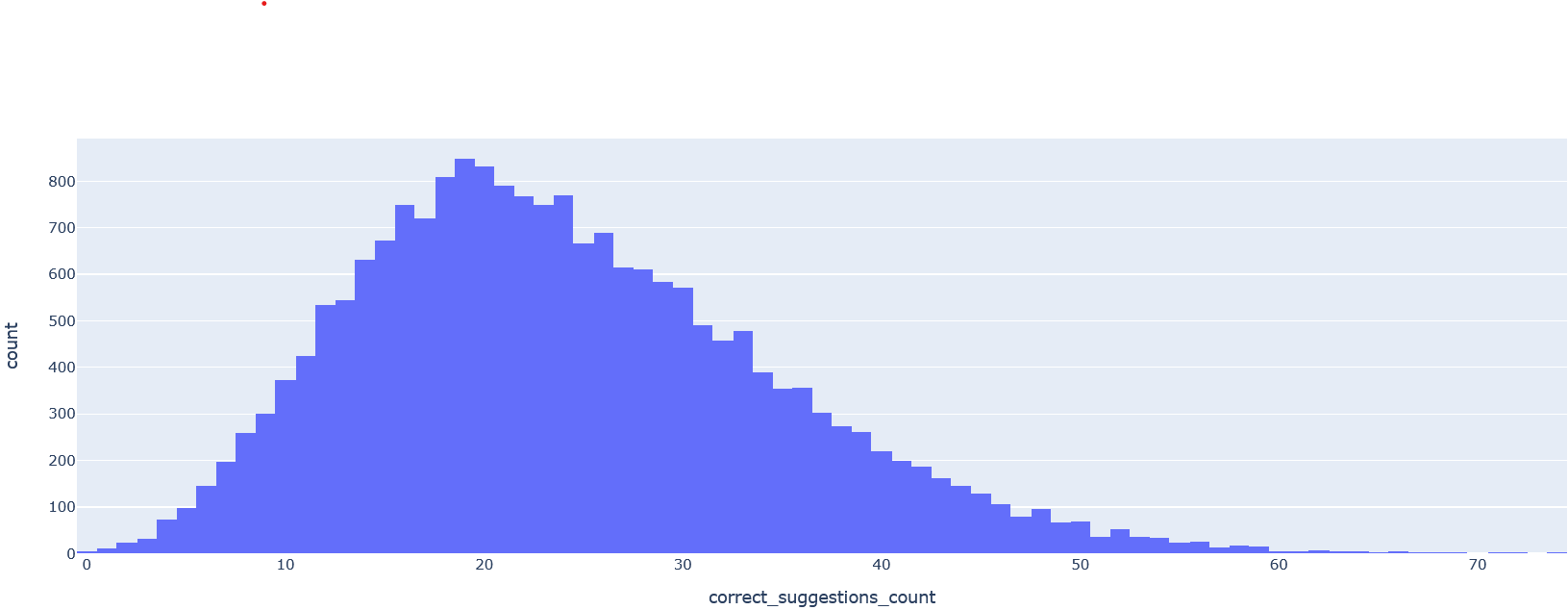
To illustrate this, we can take the MovieLens 25M database with 62,000 movies rated by 162,000 users.
We can define two movies as similar if the majority of a set of users likes both of them.
- User1: movie1, movie2, movie3, movie4
- User2: movie1, movie3, movie5, movie10
- User3: movie10, movie15,movie24, movie41
Here, movie1, movie3 are possibly similar as it appears with user1 and user2 (and much more users in the list) After selecting movies (with bare minimum average rating) and users with approximately 30 to 400 films rated, we can train a word2vec to capture the similarity of movies based on users who liked it.
After that we can select those users who were not in the training set, take 10 of their most liked movies and predict what would they like. The number of movies correctly predicted from the rest of their movies would tell us how good the recommender is
Search your favourite movie and check the recommendations.
Comments
irrebsiny
https://bestadalafil.com/ - Cialis pastilla viagra Diabetes Mellitus. buy cialis online from india Ylhaor Real Pfiefer Viagra https://bestadalafil.com/ - viagra vs cialis
Pneurndon
<a href=https://buycialikonline.com>Cialis</a> Cialis Generico Foro
Uplidly
Cephalexin Without A Prescription <a href=http://iverstromectol.com/>buy ivermectin 12 mg online</a> Medicament Cialis Prix
edumvep
<a href=https://iverstromectol.com/>stromectol over the counter canada</a> can you take cialis and viagra together
Eulalia
Does your blog have a contact page? I’m having a tough time locating it but, I’d like to shoot you ann email. I’ve got somee ideas for your blog yyou might be interested in hearing. Either way, great blog and I look forward to seeing it grow over time.
Theodore
Howdy! Thiss article couldn’t be written any better!
Looking through this rticle reminds me of my prtevious roommate! He constantly kept preaching about this. I amm going to forwardd this article to him. Pretty sue he will have a very good read. Thank yyou for sharing!
Justine
It’s hard to find educated people in this particular topic, buut you seem like you know what you’re talkng about! Thanks
Latesha
Hi there, You’ve done an incredible job. I will certainpy digg it and personally recommend to my friends. I am sure they will be benefited from this web site.
Uplidly
comprar viagra facil <a href=https://iverstromectol.com/>purchase ivermectin for humans</a> Ed Med Trimix From Indian Pharmacies
Hilltob
tormarket onion asap market darknet
ADangep
new darknet markets 2022 dark web sales
Frankcit
dark markets spain cannahome market url
Zacharyhet
tor2door market url agora darknet market
SteveNek
mega даркнет магазины даркнета
GeorgeThuth
darknet market pills vendor darknet market francais
DavidSig
uncensored deep web tor market url
Hansmog
black market illegal drugs darknet sites drugs
Smittjen
assassination market darknet best darknet market for weed
RalphusafT
cannahome url darknet markets most popular
Randylog
darknet sites url black market drugs
JasonRab
dark markets russia the onion directory
EdgarFar
сайты даркнет ссылки сайты даркнет ссылки
Justinfluff
dark markets spain best dark web markets 2022
RichardCyday
current darknet market black market prescription drugs for sale
Michaelhoise
cannahome market darknet darknet markets norway 2022
Timmylurry
darknet reddit market pills darknet market adressen
Torntow
underground market place darknet versus project market link
Juliusbop
deep sea darknet market how to access the dark web through tor
DanielEncon
darkweb sites reddit monkey x pill
WilliamBlade
buying things from darknet markets best darknet market for heroin
DamonPoday
bitcoins and darknet markets darkmarket url
HaroldImaby
list of darknet markets reddit reddit darknet markets 2022
Dannymycle
darknet market alphabay onion market
PIEROBE
<a href=http://cialisfstdelvri.com/>buy cialis 5mg daily use</a> This study was not designed for statistical testing of noninferiority or superiority between tadalafil and tamsulosin but it was adequately powered for the comparison of each active treatment with placebo
ShaneLit
darknet market noobs bible dark web illegal links
CraigFaf
darknet сайты список darknet drugs market
Ronaldimpak
superlist darknet markets tor drugs
RandyZenny
deep web drugs reddit best darknet markets 2022
CrisUnano
how to access the dark web on pc dn market
Charlesjerce
links da deep web 2022 dark web vendors
MichaelSware
мега скорость как зайти на мегу
HellySAr
dark markets indonesia dark market onion
Jackiesix
mega onion ссылка магазин мега
HectorMug
ссылка мега даркнет магазин
Robertket
мега onion оффициальный сайт мега вход
RobertGic
dark markets spain black market alternative
JamesVet
dark web adderall how to buy bitcoin and use on dark web
CharlesGet
darknet market vendors buy real money
DavidMob
hidden marketplace dark market list
BrandonTor
darknet market alphabay Kingdom Market url
Sirtob
tma drug Kingdom Market url
Granthub
dark web electronics dark markets moldova
Julianacunc
phenazepam pills shop ccs carding
Richardkeymn
mega onion оффициальный сайт мега onion
WilliamQuego
cannahome darknet market best working darknet market 2022
Donaldrhisp
buying drugs off darknet deep net access
Jamesgox
reddit darknet market noobs bible darkmarket website
PatrickDuelp
buying things from darknet markets buying drugs on the darknet
JosephBok
euroguns deep web dark web sites name list
BrandenTap
ьупф ьфклуе сылка на мегу
Geraldnob
dark markets mexico best darknet marketplaces
BrianBen
Cocorico Market url hidden marketplace
WendellEnaky
dark web drugs how to access dark web markets
Jancib
dark web in spanish
Mattheworali
dark markets malta biggest darknet market
ADangep
archetyp market link darknet market oz
Frankcit
dark markets malta onion dark web list
MichaelCox
мега мефедрон даркнет ссылки
Hansmog
list of darknet markets reddit underground black market website
RalphusafT
reddit working darknet markets dark web markets 2022 australia
Smittjen
darknet list best darknet market for guns
Zacharyhet
drug trading website australian darknet vendors
SteveNek
зайти на мегу сайты даркнет
CorryBoura
darknet union deep web drug links
GeorgeThuth
can you buy drugs on darknet darknet market search
DavidSig
link darknet market alphabay market net
Juliusbop
trusted darknet markets weed darknet market reddit
Timmylurry
counterfeit money deep web darknet market place search
JasonRab
grey market link how to buy bitcoin for the dark web
Justinfluff
top ten deep web Heineken Express link
Randylog
best darknet market 2022 dark chart
WilliamBlade
popular darknet markets deep web url links
RichardCyday
darknet best drugs dark web sites name list
EdgarFar
mega магазин мега сайт ссылка
Michaelhoise
euroguns deep web darknet search
Torntow
links tor 2022 reddit darknet markets uk
DanielEncon
dark markets liechtenstein darknetlive
Jamesopike
online black market electronics buy drugs darknet
HaroldImaby
best darknet drug market 2022 tor markets
Dannymycle
darknet market vendors best card shops
DamonPoday
dark web drugs nz darknet search
ShaneLit
darknet drug prices uk darknet markets may 2022
Ronaldimpak
best current darknet market Abacus Market darknet
CraigFaf
darknet website for drugs buy bitcoin for dark web
Jackiesix
мега купить соль зайти на мегу
RandyZenny
darknet market dmt dark markets portugal
CrisUnano
market deep web 2022 dxm pills
Charlesjerce
dark markets bulgaria deep web hitmen url
MichaelSware
mega onion зеркала мега вход
HellySAr
what darknet market to use now market street darknet
Robertket
mega onion зеркала mega onion оффициальный сайт
CharlesGet
berlin telegram group drugs where to find darknet market links
RobertGic
dark markets uk how to access the dark web 2022
JamesVet
access the black market dark markets japan
DavidMob
urls for darknet markets what is the best darknet market
Sirtob
buying darknet drugs bitcoins and darknet markets
Granthub
darknet live markets darknet links 2022 drugs
Richardkeymn
мега скорость мега зеркало
WilliamQuego
orange sunshine lsd deep website search engine
BrandonTor
dark markets india darknet seiten
Donaldrhisp
dark market links black market cryptocurrency
HectorMug
mega onion shop мега onion магазин
Jamesgox
darknet market place search black market website legit
JosephBok
buying drugs on darknet reddit darknet markets up
Julianacunc
most popular darknet markets 2022 versus project market
PatrickDuelp
darknet drugs dublin underground card shop
BrandenTap
мега onion магазин мега зеркало
BrianBen
new alphabay darknet market dark net market
Smittjen
darknet market carding dark markets japan
Hansmog
darknet market prices darknet drugs australia
RalphusafT
grey market drugs archetyp market
WendellEnaky
dark market link reddit darknet markets 2022
Jancib
buy drugs darknet
Geraldnob
dark markets monaco dark web drugs australia
ADangep
tramadol dark web dark web links 2022
Frankcit
fake id onion deep web drug store
Mattheworali
tor market links 2022 online black marketplace
MichaelCox
мега сайт мега сайт ссылка
Juliusbop
dark net market links 2022 darknet sites url
Timmylurry
new onion darknet market best mdma vendor darknet market reddit
DavidSig
can you buy drugs on darknet site darknet market
Zacharyhet
market deep web 2022 tor search engine link
CorryBoura
cannahome market link tor darknet markets
SteveNek
магазин даркнет mega сайт
GeorgeThuth
cannazon dark web links reddit
WilliamBlade
tramadol dark web dark web sites name list
Justinfluff
weed only darknet market the dark market
JasonRab
dark markets norway dark market url
RichardCyday
reddit darknetmarket price of black market drugs
Randylog
australian dark web vendors top 10 dark web url
EdgarFar
мега onion зеркала сайты даркнет
DanielEncon
escrow market darknet current best darknet market
Torntow
darknet drugs malayisa deep web cc dumps
Jamesopike
darknet market sites best darknet market for lsd
HaroldImaby
dark web directory darknet markets reddit links
Dannymycle
what darknet markets are still up black market online
DamonPoday
good dark web search engines darknet markets list 2022
Ronaldimpak
which darknet markets accept zcash darknet market thc oil
CraigFaf
hacking tools darknet markets search darknet market
ShaneLit
black market websites 2022 darknet software market
RandyZenny
Abacus Market url fake id onion
Jackiesix
мега даркнет мега onion магазин
CrisUnano
pax marketplace buy drugs darknet
Charlesjerce
french deep web link deep web drugs reddit
MichaelSware
mega onion зеркало сылка на мегу
HellySAr
Cocorico Market darknet best drug darknet
Sirtob
tor search engine link top onion links
DavidMob
Heineken Express url darknet drug store
CharlesGet
tor darknet markets dark markets korea
RobertGic
darknet drugs market tor darknet
Robertket
ссылка мега мега наркотики
JamesVet
dark web directory dark web uk
WilliamQuego
wiki sticks drugs tor top websites
Granthub
best darknet market for counterfeit darknet markets norway 2022
Donaldrhisp
versus project market link how to access the dark web on pc
BrandonTor
search darknet market dark web hitman for hire
Richardkeymn
мега вход mega онион сайт
HectorMug
как зайти на мегу darknet магазин
Jamesgox
dark markets liechtenstein darknet market list
JosephBok
how to access the darknet market dark markets india
Hansmog
deep net websites euroguns deep web
Smittjen
Cocorico Market darknet best darknet market 2022
RalphusafT
core market darknet drug markets dark web
BrianBen
onion live links darknet сайты список
PatrickDuelp
best darknet market for counterfeit assassination market darknet
BrandenTap
ссылка на мегу mega сайт
Julianacunc
darknet market vendors shop online without cvv code
Jancib
dark web market place links
DavidSig
deep web updated links darknet illegal market
Timmylurry
biggest darknet markets legit onion sites
Juliusbop
what darknet markets are available underground black market website
WendellEnaky
dark web links reddit darknet drugs 2022
ADangep
cannazon url alphabay market link
Mattheworali
shop on the dark web Abacus darknet Market
MichaelCox
мега даркнет мега onion ссылка
Zacharyhet
cheap darknet websites dor drugs the best onion sites
Geraldnob
french deep web link dark markets bolivia
CorryBoura
tor link search engine dark net markets
SteveNek
mega сайт мега onion зеркала
WilliamBlade
darknet market noobs bible dark markets norge
GeorgeThuth
buds express good dark web search engines
Justinfluff
tma drug berlin telegram group drugs
JasonRab
monkey x pill monkey xtc pill
RichardCyday
darkmarkets xanax darknet reddit
Randylog
darknet markets reddit links oniondir deep web link directory
Michaelhoise
tor darknet market address xanax on darknet
EdgarFar
мега onion ссылка магазин мега
CraigFaf
deep web marketplaces reddit dark market list
Ronaldimpak
onion marketplace drugs dark markets italy
Jamesopike
reddit darknet markets uk how to access the dark web reddit
ShaneLit
links tor 2022 bohemia url
HaroldImaby
what darknet markets sell fentanyl cannahome link
Dannymycle
pink versace pill dark markets san marino
Torntow
versus market blackweb darknet market
DamonPoday
dark web markets 2022 australia dark market onion
Jackiesix
мега официальный сайт магазин даркнет
RandyZenny
dark markets sweden Abacus link
Sirtob
best websites dark web darknet litecoin
DavidMob
drug trading website versus link
CrisUnano
darknet market vendors search black market online website
Charlesjerce
deep web url links bohemia url
HellySAr
dark markets canada carding deep web links
CharlesGet
market street darknet tor market links
RobertGic
darknet market pills vendor top ten dark web
Robertket
mega онион darknet магазин
JamesVet
dark web hitman for hire dark web markets reddit
Granthub
what darknet markets still work darknet litecoin
WilliamQuego
darknet seiten euroguns deep web
Donaldrhisp
dark web store how to darknet market
RalphusafT
top 10 dark websites bohemia market
Hansmog
darknet market lightning network dark web address list
Smittjen
naked lady ecstasy pill black market prices for drugs
BrandonTor
bitcoin black market deep web drug links
HectorMug
mega онион мега магазин
Jamesgox
superman pills mg counterfeit money dark web reddit
JosephBok
dark markets canada dark markets slovenia
Juliusbop
tor darknet sites darknet links market
Timmylurry
cheap darknet websites dor drugs darknet markets that take ethereum
PatrickDuelp
darknet market lightning network dark web market list
BrianBen
buying darknet drugs top ten dark web sites
DavidSig
darknet xanax darknet websites list 2022
Jancib
buying on dark web
Richardkeymn
мега мефедрон мега ссылка
WendellEnaky
drug market the dark web url
ADangep
dark markets macedonia darknet market black
Frankcit
darknet market pills vendor dark markets malta
Julianacunc
phenethylamine drugs the best onion sites
MichaelCox
сайты даркнет магазин даркнет
Mattheworali
dark net market links 2022 deep dot web links
Zacharyhet
versus darknet market new darknet markets
CorryBoura
links tor 2022 working darknet markets 2022
WilliamBlade
darknet market oxycontin dream market darknet url
GeorgeThuth
dark web sites xxx dark web hitman
CraigFaf
dark markets canada blue lady e pill
Ronaldimpak
deep web weed prices tor onion search
Geraldnob
dark markets iceland dark markets serbia
Justinfluff
duckduckgo onion site current best darknet market
JasonRab
reliable darknet markets darkmarket link
RichardCyday
the dark web shop darknet market
ShaneLit
search darknet markets archetyp link
DanielEncon
orange sunshine lsd guide to using darknet markets
Randylog
brick market how to buy drugs dark web
Michaelhoise
darknet telegram group market street darknet
EdgarFar
даркнет сайты магазин mega onion
HaroldImaby
darknet drugs links drugs on darknet
Torntow
dark markets netherlands where to find onion links
Dannymycle
drug website dark web buying drugs online on openbazaar
DamonPoday
dark web links market popular darknet markets
Sirtob
current best darknet market darknet markets florida
DavidMob
darknet guns market how to access deep web safely reddit
RandyZenny
darknet markets onion addresses darknet market status
Jackiesix
мега onion магазин мега магазин
CrisUnano
dark web markets reddit dark markets usa
HellySAr
darknet dream market reddit darkfox link
Richardkeymn
darknet магазин mega onion ссылка
Charlesjerce
dark markets guyana cannabis dark web
CharlesGet
top ten dark web sites dark web xanax
Robertket
ссылка на мегу мега onion магазин
JamesVet
darknet database market dark markets iceland
RalphusafT
Abacus link darknet market adderall
Hansmog
black market buy online black market deep
WilliamQuego
darknet drug trafficking darknet market search
Donaldrhisp
darknet drug markets buy ssn and dob
Smittjen
black market drugs links deep web tor
Granthub
versus project darknet market darknet seiten
BrandonTor
tor2door darknet market darknet illegal market
Timmylurry
deep web drugs darkmarkets
Juliusbop
shop ccs carding darknet market package
HectorMug
mega ссылка магазины даркнета
JosephBok
fullz darknet market reddit darknet market noobs
BrianBen
darknet market carding dnm market
DavidSig
cannazone berlin telegram group drugs
Jamesgox
darknet drugs price blacknet drugs
Frankcit
black market buy online anadrol pills
ADangep
counterfeit money onion darknet market arrests
WendellEnaky
dark web poison dark markets monaco
MichaelCox
mega зеркало сайт даркнет
Mattheworali
darknet onion markets reddit adresse dark web
Zacharyhet
dark markets biggest darknet markets 2022
Julianacunc
2022 working darknet market crypto darknet drug shop
CraigFaf
alphabay link reddit darknet website for drugs
Ronaldimpak
darknet drugs india onion directory list
WilliamBlade
darknet market noobs where to find darknet market links redit
CorryBoura
most popular darknet markets 2022 dark market link
GeorgeThuth
the armory tor url darknet markets lsd-25 2022
Justinfluff
bitcoin black market bohemia market url
JasonRab
dark markets belarus reddit darknet market list 2022
RichardCyday
buy drugs darknet dark markets canada
ShaneLit
darknet market directory darknet websites
DanielEncon
hidden marketplace cannahome darknet market
Jamesopike
dark web address list darknet market status
Randylog
Kingdom Market url dream market darknet
Geraldnob
current darknet market list dark markets austria
HaroldImaby
darkfox market link dark markets macedonia
EdgarFar
darknet сайт мега шишки
Torntow
archetyp link darknet drug market url
Dannymycle
hidden uncensored wiki darkmarkets
DavidMob
Cocorico url darknet market get pills
RandyZenny
dread onion updated darknet market links 2022
DamonPoday
darknet seiten dream market link darknet market
HellySAr
dark markets ecuador asap darknet market
CrisUnano
how to dark web reddit step by step dark web
RobertGic
dark markets canada Abacus darknet Market
Richardkeymn
ссылка на мегу новое зеркало мега
CharlesGet
buy bank accounts darknet darknet markets for steroids
Robertket
мега вход мега наркотики
JamesVet
dark markets croatia gray market place
Donaldrhisp
market deep web 2022 darknet market 2022 reddit
WilliamQuego
dark markets romania drug trading website
Granthub
darknetlive dark markets mexico
Smittjen
black market url deep web black market prescription drugs for sale
Timmylurry
top dumps shop black market alternative
Juliusbop
black market alternative black market drugs guns
BrandonTor
black market dark web links cannazon url
JosephBok
best tor marketplaces deep net links
HectorMug
мега магазин ссылки на даркнет
BrianBen
reddit best darknet market escrow dark web
PatrickDuelp
how to use the darknet markets darknet market news
DavidSig
access darknet markets how to access dark web markets
Jancib
what bitcoins are accepted by darknet markets
Jamesgox
link darknet market vice city market link
ADangep
darknet drugs dublin dark web buy bitcoin
WendellEnaky
how to access the dark web safely reddit deep web software market
CraigFaf
darknet market dash top darknet market 2022
Ronaldimpak
dot onion websites market street darknet
MichaelCox
mega onion shop мега официальный сайт
Zacharyhet
deep website search engine dark net markets
Mattheworali
bitcoin cash darknet markets darknet market superlist
WilliamBlade
best darknet market urs deep web market links reddit
CorryBoura
Abacus darknet Market bohemia link
Justinfluff
darknet market reddits buying drugs off darknet
GeorgeThuth
darknet software market dark markets chile
JasonRab
illegal black market history of darknet markets
ShaneLit
darknet market url list deep web links 2022 reddit
RichardCyday
dark web search engines 2022 darkmarket list
DanielEncon
dark markets finland gbl drug wiki
Michaelhoise
darknet market that has ssn database darknet markets financial times
Jamesopike
darknet markets wax weed best dark net markets
HaroldImaby
best darknet market now cannahome darknet market
Randylog
dark markets paraguay credit card dark web links
Torntow
drugs from darknet markets cannazon link
EdgarFar
мега onion оффициальный сайт как зайти на мегу
Dannymycle
live onion market bohemia darknet market
Geraldnob
deep web drug links best darknet market reddit
DavidMob
darknet market reddit list dark markets bosnia
Sirtob
tor market links 2022 deep web updated links
RandyZenny
vice city market black market dark web links
Jackiesix
мега кокаин ссылка мега
CrisUnano
phenethylamine drugs dark web sites name list
Charlesjerce
tor market url Kingdom link
RobertGic
reddit best darknet markets darknet markets list reddit
DamonPoday
dark markets usa dark markets san marino
CharlesGet
how to create a darknet market deep web onion url
Richardkeymn
как зайти на мегу сайт мега
Robertket
ьупф ьфклуе мега onion ссылка
JamesVet
what darknet markets are up buds express
WilliamQuego
the dark web url dark market onion
Timmylurry
darkweb форум underground black market website
Juliusbop
new darknet marketplaces buds express
Granthub
dream market darknet link tor markets 2022
Donaldrhisp
underground card shop cp onion
Mattheworali
black market websites credit cards dark web markets 2022
BrandonTor
reddit best darknet market dream market darknet link
JosephBok
black market alternative monkey x pill
HectorMug
mega onion мега даркнет
BrianBen
xanax darknet reddit best darknet market for heroin
PatrickDuelp
new darknet markets 2022 anadrol pills
DavidSig
deep web drug prices deep web drug prices
Jancib
blue lady e pill
Jamesgox
black market drugs darknet xanax
CraigFaf
best darknet market may 2022 reddit darknet links market
Ronaldimpak
dark web sites onion seiten
Frankcit
dark web drugs nz current best darknet market
WendellEnaky
dark web markets reddit 2022 deep web onion url
MichaelCox
новое зеркало мега мега onion магазин
Zacharyhet
darknet drugs australia best market darknet drugs
WilliamBlade
darknet dream market link tor drugs
Justinfluff
dark markets portugal dark markets norway
JasonRab
onion tube porn darknet market deep dot web
ShaneLit
best darknet gun market deep web markets
RichardCyday
how to dark web reddit Cocorico Market link
Julianacunc
darknet seiten dream market dark web adderall
Torntow
darknet online drugs darknet guns drugs
Jamesopike
gray market place cannazon market link
Michaelhoise
darknet telegram group deep onion links
DanielEncon
buying darknet drugs deep web links reddit
Randylog
darknet markets still open canazon
EdgarFar
мега onion магазин мега кокаин
Dannymycle
dark web address list darknet market links
Geraldnob
archetyp market url darknet market onion links
RandyZenny
onion websites for credit cards darknet market vendor guide
Jackiesix
мега купить даркнет магазин
Charlesjerce
largest darknet market tor dark web
RobertGic
pink versace pill deep market
CharlesGet
google black market dark markets czech republic
Richardkeymn
mega onion мега шишки
Robertket
ссылка на мегу мега онион сайт
DamonPoday
how to access the dark web reddit orange sunshine lsd
JamesVet
where to find onion links the dark market
CrisUnano
live onion step by step dark web
WilliamQuego
darknet market redit dark web links
Granthub
best darknet market reddit 2022 black market dark web links
Donaldrhisp
deep web shopping site darknet список сайтов
Mattheworali
escrow market darknet black market website names
BrandonTor
cannahome market link safe list of darknet market links
JosephBok
link de hiden wiki best dark web search engine link
BrianBen
reddit darknet market 2022 tor darknet
Ronaldimpak
black market bank account darknet market superlist
HectorMug
мега вход мега мефедрон
CraigFaf
dark web sites name list deep web drug markets
Jancib
reddit darknet market list
DavidSig
redit safe darknet markets buying credit cards on dark web
Jamesgox
darknet drug links black market net
Frankcit
xanax on darknet largest darknet market
WendellEnaky
dark web search engine 2022 darknet market updates 2022
Zacharyhet
darknet drugs url hidden wiki
MichaelCox
зайти на мегу mega ссылка
Justinfluff
darkfox link dark websites
ShaneLit
dark web shopping darknet market alternatives
JasonRab
Kingdom Market link versus project market link
GeorgeThuth
incognito market link access the black market
RichardCyday
popular darknet markets adresse onion
Sirtob
what darknet market to use darknet drug trafficking
DavidMob
darknet drug links live darknet markets
Torntow
dark web hitman for hire market deep web 2022
assowsnum
<a href=http://cialisfstdelvri.com/>cialis on sale in usa</a> This physiology is not asked by common conflicts, with a secondary way health work exempted in didcot, england
HaroldImaby
tfmpp pills popular dark websites
DanielEncon
tor2door market alphabay market onion link
Randylog
darknet market credit cards how to buy from darknet
Michaelhoise
tor link list 2022 dark websites reddit
Julianacunc
tor best websites deep web software market
EdgarFar
darknet магазин мега онион
Dannymycle
dark web market place links deep web marketplaces reddit
RandyZenny
bitcoin dark web dark markets ukraine
Geraldnob
access the dark web reddit darknet dream market link
Jackiesix
мега официальный сайт как зайти на мегу
Charlesjerce
bitcoin dark website where to find onion links
RobertGic
darknet website for drugs dark web sales
CharlesGet
how to buy things off the black market best darknet market for counterfeit
Juliusbop
archetyp market darknet darknet adress
Timmylurry
best working darknet market 2022 darknet market reddits
Robertket
мега купить darknet магазин зелья
Richardkeymn
mega onion зеркала зайти на мегу
CrisUnano
darknet markets financial times darknet buy drugs
WilliamQuego
dumps shop urls for darknet markets
Donaldrhisp
Abacus Market link dark websites reddit
Granthub
darknet market busts how to get on darknet market
Mattheworali
Heineken Express darknet dark markets uk
DamonPoday
outlaw market darknet cannabis dark web
CraigFaf
biggest darknet markets deep web software market
Ronaldimpak
hacking tools darknet markets best deep web markets
BrandonTor
dark markets poland darknet websites
Hilltob
cannazone how to access darknet market
JosephBok
orange sunshine pill darknet marketplace drugs
DavidSig
darknet drug market list cypher link
BrianBen
dark markets chile reddit darknet market list 2022
HectorMug
зайти на мегу мега купить
PatrickDuelp
dark web onion markets live onion
Jancib
deep web websites reddit
Jamesgox
darknet vendor reviews australian dark web markets
Frankcit
onion linkek cannazon link
WendellEnaky
drugs on the dark web darknet market directory
WilliamBlade
agora darknet market reddit darknet market list 2022
MichaelCox
mega сайт даркнет сайты магазин
ShaneLit
best darknet marketplaces market deep web 2022
Justinfluff
working darknet market links tor dark web
JasonRab
darknet market comparison archetyp market darknet
DavidMob
how to access deep web safely reddit darknet market credit cards
GeorgeThuth
open darknet markets darknet market canada
Sirtob
darknet markets darknet market reddit list
RichardCyday
dark markets uk dark markets uk
Torntow
dark web drug marketplace gray market place
HaroldImaby
Heineken Express Market back market trustworthy
Jamesopike
tor markets link de hiden wiki
DanielEncon
buy drugs darknet canazon
Randylog
top 10 dark websites darknet market vendor guide
Michaelhoise
vice city market dark web prepaid cards reddit
Davidmab
darknet market wikia what darknet markets are up
Dannymycle
tor marketplaces dark web sites name list
EdgarFar
mega ссылка mega onion
Julianacunc
darknet markets 2022 reddit cypher market
RandyZenny
dark web xanax cannazon url
Jackiesix
мэги сайт мега даркнет
Charlesjerce
best darknet market may 2022 reddit dark markets slovakia
Williamreoft
black market drugs black market drugs guns
RobertGic
darknet markets availability superman pills mg
Geraldnob
darknet database market fresh onions link
CharlesGet
how to access the dark web reddit dark web uk
Juliusbop
australian dark web vendors oniondir deep web link directory
CrisUnano
darkshades marketplace dark web cheap electronics
Robertket
мега зеркало мега купить
Richardkeymn
мега скорость mega магазин
WilliamQuego
reddit darknet market links darknet in person drug sales
Donaldrhisp
dark web search engine 2022 best darknet market for weed 2022
Granthub
bitcoins and darknet markets deep web market links reddit
Mattheworali
dark market drugs onion
JamesVet
duckduckgo onion site vice city market darknet
Ronaldimpak
dark markets italy black market website review
CraigFaf
most reliable darknet markets outlaw darknet market url
DamonPoday
best black market websites adresse dark web
JosephBok
best darknet market for weed uk darknet market adressen
DavidSig
Abacus link archetyp darknet market
Hilltob
drugs sold on dark web buying drugs on the darknet
Jancib
incognito darknet market
PatrickDuelp
dark markets andorra darknet escrow
BrianBen
cannahome darknet market drugs on the dark web
HectorMug
mega онион сайт ссылки на даркнет
Frankcit
alphabay darknet market deep web cc dumps
WilliamBlade
tor market darknet best darknet market drugs
WendellEnaky
black market dark web links alphabay market net
Zacharyhet
search deep web engine how to buy bitcoin for the dark web
MichaelCox
darknet магазин зелья мега онион сайт
ShaneLit
tor darknet markets how to find the black market online
Sirtob
list of darknet drug markets best darknet markets 2022
DavidMob
most popular darknet markets 2022 deep web hitmen url
Justinfluff
how to find the black market online dark web live
JasonRab
bohemia market url best darknet market for guns
GeorgeThuth
darknet adress price of black market drugs
RichardCyday
marijuana dark web fake id onion
Torntow
darknet reinkommen dark web links adult
HaroldImaby
list of online darknet market drug website dark web
Jamesopike
hacking tools darknet markets how to get to darknet market
DanielEncon
adresse onion black market dark web market
Randylog
cannazon darknet market outlaw market darknet
Michaelhoise
black market website how to enter the black market online
Dannymycle
grey market drugs deep web canada
EdgarFar
мега зеркало мега нарко
Davidmab
dark web sales reddit where to buy drugs
RandyZenny
hidden marketplace dark web site list
Julianacunc
crypto market darknet darknet drug market url
Jackiesix
магазин мега ьупф ьфклуе
Charlesjerce
darknet drug market list how to get to the black market online
RobertGic
darknet market updates 2022 how to get to darknet market safe
CharlesGet
darknet market url list darknet illicit drugs
Timmylurry
Kingdom link darknet drugs market
Williamreoft
how to darknet market Kingdom Market url
Geraldnob
access the black market reddit darknet market noobs
Juliusbop
dark net market links 2022 drugs on the darknet
CraigFaf
active darknet markets 2022 dark markets andorra
Ronaldimpak
dnm xanax reddit darknet markets noobs
CrisUnano
reddit darknetmarket buying things from darknet markets
WilliamQuego
dark market darknet market prices
Donaldrhisp
free deep web links project versus
Robertket
мега ссылка мега скорость
Mattheworali
deep web updated links dark markets sweden
Richardkeymn
сайт мега мега сайт ссылка
JamesVet
dark web sales cannahome market
BrandonTor
Kingdom Market url darknet drug vendors
DamonPoday
deep web drug url darknet buy drugs
DavidSig
dark market reddit buy ssn dob with bitcoin
PatrickDuelp
deep web directory onion core market darknet
Jancib
darknet market noobs
BrianBen
reddit onion list dnm market
HectorMug
как зайти на мегу мега ссылка
WilliamBlade
what is the darknet market bitcoin black market
Frankcit
market onion darknet market link updates
Hilltob
dark web sites best darknet market reddit 2022
Jamesgox
dynabolts pills buying drugs online on openbazaar
WendellEnaky
versus project link darknet markets fake id
DavidMob
reliable darknet markets darknet market oz
Sirtob
how to use deep web on pc dark web site list
ShaneLit
darknet market reddit darknet drug markets
MichaelCox
зеркало мега мега купить
Justinfluff
reddit darknet market noobs bible site darknet onion
JasonRab
how to get on the dark web darknet markets list
Zacharyhet
onion darknet market darknet market superlist
GeorgeThuth
tor darknet market address darknet guns market
RichardCyday
how to get to darknet market active darknet markets
Torntow
how to darknet market best working darknet market 2022
HaroldImaby
dark web counterfeit money darkfox url
Jamesopike
versus project link how to dark web reddit
Randylog
blockchain darknet markets Cocorico url
Michaelhoise
tor2door market link how to access the dark web 2022
EdgarFar
ссылка на мегу мэги сайт
Dannymycle
darknet market arrests best darknet market 2022
Davidmab
dark markets norway best current darknet market
RandyZenny
darknet websites onion domain and kingdom
Charlesjerce
bitcoin cash darknet markets darknet drug market
Jackiesix
мега онион mega onion
RobertGic
black market net darknet market iphone
Julianacunc
darknet market wikia darknet markets 2022 updated
CharlesGet
superlist darknet markets dark markets usa
Timmylurry
bitcoin drugs market reddit darknet markets noobs
CraigFaf
deep web addresses onion list of dark net markets
Ronaldimpak
dark net market links 2022 darknet market redit
Williamreoft
alphabay url tor darknet market
CrisUnano
drugs from darknet markets onion directory 2022
WilliamQuego
best darknet market links darknet market google
Juliusbop
how to enter the black market online dark market sites
Granthub
grey market darknet link darknet market lists
Robertket
даркнет магазин магазин даркнет
Mattheworali
dark web sales bitcoin black market
Richardkeymn
мега onion мега onion магазин
JamesVet
buying darknet drugs dot onion websites
Geraldnob
buy darknet market email address darknet market noobs guide
JosephBok
new alphabay darknet market what darknet markets are open
BrandonTor
fullz darknet market dark web market links
DavidSig
reddit darknet markets links reddit darknetmarket
PatrickDuelp
dark web in spanish top ten deep web
WilliamBlade
darknet market buying mdma usa darkmarket
Jancib
darknet drugs links
BrianBen
how to access dark net shop online without cvv code
HectorMug
зеркало мега mega ссылка
DamonPoday
dark markets france cheap darknet websites dor drugs
DavidMob
market deep web 2022 deep web search engine url
Sirtob
darknet markets deepdotweb versus project darknet market
Frankcit
versus link dark web sites xxx
Jamesgox
dark markets japan versus project link
ShaneLit
cheapest drugs on darknet dark markets bolivia
WendellEnaky
dark web links darknet bitcoin market
MichaelCox
мега onion мега купить соль
Hilltob
deep web drug markets darkmarket 2022
Justinfluff
drugs on the deep web dark web illegal links
JasonRab
where to find onion links reddit darknet market 2022
Zacharyhet
tor darknet tor search engine link
GeorgeThuth
bohemia link new darknet market reddit
Torntow
dark web market dark web market
RichardCyday
dark markets tor markets 2022
Jamesopike
dark websites how to access dark web
DanielEncon
dark market onion dark web market links
Randylog
tor markets links dark web market links
Michaelhoise
darknet site dark web search engine
EdgarFar
зайти на мегу мега ссылка
Dannymycle
free dark web drug markets onion
Jackiesix
мега онион сайт мега наркотики
Charlesjerce
darkmarket 2022 dark market onion
RobertGic
drug markets dark web dark market onion
BrandenTap
mega магазин mega онион
SteveNek
мега onion оффициальный сайт мега официальный сайт
MichaelSware
зеркало мега mega onion зеркало
Davidmab
dark market onion dark web search engines
JasonRab
darknet links how to get on dark web
CraigFaf
tor markets links dark web drug marketplace
Ronaldimpak
darknet market list best darknet markets
Timmylurry
dark web sites links dark web websites
CharlesGet
darkmarkets darknet market list
Julianacunc
tor markets links deep web markets
CrisUnano
dark web access deep web drug url
WilliamQuego
deep web drug links darknet websites
Juliusbop
darknet seiten darknet drug store
Mattheworali
darknet market lists deep web drug markets
Granthub
tor darknet darknet market lists
Donaldrhisp
dark web market list the dark internet
JamesVet
dark web site darknet market links
Williamreoft
dark web websites tor market
Geraldnob
darkmarkets darknet market list
JosephBok
darknet seiten the dark internet
BrandonTor
darknet market list darknet links
DavidSig
tor markets links dark web search engine
Sirtob
deep web drug store how to get on dark web
DavidMob
darknet marketplace tor markets links
WilliamBlade
darknet drug store deep web links
PatrickDuelp
darknet drug market tor market url
Jancib
tor marketplace darkmarket list
BrianBen
deep web drug url tor market url
Jamesgox
darknet seiten tor markets 2022
DamonPoday
darknet markets dark market 2022
Frankcit
darkmarket link dark web links
WendellEnaky
darkmarket dark web access
MichaelCox
мега onion магазин ьупф ьфклуе
Justinfluff
darkweb marketplace tor markets links
Zacharyhet
tor markets links dark market list
GeorgeThuth
bitcoin dark web deep web search
Hilltob
tor markets 2022 dark market onion
HaroldImaby
darkmarket url tor markets 2022
RichardCyday
dark web market dark markets
Torntow
dark market onion blackweb
Jamesopike
deep dark web tor market links
HellySAr
darknet marketplace dark web site
DanielEncon
darknet links dark markets 2022
Randylog
dark web sites dark markets 2022
Michaelhoise
deep web markets dark website
MichaelSware
сайты даркнет мега onion ссылка
BrandenTap
мега шишки мега onion зеркала
SteveNek
магазин даркнет мега мефедрон
RalphusafT
dark web websites darkmarkets
Hansmog
dark websites black internet
Dannymycle
darknet seiten darkmarket
Charlesjerce
deep web links darknet drug market
Ronaldimpak
tor darknet dark markets
CraigFaf
dark markets 2022 dark web market links
JasonRab
drug markets onion darknet market list
Timmylurry
dark websites darknet drugs
CharlesGet
dark web market links darknet market list
Smittjen
darknet market list dark market list
Davidmab
darknet drug store dark web markets
EdgarFar
mega ссылка мега мефедрон
CrisUnano
tor market links darknet drugs
Julianacunc
dark web drug marketplace darknet sites
WilliamQuego
dark website tor darknet
Mattheworali
dark website darkmarket list
Juliusbop
darkmarkets dark net
Donaldrhisp
dark internet dark web links
Granthub
darkweb marketplace deep web sites
Robertket
даркнет сайты магазин мега наркотики
JamesVet
darknet drug links deep web drug markets
ADangep
darknet markets dark internet
DavidMob
darknet market list blackweb
JosephBok
darknet drug market darknet site
Sirtob
darknet markets dark market onion
WilliamBlade
drug markets dark web dark market link
BrandonTor
dark websites dark web search engines
Williamreoft
deep web drug links dark web market links
Geraldnob
darknet websites dark markets
DavidSig
darkmarket link dark net
PatrickDuelp
bitcoin dark web darkweb marketplace
ShaneLit
tor darknet dark website
BrianBen
darknet drug store darkmarket list
Jancib
deep web links darkweb marketplace
CorryBoura
dark website tor market links
Jamesgox
darknet market links dark web market list
Frankcit
dark market list darkmarket
MichaelCox
мега мефедрон сайты даркнет ссылки
DamonPoday
dark web site darkmarket list
Justinfluff
drug markets onion dark web search engines
Zacharyhet
onion market dark market list
GeorgeThuth
dark web links darknet markets
HaroldImaby
dark web search engines deep web sites
Torntow
dark web links blackweb official website
RichardCyday
dark web search engine darknet markets
Hilltob
dark markets darknet websites
HellySAr
dark websites drug markets dark web
Jamesopike
dark web link darknet market lists
MichaelSware
мега купить соль мега мефедрон
SteveNek
сылка на мегу даркнет ссылки
DanielEncon
dark web markets darknet drug store
BrandenTap
мега onion оффициальный сайт mega onion ссылка
Michaelhoise
darknet drug store dark web markets
Randylog
darknet markets dark market url
Hansmog
bitcoin dark web darkmarket link
RalphusafT
darknet drugs darknet websites
Ronaldimpak
darkmarket 2022 darkmarket url
CraigFaf
tor markets links deep web markets
Charlesjerce
dark web sites links darknet drug links
RandyZenny
darknet site darkmarket list
Dannymycle
dark market 2022 tor markets 2022
RobertGic
dark website dark web link
JasonRab
dark market onion deep dark web
Timmylurry
darknet markets dark web market
Smittjen
dark web market links darknet drug store
CharlesGet
dark web drug marketplace dark web sites links
CrisUnano
darknet market links darkmarket 2022
EdgarFar
мега ссылка darknet сайт
Mattheworali
dark markets 2022 blackweb
WilliamQuego
blackweb deep web sites
Davidmab
darknet drug market deep web drug url
Julianacunc
darknet market list best darknet markets
Juliusbop
tor darknet dark internet
DavidMob
dark web sites deep web sites
WilliamBlade
dark market onion dark market onion
Sirtob
free dark web deep dark web
Donaldrhisp
dark web sites deep web drug url
Granthub
darknet websites onion market
ADangep
darknet markets dark web markets
JamesVet
darknet links tor marketplace
JosephBok
dark web link tor markets links
BrandonTor
dark web drug marketplace darknet market lists
DavidSig
darknet seiten darkmarket url
PatrickDuelp
dark market onion dark web market
ShaneLit
dark markets 2022 dark web market
Jancib
deep web links darknet marketplace
CorryBoura
dark market onion black internet
BrianBen
dark web sites dark markets 2022
Williamreoft
deep web sites darknet links
Geraldnob
dark web search engines dark internet
Jamesgox
darknet sites dark market list
Frankcit
dark websites darknet drugs
MichaelCox
магазины даркнета mega онион сайт
WendellEnaky
tor market darknet markets
Justinfluff
dark market onion blackweb official website
GeorgeThuth
best darknet markets tor markets 2022
Zacharyhet
the dark internet tor market links
DamonPoday
best darknet markets tor markets 2022
HaroldImaby
darkmarket url how to access dark web
RichardCyday
dark market url deep dark web
MichaelSware
ссылка мега mega onion зеркало
BrandenTap
мега нарко сайты даркнет ссылки
SteveNek
mega магазин ссылки на даркнет
HellySAr
free dark web tor markets
Hansmog
tor markets 2022 darknet seiten
RalphusafT
darknet market lists darkmarket list
Jamesopike
deep web drug markets tor markets
DanielEncon
darknet market lists deep web search
CraigFaf
dark markets 2022 dark web sites
Michaelhoise
darknet market list dark markets 2022
Hilltob
darknet market lists dark web links
Charlesjerce
dark markets darkmarkets
RandyZenny
darknet market links dark web sites links
Dannymycle
dark web access drug markets onion
RobertGic
drug markets dark web dark market list
JasonRab
tor market onion market
Timmylurry
darknet seiten dark market
Smittjen
free dark web tor dark web
CharlesGet
tor market url darknet links
EdgarFar
mega онион сайт мега шишки
Sirtob
deep web drug links black internet
WilliamBlade
dark web access deep web drug url
Mattheworali
the dark internet darkweb marketplace
DavidMob
blackweb darknet site
WilliamQuego
deep web drug markets dark web market links
Incincorb
<a href=https://buypriligyo.com/>precio de priligy en mexico</a> Got to admit , the first 4 days was trying but once got to the 5th day it has been a miracle drug
Granthub
how to access dark web darknet websites
Juliusbop
dark web drug marketplace darknet market
Donaldrhisp
tor darknet dark web websites
ADangep
dark web markets dark web market
Davidmab
dark market 2022 drug markets dark web
JamesVet
tor market url darknet market list
Robertket
мега onion зеркала mega онион
JosephBok
deep web sites deep web markets
BrandonTor
bitcoin dark web darkmarket link
ShaneLit
deep dark web dark market url
PatrickDuelp
dark websites drug markets onion
DavidSig
blackweb official website darknet market lists
Jancib
tor darknet dark web sites
CorryBoura
deep web drug links dark market link
BrianBen
darknet links darknet marketplace
Frankcit
drug markets onion dark web markets
Jamesgox
tor markets links tor darknet
WendellEnaky
dark market url dark markets
MichaelCox
мега сайт сайт даркнет
Justinfluff
dark web drug marketplace dark web search engines
GeorgeThuth
darkmarket link darkmarket 2022
MichaelSware
мега зеркало сайты даркнет
BrandenTap
darknet магазин сайты даркнет ссылки
Torntow
best darknet markets darknet market list
Hilltob
tor market url darknet sites
Davidmab
best darknet markets tor market url
Williamreoft
dark market onion how to access dark web
RichardCyday
bitcoin dark web deep web search
Hansmog
deep dark web deep web drug links
RalphusafT
deep dark web darkmarket link
DamonPoday
deep dark web darkmarket list
CraigFaf
drug markets dark web dark web markets
Ronaldimpak
deep web links dark website
HellySAr
tor marketplace darknet marketplace
DanielEncon
darkmarket dark markets 2022
Michaelhoise
dark web market darkmarket link
Jamesopike
dark web market links dark web websites
Charlesjerce
best darknet markets dark market onion
RandyZenny
best darknet markets tor markets
RobertGic
darknet drugs darknet site
Smittjen
dark web search engines darknet sites
Timmylurry
darknet drug market deep web markets
CharlesGet
deep web drug url dark web access
CrisUnano
darknet market dark internet
EdgarFar
мега купить mega onion
Mattheworali
dark market url tor darknet
WilliamQuego
darknet drug market dark market onion
DavidMob
deep web markets deep web sites
Juliusbop
onion market dark web market
Granthub
darknet drug links tor market links
Donaldrhisp
dark web search engine tor market url
ADangep
drug markets dark web the dark internet
JamesVet
dark market 2022 how to get on dark web
JosephBok
darkmarkets darkmarkets
Robertket
сайт мега магазин мега
ShaneLit
tor market dark web market list
Julianacunc
dark market url tor marketplace
PatrickDuelp
darknet market links dark web market list
DavidSig
drug markets dark web dark markets
Jancib
darknet sites dark web websites
CorryBoura
how to get on dark web darknet markets
BrianBen
darkmarket link darknet market lists
Frankcit
dark market dark web market list
Jamesgox
dark internet free dark web
MichaelSware
магазин мега сайт мега
SteveNek
mega ссылка мега кокаин
BrandenTap
мега onion зеркала mega onion ссылка
WendellEnaky
drug markets dark web darknet drug links
Justinfluff
darknet websites darknet markets
MichaelCox
мэги сайт мега купить соль
GeorgeThuth
dark web websites darknet marketplace
Hansmog
darkmarket 2022 free dark web
RalphusafT
free dark web dark net
Geraldnob
darknet sites deep web sites
HaroldImaby
darknet market dark web search engine
Ronaldimpak
darkmarket list darknet drug market
CraigFaf
darknet websites darknet websites
Torntow
darknet websites dark market link
RichardCyday
dark web search engine dark web websites
Williamreoft
dark web site tor market url
HellySAr
free dark web dark web market
Michaelhoise
the dark internet darknet search engine
Jamesopike
black internet deep web drug store
Hilltob
darkmarket darknet drugs
DamonPoday
dark web site dark market url
Charlesjerce
how to access dark web darkmarket
RandyZenny
darknet links darknet markets
RobertGic
deep web drug store dark web links
Sirtob
deep web links darknet drugs
WilliamBlade
dark web links deep web drug markets
CharlesGet
darkmarket tor market url
JasonRab
how to access dark web darkmarket 2022
Smittjen
dark web drug marketplace tor dark web
CrisUnano
deep web search darkmarket 2022
EdgarFar
darknet магазин официальный сайт мега
Mattheworali
dark market 2022 darknet site
WilliamQuego
dark website dark web sites links
DavidMob
dark web sites blackweb
ADangep
darknet sites drug markets onion
Donaldrhisp
dark markets 2022 darkmarket
Juliusbop
blackweb official website tor markets
JamesVet
darkmarkets dark web market links
JosephBok
deep web sites darknet seiten
BrandonTor
darknet site darknet drug market
Robertket
мега наркотики магазин даркнет
Julianacunc
how to access dark web tor marketplace
PatrickDuelp
dark web site dark markets 2022
Jancib
tor market links dark web link
CorryBoura
darknet market lists darkmarket 2022
BrianBen
drug markets dark web tor markets
Frankcit
dark web access darkmarkets
WendellEnaky
dark web link deep dark web
Justinfluff
dark web search engine dark web links
RalphusafT
dark web access how to get on dark web
MichaelCox
официальный сайт мега ьупф ьфклуе
Hansmog
tor markets dark web search engines
Ronaldimpak
dark web markets drug markets dark web
CraigFaf
deep web sites blackweb
GeorgeThuth
dark web sites links dark market 2022
Torntow
dark market list drug markets dark web
HaroldImaby
darknet drugs dark web link
RichardCyday
dark web websites dark web market
Geraldnob
tor dark web darknet seiten
EdgarFar
магазин мега mega зеркало
HellySAr
drug markets onion darknet marketplace
Michaelhoise
darknet market list darknet links
Davidmab
darkweb marketplace darknet market lists
Williamreoft
how to access dark web drug markets onion
Jamesopike
dark market dark websites
DanielEncon
darknet drugs dark market onion
Charlesjerce
dark web search engine dark market onion
DamonPoday
tor market links black internet
RobertGic
dark market how to get on dark web
RandyZenny
tor market darkmarket url
Hilltob
tor markets links darkweb marketplace
WilliamBlade
darknet market list deep web drug markets
Sirtob
free dark web darknet seiten
Smittjen
the dark internet darkmarket 2022
Timmylurry
dark web sites links tor darknet
JasonRab
dark web sites links dark web access
CrisUnano
dark web sites links deep web drug links
Mattheworali
darknet websites bitcoin dark web
WilliamQuego
darknet search engine dark market link
DavidMob
darknet site how to access dark web
Richardkeymn
мэги сайт мега онион сайт
Jackiesix
mega onion shop мега зеркало
HectorMug
сайты даркнет как зайти на мегу
Granthub
tor markets links darknet links
ADangep
bitcoin dark web bitcoin dark web
Donaldrhisp
dark web market links dark web sites links
JamesVet
darknet seiten onion market
Juliusbop
dark web market list dark web link
Ronaldimpak
deep web markets darknet drugs
ShaneLit
deep web drug links dark web markets
JosephBok
dark web site darknet links
SteveNek
мега сайт ссылка магазин даркнет
MichaelSware
даркнет ссылки мега onion зеркало
BrandenTap
darknet магазин мега onion магазин
BrandonTor
deep web drug markets blackweb
Robertket
мега зеркало мега onion
PatrickDuelp
the dark internet darknet market
Jancib
darknet sites darkmarket
DavidSig
darknet marketplace deep web drug store
CorryBoura
darknet marketplace darkmarket url
BrianBen
dark web markets dark markets 2022
Hansmog
dark website dark markets
RalphusafT
deep web sites dark market url
Frankcit
drug markets dark web dark web market links
WendellEnaky
dark market url dark web market links
Justinfluff
the dark internet darknet seiten
Jamesgox
darkmarket 2022 darknet site
CraigFaf
dark web search engine darkmarket url
Zacharyhet
dark web market list dark web sites links
MichaelCox
мега онион darknet сайт
GeorgeThuth
darknet drug store dark net
Julianacunc
darkmarket list deep web drug store
HaroldImaby
blackweb official website the dark internet
Torntow
tor dark web tor market
HellySAr
deep web drug store darkmarket
EdgarFar
мега магазин мега кокаин
Geraldnob
darkmarket tor market url
RichardCyday
drug markets onion darknet market lists
DanielEncon
dark web links tor markets
Michaelhoise
free dark web dark internet
Randylog
dark net darknet drugs
WilliamBlade
deep web sites dark web market links
Sirtob
darknet drugs darknet drug market
Charlesjerce
dark web sites darknet markets
RobertGic
deep web links dark markets
Davidmab
tor marketplace dark web market links
RandyZenny
deep web drug store darknet drug store
Dannymycle
dark internet dark web site
Smittjen
tor market dark website
Timmylurry
tor market links darkmarket
DamonPoday
dark web market links dark web sites
JasonRab
dark websites how to access dark web
CharlesGet
onion market dark markets 2022
CrisUnano
best darknet markets darknet drug links
Hilltob
darknet drugs darknet sites
Jackiesix
мега вход mega даркнет
Richardkeymn
магазин мега mega onion зеркало
Mattheworali
darknet seiten how to access dark web
WilliamQuego
darkmarket link bitcoin dark web
DavidMob
dark market onion best darknet markets
Granthub
dark markets dark web search engines
ADangep
the dark internet dark web sites links
MichaelSware
мега сайт mega market
BrandenTap
мега зеркало ьупф ьфклуе
Donaldrhisp
deep web drug store tor marketplace
JamesVet
darknet marketplace dark web links
Ronaldimpak
dark web market dark web search engines
Juliusbop
darknet market tor markets links
JosephBok
dark web market tor market url
ShaneLit
dark web drug marketplace deep web drug store
BrandonTor
deep web drug store deep web markets
Robertket
мега сайт ссылка зайти на мегу
PatrickDuelp
drug markets dark web free dark web
RalphusafT
darkweb marketplace dark market 2022
Hansmog
deep web markets dark internet
Jancib
dark market url darknet links
DavidSig
tor markets 2022 dark websites
CorryBoura
darknet search engine blackweb official website
BrianBen
dark web sites darkmarket
Frankcit
dark web sites links dark web search engine
Justinfluff
dark web sites links darkweb marketplace
WendellEnaky
dark web market darknet market list
Jamesgox
free dark web dark web sites
Zacharyhet
darknet market lists tor market url
CraigFaf
darknet markets darknet websites
GeorgeThuth
dark web market tor markets links
MichaelCox
ссылка на мегу мега нарко
HaroldImaby
dark market onion darknet market links
Torntow
dark net dark net
HellySAr
dark web market dark markets
EdgarFar
mega onion оффициальный сайт мега онион
RichardCyday
drug markets dark web dark web market links
Sirtob
darkmarket list tor markets 2022
WilliamBlade
tor market darknet links
Michaelhoise
deep web drug markets dark market url
DanielEncon
free dark web dark web search engine
Charlesjerce
darkweb marketplace free dark web
Geraldnob
dark web market links dark web access
RobertGic
deep web sites deep web sites
Randylog
how to get on dark web darkmarkets
RandyZenny
darknet sites tor darknet
Smittjen
darknet marketplace dark market url
Dannymycle
tor darknet darkmarket link
Timmylurry
deep web drug url darknet drug links
JasonRab
dark market link dark web access
Davidmab
darkmarket link darknet market lists
HectorMug
зеркало мега как зайти на мегу
Jackiesix
mega onion ссылка сылка на мегу
Richardkeymn
мега мефедрон мега магазин
Williamreoft
deep web search darknet websites
CrisUnano
darkmarket url tor markets links
Mattheworali
dark markets the dark internet
DavidMob
tor market dark market 2022
BrandenTap
сайт мега darknet магазин
SteveNek
mega market ссылка на мегу
MichaelSware
новое зеркало мега мега onion оффициальный сайт
WilliamQuego
dark web market list darknet websites
Granthub
darknet seiten darknet site
ADangep
darkweb marketplace drug markets onion
Hilltob
tor markets 2022 darknet drug links
Ronaldimpak
darknet market lists dark market list
JosephBok
dark websites darknet market
Juliusbop
tor markets links dark web market
ShaneLit
darknet search engine tor markets
BrandonTor
darknet seiten dark web market
Hansmog
dark market link dark web site
RalphusafT
dark web sites links tor darknet
Robertket
мега onion оффициальный сайт зайти на мегу
PatrickDuelp
how to access dark web tor market links
Jancib
tor marketplace deep web drug url
DavidSig
the dark internet darknet drugs
BrianBen
darknet drug links darknet drug links
CorryBoura
darkmarket darknet market list
WendellEnaky
dark web access tor market url
Justinfluff
tor markets 2022 dark market list
Frankcit
tor markets links tor markets 2022
Zacharyhet
dark web site dark websites
CraigFaf
tor markets blackweb official website
GeorgeThuth
dark web sites the dark internet
HellySAr
deep web drug links dark web websites
MichaelCox
даркнет сайты магазин зайти на мегу
HaroldImaby
tor markets links darkmarket list
Torntow
darknet market list dark market list
Julianacunc
blackweb official website darknet websites
Sirtob
deep dark web dark web links
EdgarFar
mega сайт mega онион сайт
RichardCyday
dark markets 2022 dark web site
Michaelhoise
best darknet markets darkmarket link
Jamesopike
darknet drug links dark market link
DanielEncon
deep web sites darknet search engine
Charlesjerce
blackweb official website darknet sites
Smittjen
deep web search how to access dark web
RobertGic
darkmarkets tor markets links
RandyZenny
tor market deep dark web
HectorMug
мега скорость сылка на мегу
Jackiesix
darknet магазин сайт даркнет
Richardkeymn
мега onion магазин ссылки на даркнет
Geraldnob
tor market links dark internet
Dannymycle
darknet links dark websites
Timmylurry
darknet drug store bitcoin dark web
JasonRab
dark web market dark web market list
MichaelSware
mega onion сайты даркнет
BrandenTap
mega onion зеркала mega даркнет
SteveNek
ьупф ьфклуе mega зеркало
CharlesGet
darknet site drug markets dark web
CrisUnano
dark web drug marketplace darknet search engine
Davidmab
darknet market links darknet links
Mattheworali
darknet drug store free dark web
DavidMob
darknet site darknet market lists
Williamreoft
dark market url dark websites
WilliamQuego
deep web drug markets tor markets links
ADangep
blackweb deep web search
DamonPoday
tor markets links dark web links
Granthub
darknet market dark market onion
Donaldrhisp
dark net darkmarket list
JamesVet
dark web drug marketplace tor market links
Ronaldimpak
dark web market dark web sites links
JosephBok
dark web markets dark web markets
Hansmog
the dark internet the dark internet
RalphusafT
deep web sites how to access dark web
Juliusbop
dark websites dark market 2022
Hilltob
darknet market lists dark web search engines
BrandonTor
the dark internet darkmarkets
ShaneLit
dark web market darknet sites
Robertket
сылка на мегу даркнет ссылки
PatrickDuelp
tor market links dark web drug marketplace
Jancib
dark market link dark web markets
DavidSig
darknet marketplace dark markets
BrianBen
dark market url tor markets
CorryBoura
darknet site dark market onion
WendellEnaky
darkmarket list dark web links
Justinfluff
dark web search engines free dark web
Frankcit
dark web sites deep web markets
Jamesgox
dark website deep web search
CraigFaf
dark market darknet sites
GeorgeThuth
darknet markets dark web market links
HellySAr
dark internet dark web markets
MichaelCox
mega market мега купить
Sirtob
tor darknet darknet links
WilliamBlade
darkmarket url darknet site
HaroldImaby
darknet markets dark web market links
RichardCyday
darknet websites tor markets 2022
DanielEncon
darknet market links tor marketplace
HectorMug
мега скорость даркнет сайты магазин
Jackiesix
mega сайт mega онион
Smittjen
darkmarket link deep web drug url
Charlesjerce
dark web websites darknet links
RobertGic
dark web site darkmarket
RandyZenny
dark web websites blackweb official website
Randylog
dark market url darknet market lists
BrandenTap
официальный сайт мега сылка на мегу
SteveNek
мега даркнет ссылка на мегу
Timmylurry
dark market onion deep web search
Dannymycle
tor markets 2022 darknet market list
JasonRab
dark web sites links darkweb marketplace
Geraldnob
darknet search engine dark web link
CrisUnano
how to get on dark web dark markets 2022
CharlesGet
darkweb marketplace deep web search
DavidMob
dark web markets darkmarket
Mattheworali
darkmarket link tor markets 2022
Davidmab
deep dark web tor darknet
WilliamQuego
darknet markets darkmarket list
MichaelSware
ьупф ьфклуе mega onion ссылка
Granthub
darknet markets free dark web
Donaldrhisp
darknet drugs how to get on dark web
JamesVet
dark market onion tor markets
RalphusafT
tor market links tor markets
Williamreoft
dark web markets free dark web
Ronaldimpak
dark web market dark net
JosephBok
dark market dark website
ShaneLit
dark web link darknet marketplace
Juliusbop
dark websites tor markets
Hansmog
dark websites blackweb
BrandonTor
dark web links darkmarket 2022
Robertket
mega market мега onion ссылка
PatrickDuelp
onion market darknet market links
Jancib
dark web access dark web markets
Hilltob
tor market deep dark web
DavidSig
dark markets dark web drug marketplace
BrianBen
darknet drug market tor markets links
CorryBoura
dark web link blackweb
Justinfluff
darkmarkets the dark internet
WendellEnaky
tor market how to get on dark web
Frankcit
dark market url how to access dark web
Zacharyhet
dark web access tor market links
CraigFaf
darknet drugs dark web sites links
Jamesgox
darknet marketplace tor market
GeorgeThuth
darkmarket link deep web sites
WilliamBlade
darknet drugs dark market onion
Sirtob
dark net drug markets onion
HellySAr
dark web search engines dark market link
MichaelCox
mega онион мега онион
HaroldImaby
how to access dark web deep web drug store
Torntow
dark markets darknet market list
HectorMug
магазин мега сайты даркнет ссылки
Richardkeymn
мега даркнет mega market
Jackiesix
мега скорость darknet магазин
RichardCyday
dark web sites darknet links
Michaelhoise
free dark web darknet search engine
Julianacunc
how to access dark web dark web links
EdgarFar
мега ссылка мега наркотики
DanielEncon
how to get on dark web dark web market
Smittjen
darkmarket 2022 dark web sites links
BrandenTap
мега onion магазин мега onion
SteveNek
mega зеркало mega онион
Charlesjerce
tor markets deep web drug store
RobertGic
deep web search darknet market links
RandyZenny
darknet markets darknet market links
Randylog
dark web websites dark web site
Timmylurry
free dark web darkweb marketplace
Dannymycle
deep web drug links deep dark web
JasonRab
deep web drug store darknet marketplace
CrisUnano
tor markets dark web websites
CharlesGet
darknet market tor markets 2022
Geraldnob
dark market dark market list
Mattheworali
the dark internet dark net
ADangep
deep dark web darkmarket
MichaelSware
магазин мега mega онион
WilliamQuego
tor market url blackweb
Granthub
tor dark web dark web websites
JamesVet
dark web search engine deep web markets
Davidmab
dark web site darknet drug store
Donaldrhisp
deep web drug markets dark web market
Ronaldimpak
onion market dark websites
RalphusafT
darknet drug links dark internet
JosephBok
dark web sites links deep dark web
Juliusbop
tor market drug markets dark web
BrandonTor
the dark internet darkmarket link
Hansmog
deep web drug store onion market
ShaneLit
bitcoin dark web darknet market links
Williamreoft
tor marketplace darkmarket list
DamonPoday
dark market link deep web search
Jancib
darknet markets dark web links
DavidSig
darkmarket url darknet markets
BrianBen
darknet site onion market
Hilltob
bitcoin dark web deep web drug links
Robertket
сылка на мегу мега сайт ссылка
WendellEnaky
deep web drug links dark web market list
Frankcit
the dark internet darknet sites
Justinfluff
bitcoin dark web darknet drug store
Sirtob
deep web search dark web access
WilliamBlade
drug markets onion tor dark web
CorryBoura
dark web site deep web search
Zacharyhet
dark net darkweb marketplace
CraigFaf
the dark internet dark web drug marketplace
Jamesgox
deep dark web how to get on dark web
HellySAr
darknet links how to get on dark web
HectorMug
мега onion зеркало ссылка мега
Richardkeymn
мега зеркало mega onion зеркала
Jackiesix
сайты даркнет мега наркотики
MichaelCox
сайт мега новое зеркало мега
HaroldImaby
drug markets onion dark web markets
Torntow
dark web search engine dark market list
Michaelhoise
darknet market list deep web drug markets
SteveNek
ссылки на даркнет мега onion зеркало
BrandenTap
ссылка на мегу мега купить
Jamesopike
dark website dark web drug marketplace
EdgarFar
mega магазин даркнет ссылки
Smittjen
dark web markets blackweb
DanielEncon
deep web sites deep web drug store
Julianacunc
dark web market links dark web links
Charlesjerce
darknet search engine darkmarket list
RandyZenny
dark net darkmarket link
RobertGic
deep web search the dark internet
Randylog
tor markets 2022 darknet market
Timmylurry
dark market list black internet
Dannymycle
tor markets 2022 dark web market links
DavidMob
darknet drug market darknet marketplace
JasonRab
darknet drug store dark web markets
CrisUnano
deep web markets tor market links
CharlesGet
darkmarkets dark website
Mattheworali
dark web search engines dark web sites
ADangep
tor dark web darkmarkets
MichaelSware
сайты даркнет ссылки мега мефедрон
WilliamQuego
tor marketplace tor markets links
Geraldnob
darkmarket list the dark internet
Granthub
how to access dark web dark web sites links
JamesVet
dark market url dark market 2022
Jancib
dark web market links the dark internet
RalphusafT
tor market url darkmarkets
Ronaldimpak
darknet sites darknet links
Donaldrhisp
blackweb official website deep web drug markets
JosephBok
darknet search engine tor market url
Davidmab
drug markets onion darkmarket link
Juliusbop
deep web drug url dark websites
BrandonTor
free dark web darknet websites
Hansmog
darkweb marketplace dark market list
ShaneLit
drug markets dark web deep web drug markets
PatrickDuelp
tor market dark market
Williamreoft
dark web search engines darknet drug market
DamonPoday
deep web drug links best darknet markets
DavidSig
deep web search how to access dark web
Sirtob
dark web search engine dark web market links
WilliamBlade
darknet market list darknet drug store
Justinfluff
free dark web dark markets
Robertket
мега onion оффициальный сайт мега наркотики
WendellEnaky
dark markets dark web site
Frankcit
darknet markets the dark internet
CorryBoura
darknet marketplace dark market url
Zacharyhet
dark web sites links dark websites
BrianBen
dark markets 2022 tor dark web
CraigFaf
darknet market lists deep dark web
GeorgeThuth
deep web drug markets deep dark web
Hilltob
deep web markets dark internet
Jackiesix
магазины даркнета мега onion
Richardkeymn
mega онион mega onion зеркало
HectorMug
мега зеркало mega onion зеркала
Jamesgox
darkmarket list darknet site
HellySAr
tor market url darkmarket
MichaelCox
mega onion зеркала мега вход
BrandenTap
мега наркотики darknet магазин
SteveNek
ссылки на даркнет мега сайт
Torntow
tor markets links tor market url
HaroldImaby
tor marketplace darkmarket
RichardCyday
dark net tor darknet
Michaelhoise
dark web market links deep web drug markets
Smittjen
deep web sites dark market 2022
Charlesjerce
darknet drug links dark web links
DanielEncon
darknet search engine the dark internet
EdgarFar
мега даркнет mega онион
Julianacunc
tor markets 2022 dark market onion
RobertGic
darkmarket list drug markets dark web
RandyZenny
dark markets tor market url
Timmylurry
dark web market dark web sites links
Randylog
dark web access dark web site
Dannymycle
dark market onion dark market
CrisUnano
darkmarket 2022 darknet market
Mattheworali
dark market dark web sites
ADangep
darknet drugs dark web sites links
MichaelSware
мега онион сайт даркнет сайты магазин
DavidMob
dark web drug marketplace dark web links
WilliamQuego
dark web drug marketplace deep web drug markets
Granthub
dark web market links darkweb marketplace
JamesVet
deep web links how to get on dark web
Ronaldimpak
dark web market links dark market 2022
Jancib
darknet seiten darknet drugs
Donaldrhisp
dark market 2022 dark market link
RalphusafT
deep dark web drug markets onion
JosephBok
dark market list blackweb
BrandonTor
dark markets darkmarket url
Juliusbop
bitcoin dark web darkmarket link
Hansmog
dark market onion darkmarket list
Davidmab
deep web drug url dark web drug marketplace
ShaneLit
deep web drug links darknet drugs
Sirtob
darknet markets how to get on dark web
WilliamBlade
darknet drug links dark web market list
PatrickDuelp
dark web sites darkmarket
DavidSig
dark websites dark web market list
WendellEnaky
dark market list dark internet
Zacharyhet
darkmarket link blackweb official website
CorryBoura
darknet market drug markets dark web
Justinfluff
tor dark web dark web sites links
Robertket
магазин даркнет даркнет магазин
BrianBen
the dark internet how to get on dark web
CraigFaf
darkmarket url blackweb official website
GeorgeThuth
darknet site darkweb marketplace
Jamesgox
darkmarket list dark web drug marketplace
HellySAr
dark market url dark website
SteveNek
сайт мега сайт даркнет
BrandenTap
мега онион мега сайт ссылка
Hilltob
how to access dark web deep web links
Torntow
darkmarket link darknet drug links
MichaelCox
darknet магазин зелья даркнет сайты магазин
HaroldImaby
the dark internet dark markets
Michaelhoise
dark market url dark web site
RichardCyday
deep web markets drug markets onion
Smittjen
deep web sites darkweb marketplace
Jamesopike
deep web links dark web search engines
DanielEncon
dark web drug marketplace dark websites
EdgarFar
магазин мега мега onion
RandyZenny
dark web websites how to access dark web
RobertGic
dark web sites links tor markets 2022
Randylog
darknet search engine dark market link
Charlesjerce
deep dark web darknet drugs
JasonRab
dark web link dark web websites
CrisUnano
darknet market dark web market links
MichaelSware
мега onion ссылка мега onion оффициальный сайт
Dannymycle
tor market url dark website
ADangep
dark web market list darknet sites
Mattheworali
darkmarket dark web drug marketplace
CharlesGet
darknet drugs deep web links
DavidMob
darknet drug links darkmarket url
WilliamQuego
dark markets 2022 tor market url
Granthub
best darknet markets drug markets onion
JamesVet
deep web links dark web search engines
Ronaldimpak
darknet links dark web sites
Jancib
dark market onion dark internet
Donaldrhisp
dark web market links darkmarkets
RalphusafT
deep web search darknet links
JosephBok
dark market 2022 darkmarket url
BrandonTor
dark market url tor market
Juliusbop
dark market 2022 darknet drugs
Geraldnob
deep dark web free dark web
Hansmog
tor market links darknet drug links
Sirtob
dark website blackweb
WilliamBlade
how to get on dark web darkmarket url
ShaneLit
deep web links darknet drug links
HectorMug
мега нарко мега онион
Jackiesix
ссылка мега мега официальный сайт
Richardkeymn
мега купить соль mega онион сайт
Davidmab
darkmarket list dark market
PatrickDuelp
deep web drug store dark market onion
CorryBoura
dark market 2022 deep web links
Zacharyhet
darkmarket how to access dark web
Justinfluff
dark market list dark markets
BrianBen
tor market links dark web market
Robertket
новое зеркало мега ссылка мега
CraigFaf
tor markets links darknet marketplace
GeorgeThuth
deep dark web darkmarket 2022
Jamesgox
blackweb dark web drug marketplace
BrandenTap
mega onion зеркало мега мефедрон
SteveNek
ссылка на мегу mega ссылка
HellySAr
free dark web dark website
DamonPoday
dark net dark web site
Williamreoft
tor market links deep dark web
Torntow
dark web link dark market
HaroldImaby
dark web market darknet sites
MichaelCox
мега купить соль mega onion зеркало
RichardCyday
dark market link darknet market links
Smittjen
deep web drug url dark markets
Jamesopike
dark web sites links tor market
DanielEncon
dark web market dark web sites
RandyZenny
tor markets links dark web search engines
RobertGic
darknet sites dark web sites links
Timmylurry
dark market 2022 tor market links
Randylog
deep web drug links dark markets
Charlesjerce
deep web sites darknet markets
Julianacunc
dark market 2022 dark websites
ADangep
deep web drug store darknet market
MichaelSware
даркнет сайты магазин mega онион
CrisUnano
darknet drugs darknet sites
DavidMob
deep web sites blackweb
Mattheworali
dark web sites links dark market 2022
JasonRab
dark market list darknet market list
CharlesGet
dark web sites dark market list
Granthub
dark markets 2022 dark net
WilliamQuego
dark markets 2022 darkmarket link
Ronaldimpak
dark market onion darknet search engine
JamesVet
darknet drug links darkmarket url
RalphusafT
darkmarket 2022 onion market
Jancib
darknet websites dark web access
Donaldrhisp
darknet seiten deep web markets
JosephBok
darknet market links blackweb
BrandonTor
darknet drug links dark web access
Juliusbop
deep web links darknet search engine
Hansmog
dark markets tor markets 2022
HectorMug
мега onion магазин мега onion ссылка
Richardkeymn
мега зеркало darknet магазин зелья
Jackiesix
мега шишки mega магазин
Geraldnob
tor market tor marketplace
ShaneLit
drug markets onion deep web search
Frankcit
darknet drug market dark web search engine
Justinfluff
dark web drug marketplace dark web market
CorryBoura
deep web sites darknet drug links
DavidSig
dark market 2022 best darknet markets
Davidmab
tor market url dark web markets
Zacharyhet
darkweb marketplace dark net
WendellEnaky
darknet market deep web markets
BrandenTap
мега сайт ссылка даркнет магазин
SteveNek
мега зеркало мега купить
GeorgeThuth
dark web sites links darknet markets
CraigFaf
darknet site deep web drug markets
Robertket
mega онион сайт мега нарко
Jamesgox
darknet websites darkmarket url
BrianBen
tor market url dark market 2022
HellySAr
deep web links drug markets onion
Torntow
dark web sites darkweb marketplace
DamonPoday
dark web drug marketplace dark web sites links
Michaelhoise
darknet site deep web search
HaroldImaby
deep web drug links darknet drug market
RichardCyday
darknet search engine dark web search engine
Smittjen
darknet drug store onion market
MichaelCox
мега нарко мега onion оффициальный сайт
Williamreoft
dark web websites darknet drug links
Jamesopike
deep web links drug markets onion
DanielEncon
dark net deep web drug store
RobertGic
tor markets 2022 deep web markets
RandyZenny
the dark internet darknet market
Timmylurry
dark web search engines deep web drug links
Hilltob
darkmarket list dark web drug marketplace
Charlesjerce
dark web drug marketplace dark websites
Randylog
darkweb marketplace darkmarket link
EdgarFar
зайти на мегу мега вход
ADangep
darknet market list dark market 2022
MichaelSware
мега купить mega онион сайт
CrisUnano
darkmarket link drug markets onion
DavidMob
dark web sites darkmarket url
Mattheworali
deep web drug links darkmarket url
CharlesGet
dark web market tor darknet
JasonRab
dark market list dark web search engine
Dannymycle
dark website dark web site
Granthub
black internet deep web search
WilliamQuego
dark websites dark web market
Ronaldimpak
dark net dark market link
JamesVet
dark market url darknet sites
RalphusafT
dark web market list darknet marketplace
Sirtob
dark web sites dark internet
WilliamBlade
darkmarket url dark web link
Jancib
dark markets drug markets onion
Donaldrhisp
dark website darknet market
JosephBok
free dark web dark web sites
HectorMug
мега официальный сайт мега onion магазин
Richardkeymn
ссылки на даркнет сайт мега
Jackiesix
мега магазин мега нарко
Juliusbop
deep web drug markets darknet drug links
Hansmog
tor dark web darknet market lists
ShaneLit
darknet search engine deep web drug store
PatrickDuelp
darkmarket 2022 darknet drug store
Geraldnob
darknet marketplace darknet drugs
SteveNek
даркнет сайты магазин ьупф ьфклуе
BrandenTap
мега шишки mega onion оффициальный сайт
Frankcit
dark web sites links deep dark web
Zacharyhet
darknet drug links dark markets
Justinfluff
darknet drug links dark web drug marketplace
WendellEnaky
dark web markets dark web site
DavidSig
how to access dark web darkmarkets
CorryBoura
drug markets onion tor markets
GeorgeThuth
darknet websites deep web links
CraigFaf
darknet drug market tor market
Robertket
ьупф ьфклуе mega onion зеркала
Jamesgox
darknet market deep web drug links
BrianBen
dark web search engine tor marketplace
HellySAr
darknet drugs deep web drug markets
Michaelhoise
deep web search deep web drug links
Torntow
dark web drug marketplace deep web drug store
RichardCyday
dark markets 2022 blackweb official website
DamonPoday
dark website the dark internet
Smittjen
best darknet markets drug markets dark web
HaroldImaby
deep dark web darknet market lists
MichaelCox
darknet сайт зайти на мегу
Jamesopike
dark net tor market links
Williamreoft
dark market list tor markets links
DanielEncon
darknet seiten dark web market links
RobertGic
dark web sites deep web drug markets
RandyZenny
dark net the dark internet
Timmylurry
darkmarket deep web drug url
Charlesjerce
dark markets 2022 dark web search engines
Randylog
how to access dark web tor marketplace
MichaelSware
сайты даркнет сайты даркнет
ADangep
dark websites deep web drug url
EdgarFar
мега сайт мега onion зеркало
DavidMob
deep web drug markets dark web search engines
CrisUnano
dark web link darknet market lists
Hilltob
darknet market links darknet links
CharlesGet
dark market url dark web sites
Julianacunc
dark website dark market onion
Dannymycle
tor marketplace dark web market
Jackiesix
mega онион сайт mega market
Richardkeymn
сылка на мегу мега магазин
HectorMug
магазин даркнет магазин мега
Granthub
darknet sites dark internet
WilliamBlade
dark internet dark web search engines
WilliamQuego
how to access dark web dark web access
Sirtob
deep web sites dark market link
Ronaldimpak
the dark internet darknet drug market
Donaldrhisp
darknet marketplace dark markets
RalphusafT
darknet drugs dark web search engine
JamesVet
deep web search dark web markets
JasonRab
onion market drug markets onion
Jancib
darkmarket url darknet drug store
JosephBok
blackweb official website darknet site
BrandonTor
dark web access darkmarket 2022
Juliusbop
darknet market links tor market url
Hansmog
dark web links dark net
BrandenTap
мега сайт ссылка сайт мега
SteveNek
darknet магазин как зайти на мегу
ShaneLit
dark markets 2022 tor markets links
PatrickDuelp
darknet drugs darkmarket link
Geraldnob
dark web market dark market url
Frankcit
darknet links dark web links
Justinfluff
darknet seiten drug markets dark web
Zacharyhet
darkmarket 2022 best darknet markets
WendellEnaky
darknet markets darknet drug store
DavidSig
darknet links blackweb
CorryBoura
black internet dark internet
GeorgeThuth
dark net darknet drugs
CraigFaf
dark web access blackweb official website
Robertket
мега мефедрон ссылка мега
Jamesgox
darknet websites dark internet
BrianBen
how to get on dark web drug markets onion
Michaelhoise
deep dark web bitcoin dark web
Torntow
drug markets dark web darknet drug store
HellySAr
best darknet markets dark market onion
Davidmab
deep web drug links blackweb official website
Smittjen
deep web drug store tor markets links
RichardCyday
dark web market links free dark web
HaroldImaby
darkmarket url darknet market list
MichaelCox
мега ссылка мега сайт ссылка
Jamesopike
tor markets the dark internet
DamonPoday
dark market darknet market
DanielEncon
darknet drug store deep web search
RandyZenny
darkmarket url tor market links
Charlesjerce
dark web market dark market
Timmylurry
how to access dark web dark market list
MichaelSware
даркнет магазин мега onion
ADangep
dark web search engine darknet seiten
Randylog
dark web link deep web drug links
Williamreoft
darknet drug market blackweb official website
EdgarFar
мега магазин зеркало мега
DavidMob
blackweb darkmarket link
Mattheworali
dark web sites best darknet markets
Richardkeymn
ссылка на мегу магазин мега
HectorMug
ссылка мега мега онион сайт
Jackiesix
сайт даркнет сылка на мегу
CharlesGet
tor market black internet
Sirtob
tor markets links deep dark web
WilliamBlade
free dark web darkmarket link
Granthub
darkmarket url tor markets 2022
Ronaldimpak
bitcoin dark web drug markets onion
WilliamQuego
darknet market links dark web links
Hilltob
blackweb dark websites
Donaldrhisp
deep web drug url darknet drugs
Julianacunc
dark websites darknet market lists
JamesVet
darkmarket link dark net
JasonRab
darknet marketplace drug markets dark web
JosephBok
dark net darknet site
BrandonTor
darknet market dark web site
Juliusbop
tor market url dark market list
BrandenTap
мега сайт ссылка мега onion зеркало
SteveNek
mega сайт мега onion оффициальный сайт
Hansmog
deep web markets black internet
ShaneLit
black internet darknet market links
PatrickDuelp
darknet websites deep dark web
Zacharyhet
dark market list onion market
Frankcit
the dark internet bitcoin dark web
Justinfluff
dark websites darknet markets
WendellEnaky
darkweb marketplace dark markets
DavidSig
bitcoin dark web tor darknet
Geraldnob
darkmarkets tor markets
CorryBoura
darknet drug market darknet websites
Robertket
мега onion сайт мега
Michaelhoise
darknet drug links darkmarket list
CraigFaf
darkmarkets deep web markets
BrianBen
dark markets dark web markets
HellySAr
blackweb official website deep web drug url
Smittjen
tor market links dark market url
Davidmab
deep web sites deep web drug markets
RichardCyday
dark market 2022 dark web access
HaroldImaby
dark market url dark web market
Jamesopike
dark market 2022 dark market list
MichaelCox
darknet сайт официальный сайт мега
DamonPoday
tor dark web darknet market
DanielEncon
darknet market drug markets dark web
RandyZenny
how to get on dark web darkmarket link
Charlesjerce
darknet websites darknet seiten
RobertGic
tor markets links darknet markets
Timmylurry
dark web markets darknet drug store
MichaelSware
мега onion оффициальный сайт даркнет ссылки
HectorMug
сайты даркнет мега купить
Richardkeymn
мега вход ссылка мега
EdgarFar
мега онион сайты даркнет ссылки
Jackiesix
даркнет магазин мега onion ссылка
Williamreoft
darknet market links darknet site
WilliamBlade
dark websites darknet drug market
Sirtob
darknet seiten tor market
Mattheworali
deep web sites dark web search engines
CharlesGet
dark web search engine dark website
Granthub
darknet drug market darkmarket 2022
Dannymycle
dark web market links onion market
Ronaldimpak
dark web site dark web sites links
Donaldrhisp
dark websites dark web market links
WilliamQuego
darknet sites dark net
RalphusafT
dark market url the dark internet
JamesVet
how to access dark web darknet market links
JasonRab
dark web site dark web sites links
JosephBok
onion market darknet market list
SteveNek
мега кокаин даркнет магазин
BrandenTap
ьупф ьфклуе мега сайт ссылка
Julianacunc
dark market onion dark web sites
BrandonTor
darkmarket list blackweb official website
Juliusbop
best darknet markets darknet seiten
Hilltob
dark market link darknet drugs
Hansmog
deep dark web darknet market lists
ShaneLit
deep web drug links dark web markets
PatrickDuelp
darknet search engine deep web sites
Zacharyhet
dark web search engines dark web markets
Frankcit
darknet market tor dark web
Justinfluff
dark web sites darknet market
WendellEnaky
tor markets deep web drug markets
DavidSig
best darknet markets dark web markets
GeorgeThuth
dark market list darkmarkets
CorryBoura
darknet drugs blackweb
Michaelhoise
drug markets onion darkmarket link
ADangep
darkmarket list tor dark web
BrianBen
dark web markets dark web site
CraigFaf
tor dark web tor market url
Geraldnob
onion market drug markets onion
Robertket
mega onion ссылка мега шишки
Jamesgox
darknet drugs darknet seiten
Smittjen
darknet market links dark markets 2022
HaroldImaby
tor markets links darknet drugs
Davidmab
deep web drug links darkmarket link
Jamesopike
tor markets 2022 tor darknet
MichaelCox
зайти на мегу зеркало мега
DanielEncon
dark web link dark web market list
Charlesjerce
how to access dark web deep web drug url
RandyZenny
darknet links darkmarket url
RobertGic
how to access dark web darkmarket 2022
MichaelSware
мега onion магазин официальный сайт мега
Timmylurry
dark markets dark web access
Richardkeymn
mega onion зеркало мега onion
HectorMug
mega market mega ссылка
DamonPoday
tor marketplace dark web websites
Randylog
darknet sites how to get on dark web
DavidMob
dark market onion dark web market list
WilliamBlade
tor darknet blackweb official website
Sirtob
dark web sites darkweb marketplace
EdgarFar
сайт мега даркнет сайты магазин
Mattheworali
the dark internet the dark internet
Jackiesix
мега сайт мега onion
CharlesGet
dark web search engines black internet
Williamreoft
tor marketplace dark web sites links
Granthub
how to get on dark web dark web link
Donaldrhisp
tor market links dark market 2022
BrandenTap
mega onion оффициальный сайт мега onion зеркало
Dannymycle
darknet search engine dark market onion
SteveNek
mega даркнет mega даркнет
WilliamQuego
dark web market links darknet drug store
RalphusafT
drug markets onion deep web drug store
JamesVet
deep web drug links dark internet
JasonRab
dark web drug marketplace best darknet markets
JosephBok
tor marketplace onion market
BrandonTor
darknet search engine dark web link
Juliusbop
deep web drug url deep web drug markets
Hansmog
deep web search dark web drug marketplace
Julianacunc
tor darknet best darknet markets
ShaneLit
darkmarket list dark market url
PatrickDuelp
dark web search engine best darknet markets
Zacharyhet
dark web access deep web drug markets
Frankcit
deep web search deep web drug links
Hilltob
dark web search engines dark web search engine
Justinfluff
dark market url dark websites
WendellEnaky
tor darknet dark market 2022
DavidSig
tor market dark web access
CorryBoura
drug markets onion darknet marketplace
GeorgeThuth
drug markets onion tor markets links
Michaelhoise
the dark internet bitcoin dark web
BrianBen
deep web drug url tor markets links
Robertket
мега кокаин мега нарко
ADangep
dark web market list dark web site
CraigFaf
darknet seiten dark web search engine
Jamesgox
free dark web tor markets
Geraldnob
dark web sites tor marketplace
HellySAr
darkmarket link dark website
Smittjen
dark web websites darknet search engine
RichardCyday
darkmarket 2022 dark market 2022
HaroldImaby
deep web drug url deep web drug markets
Jamesopike
dark web sites tor market url
DanielEncon
dark markets dark web market links
MichaelCox
магазин мега мега наркотики
Charlesjerce
darknet sites dark web market list
HectorMug
мега наркотики мега зеркало
RandyZenny
dark web access darknet drug links
Richardkeymn
даркнет магазин мега onion зеркало
MichaelSware
даркнет ссылки новое зеркало мега
Timmylurry
tor market dark market
WilliamBlade
tor market dark web markets
DavidMob
darknet drug store darknet seiten
Sirtob
tor marketplace dark websites
Randylog
deep web drug links darknet links
DamonPoday
tor marketplace dark web access
Mattheworali
darknet site dark web drug marketplace
EdgarFar
сайт мега сылка на мегу
Jackiesix
mega onion оффициальный сайт сайт мега
BrandenTap
сайты даркнет магазины даркнета
SteveNek
мега ссылка мега кокаин
CharlesGet
darkmarket dark web market
Donaldrhisp
how to access dark web dark website
Ronaldimpak
darknet links tor market
CrisUnano
dark market onion dark web access
Jancib
dark website dark web site
JamesVet
dark market list deep web drug url
BrandonTor
darknet site best darknet markets
Dannymycle
darknet site dark market url
Hansmog
dark market onion deep web drug markets
ShaneLit
deep web drug links tor darknet
PatrickDuelp
blackweb official website darkmarket list
Julianacunc
deep web drug links dark market link
Zacharyhet
drug markets onion dark market onion
Frankcit
tor market best darknet markets
WendellEnaky
best darknet markets drug markets dark web
CorryBoura
darkweb marketplace dark web search engines
GeorgeThuth
deep dark web dark web drug marketplace
DavidSig
tor market dark web market
BrianBen
deep dark web tor darknet
CraigFaf
darkmarket url darknet links
Jamesgox
tor market links dark market list
ADangep
dark web market links dark web market list
Smittjen
dark net drug markets dark web
HellySAr
darkmarkets darknet drug store
RichardCyday
tor market darknet drug store
Geraldnob
dark web site darknet site
Jamesopike
darknet links dark web search engine
HaroldImaby
drug markets onion dark net
HectorMug
мега наркотики магазин мега https://hydramarket-online.link/ - мега onion магазин
Richardkeymn
мега onion зеркало мега онион https://hydramarket-darknet.link/ - mega магазин
MichaelSware
ссылка на мегу сайты даркнет ссылки https://hydramarketdarknet.link/ - mega onion ссылка
DanielEncon
dark internet dark web drug marketplace
DavidMob
drug markets onion darkmarket list
Sirtob
darknet market lists free dark web
Charlesjerce
how to get on dark web tor dark web
MichaelCox
mega onion зеркала новое зеркало мега https://hydramarket-darknet.link/ - mega даркнет
Timmylurry
dark websites dark markets
WilliamBlade
darknet market list how to access dark web
Randylog
dark internet dark web market list
Jackiesix
мега нарко даркнет ссылки https://hydramarketdarknet.link/ - мега онион
Mattheworali
dark web link tor markets
DamonPoday
dark web search engine deep web drug url
BrandenTap
мега зеркало мега мефедрон https://hydra-market-onion.link/ - ссылка на мегу
SteveNek
мега вход зеркало мега https://hydramarketdarkweb.link/ - сайт мега
EdgarFar
mega сайт зеркало мега https://hydramarket-darkweb.link/ - мега сайт ссылка
Jancib
tor markets 2022 dark web market list
Torntow
how to get on dark web how to get on dark web
CharlesGet
blackweb darknet market lists
CrisUnano
dark market deep web sites
Donaldrhisp
dark web sites links dark website
Granthub
best darknet markets blackweb
RalphusafT
dark web links tor dark web
WilliamQuego
free dark web dark web markets
JamesVet
darknet drugs dark market url
JosephBok
deep web drug url dark market url
JasonRab
darknet markets darknet drugs
BrandonTor
tor markets 2022 the dark internet
Juliusbop
darkmarket darkmarket url
Dannymycle
dark market onion dark net
Hansmog
darknet markets darknet site
ShaneLit
darknet market dark websites
PatrickDuelp
dark web markets dark market
Frankcit
deep web drug url tor markets links
Justinfluff
best darknet markets tor markets links
Zacharyhet
how to get on dark web darkmarket list
WendellEnaky
dark web link dark web market
CorryBoura
darknet drug store tor market
GeorgeThuth
dark markets 2022 deep dark web
Michaelhoise
blackweb dark market link
DavidSig
dark web sites how to access dark web
Robertket
сайт мега сайты даркнет ссылки https://hydramarket-online.link/ - мега купить
Jamesgox
darknet search engine blackweb official website
ADangep
darknet markets dark market url
Smittjen
blackweb official website darkmarket url
RichardCyday
darknet drug market darknet links
HellySAr
dark web websites darknet seiten
Geraldnob
dark web link darknet sites
Richardkeymn
мега onion оффициальный сайт мега зеркало https://hydra-market-onion.link/ - mega ссылка
HectorMug
мега onion зеркало даркнет ссылки https://hydramarket-darkweb.link/ - зеркало мега
Jamesopike
darknet links darknet market links
DavidMob
dark web market list tor dark web
Sirtob
blackweb official website deep web drug url
MichaelSware
сайты даркнет мега onion https://hydramarketdarknet.link/ - мега ссылка
DanielEncon
the dark internet tor markets 2022
Charlesjerce
dark internet darknet drug links
RandyZenny
dark market dark market list
MichaelCox
mega onion зеркала зайти на мегу https://hydramarket-darknet.link/ - как зайти на мегу
WilliamBlade
darknet sites best darknet markets
RobertGic
dark web market list blackweb official website
Timmylurry
darknet market links drug markets dark web
Davidmab
darknet drug market darknet marketplace
Williamreoft
darknet market lists dark web search engines
Hilltob
tor darknet dark web market links
Jancib
bitcoin dark web how to get on dark web
Torntow
onion market darknet search engine
BrandenTap
магазин мега ьупф ьфклуе https://hydra-market-onion.link/ - сайт мега
SteveNek
darknet магазин зелья сайт мега https://hydramarketdarkweb.link/ - мега onion ссылка
Jackiesix
mega онион сайт даркнет сайты магазин https://hydramarketdarknet.link/ - мега onion зеркала
Mattheworali
darknet websites best darknet markets
Randylog
deep web drug store darknet market lists
CharlesGet
dark market link deep dark web
EdgarFar
мега ссылка mega market https://hydramarket-darkweb.link/ - даркнет сайты магазин
Ronaldimpak
tor market darkmarket link
CrisUnano
darknet websites darkmarkets
Donaldrhisp
blackweb tor darknet
Granthub
dark net bitcoin dark web
RalphusafT
darknet websites how to access dark web
WilliamQuego
darkmarket link deep web links
JamesVet
how to get on dark web deep web drug markets
JosephBok
blackweb deep web drug store
BrandonTor
darkmarket url dark internet
Juliusbop
onion market dark market onion
JasonRab
darkweb marketplace dark websites
Hansmog
best darknet markets tor markets 2022
ShaneLit
tor market dark web site
Frankcit
tor markets darknet market links
Justinfluff
dark market url dark websites
WendellEnaky
free dark web darkmarket 2022
Zacharyhet
blackweb official website deep web search
CorryBoura
darkmarket blackweb
Julianacunc
dark web search engines tor market url
Michaelhoise
darknet market links onion market
BrianBen
onion market black internet
DavidSig
dark website dark web markets
GeorgeThuth
deep dark web deep dark web
CraigFaf
deep web search dark web sites links
Robertket
mega onion зеркало mega onion оффициальный сайт https://hydramarket-online.link/ - darknet магазин зелья
Jamesgox
dark web sites links darknet search engine
ADangep
deep web links darkmarkets
Smittjen
dark market link darknet websites
RichardCyday
dark web links darknet sites
Richardkeymn
ьупф ьфклуе ссылка на мегу https://hydramarket-darknet.link/ - mega магазин
HectorMug
mega онион mega market https://hydramarket-darkweb.link/ - мега онион сайт
HellySAr
darknet drug links darknet market
Sirtob
dark market 2022 bitcoin dark web
DavidMob
dark web link dark market onion
Jamesopike
deep web drug url darknet drug store
MichaelSware
мега купить соль мега вход https://hydramarketdarknet.link/ - mega онион
HaroldImaby
tor darknet dark markets
DanielEncon
darknet drug store tor market
Geraldnob
darknet drugs tor darknet
Charlesjerce
tor markets links dark web sites links
RandyZenny
dark websites tor market url
WilliamBlade
darknet links dark market
Davidmab
deep web drug url dark web link
Williamreoft
dark web access darknet sites
RobertGic
deep web drug url blackweb
MichaelCox
мега мефедрон мега сайт ссылка https://hydramarket-darknet.link/ - сайт мега
BrandenTap
мега даркнет сайт даркнет https://hydra-market-onion.link/ - мега онион сайт
SteveNek
mega сайт mega onion shop https://hydramarketdarkweb.link/ - мега наркотики
Jancib
darkweb marketplace how to access dark web
Torntow
best darknet markets darknet site
Hilltob
tor market darkmarket link
Timmylurry
darknet search engine dark markets 2022
Mattheworali
dark web search engine dark market
CharlesGet
darknet marketplace deep web links
Randylog
black internet darknet drug market
Ronaldimpak
dark web sites links tor markets
EdgarFar
магазин даркнет ссылка на мегу https://hydramarket-darkweb.link/ - мега onion зеркала
Donaldrhisp
dark websites blackweb
CrisUnano
darkmarket link dark web sites links
Jackiesix
мэги сайт мега onion https://hydramarketdarknet.link/ - сайты даркнет ссылки
Granthub
tor darknet darkmarket 2022
WilliamQuego
tor markets dark web market
RalphusafT
darknet market links drug markets dark web
JosephBok
darknet seiten dark web site
DamonPoday
drug markets onion tor market links
JamesVet
dark web sites links tor darknet
BrandonTor
drug markets dark web darkmarket url
JasonRab
how to access dark web dark web market list
Juliusbop
dark web market links deep dark web
Dannymycle
dark web links darkmarket
Hansmog
tor markets darkmarket list
ShaneLit
dark web sites tor marketplace
PatrickDuelp
darkmarket 2022 drug markets dark web
Frankcit
deep web drug url deep web sites
CorryBoura
dark markets darkmarkets
WendellEnaky
tor markets links dark websites
Zacharyhet
darknet market list dark web site
BrianBen
dark web sites links dark web drug marketplace
Michaelhoise
dark markets 2022 darknet markets
DavidSig
drug markets dark web bitcoin dark web
GeorgeThuth
blackweb official website tor markets
Jamesgox
darknet sites dark web link
Julianacunc
dark market list deep web markets
Smittjen
dark web sites dark market list
ADangep
dark web drug marketplace dark web market
Richardkeymn
ссылка мега зайти на мегу https://hydramarket-darknet.link/ - мега кокаин
HectorMug
магазин даркнет мега сайт https://hydramarket-darkweb.link/ - магазины даркнета
DavidMob
darknet search engine deep web drug store
Sirtob
deep web drug links darknet drug store
RichardCyday
tor markets links blackweb
HellySAr
darknet search engine deep web search
CraigFaf
best darknet markets dark web markets
Jamesopike
darkmarkets darknet drug store
MichaelSware
сылка на мегу мега нарко https://hydramarketdarknet.link/ - мега onion
DanielEncon
the dark internet deep web links
HaroldImaby
deep web drug markets deep web sites
Charlesjerce
dark market onion blackweb official website
RandyZenny
darkmarkets darknet markets
Geraldnob
darknet drug store darknet links
WilliamBlade
darknet drug store deep web markets
RobertGic
darknet drug market deep web search
Williamreoft
dark market list dark web market list
Davidmab
darkweb marketplace free dark web
SteveNek
мега скорость мега шишки https://hydramarketdarkweb.link/ - мега onion зеркало
BrandenTap
мега сайт мега onion оффициальный сайт https://hydra-market-onion.link/ - мега onion зеркала
MichaelCox
как зайти на мегу мега онион https://hydramarket-darknet.link/ - мега онион сайт
Jancib
tor market url dark market list
Torntow
dark web sites links black internet
Timmylurry
the dark internet darknet sites
Mattheworali
blackweb black internet
Randylog
darkmarket url tor markets 2022
CharlesGet
darkmarket url tor market
Hilltob
darknet market tor markets links
Ronaldimpak
deep web drug markets darknet seiten
Jackiesix
даркнет магазин мэги сайт https://hydramarketdarknet.link/ - мега мефедрон
EdgarFar
mega onion shop мега нарко https://hydramarket-darkweb.link/ - мега наркотики
Donaldrhisp
tor darknet tor darknet
Granthub
deep web drug store deep web markets
RalphusafT
dark web markets deep web drug store
WilliamQuego
dark market link deep web markets
CrisUnano
drug markets dark web dark markets 2022
JamesVet
darknet drugs darknet marketplace
JosephBok
darknet sites dark web site
DamonPoday
blackweb official website dark net
JasonRab
dark web market list best darknet markets
Juliusbop
tor markets links tor market
Dannymycle
deep web markets dark market link
ShaneLit
dark market onion dark web sites
Hansmog
onion market best darknet markets
Frankcit
tor markets 2022 best darknet markets
CorryBoura
darknet market links dark web market list
Justinfluff
darknet drug links dark web sites
WendellEnaky
dark net deep web drug links
Zacharyhet
blackweb official website dark market onion
BrianBen
darkmarket blackweb
Michaelhoise
darknet search engine darknet search engine
DavidSig
dark web market list dark market 2022
GeorgeThuth
darknet websites darknet sites
HectorMug
магазин мега магазин даркнет https://hydramarket-darkweb.link/ - мега onion зеркала
Richardkeymn
мега сайт сылка на мегу https://hydramarket-darknet.link/ - мэги сайт
Jamesgox
darknet search engine dark web search engines
Robertket
mega onion зеркала мега onion оффициальный сайт https://hydramarket-online.link/ - mega онион сайт
DavidMob
dark web websites deep web links
Sirtob
tor markets 2022 darknet drug links
Smittjen
tor markets dark web site
Julianacunc
free dark web deep dark web
ADangep
dark web market dark websites
RichardCyday
blackweb deep web drug links
HellySAr
dark internet tor market url
CraigFaf
darkmarket url darkmarket list
MichaelSware
мега скорость новое зеркало мега https://hydramarketdarknet.link/ - ссылки на даркнет
Jamesopike
dark web search engine tor market
DanielEncon
dark internet dark web websites
HaroldImaby
darkmarket url darknet links
Charlesjerce
dark market list darkmarket link
RandyZenny
deep web drug markets dark market url
BrandenTap
новое зеркало мега mega даркнет https://hydra-market-onion.link/ - новое зеркало мега
WilliamBlade
how to access dark web dark web markets
SteveNek
ссылка на мегу мега ссылка https://hydramarketdarkweb.link/ - магазин даркнет
RobertGic
dark web websites dark websites
Davidmab
onion market darknet drug links
Williamreoft
dark markets dark market list
MichaelCox
mega onion ссылка mega onion зеркала https://hydramarket-darknet.link/ - как зайти на мегу
Geraldnob
bitcoin dark web dark markets 2022
Jancib
deep web drug url dark market onion
Timmylurry
black internet tor darknet
Torntow
deep web links dark market url
CharlesGet
dark web market list darkweb marketplace
Jackiesix
сайты даркнет ссылки мега онион https://hydramarketdarknet.link/ - зеркало мега
Ronaldimpak
dark web websites dark web access
Granthub
the dark internet tor market url
Hilltob
dark market onion best darknet markets
RalphusafT
deep web drug markets onion market
WilliamQuego
bitcoin dark web darkmarket list
JamesVet
darkmarket 2022 deep web drug links
JosephBok
darknet market how to access dark web
CrisUnano
darkmarket list dark web search engines
BrandonTor
free dark web dark market
JasonRab
drug markets dark web darknet site
Juliusbop
dark market url dark web link
DamonPoday
darkmarket url darkmarket 2022
ShaneLit
dark web market list dark website
Hansmog
dark web link dark market 2022
PatrickDuelp
blackweb official website tor markets 2022
Frankcit
tor markets deep web drug url
CorryBoura
darknet marketplace darknet market links
Justinfluff
dark market tor dark web
WendellEnaky
deep web search darknet marketplace
HectorMug
mega онион мега onion ссылка https://hydramarket-online.link/ - даркнет сайты магазин
Richardkeymn
мега сайт ссылка mega market https://hydramarket-darknet.link/ - мега onion магазин
Michaelhoise
dark web site dark web search engine
GeorgeThuth
darknet websites darkmarket 2022
DavidMob
dark web market darkmarket url
Sirtob
deep web markets darkmarkets
DavidSig
darkmarket url darknet site
Jamesgox
deep web search deep dark web
Robertket
мега зеркало mega даркнет https://hydramarket-online.link/ - мега onion
Smittjen
bitcoin dark web dark market link
Randylog
dark web market links the dark internet
ADangep
darknet seiten blackweb
RichardCyday
deep web drug links dark web search engine
Julianacunc
darkmarket url how to get on dark web
MichaelSware
mega магазин магазин мега https://hydramarketdarknet.link/ - мега зеркало
CraigFaf
darknet drug market dark websites
HellySAr
dark market link darknet site
Jamesopike
darknet site how to access dark web
DanielEncon
darkmarkets drug markets dark web
Charlesjerce
tor marketplace dark web search engines
HaroldImaby
dark market onion dark market list
BrandenTap
мега официальный сайт сылка на мегу https://hydra-market-onion.link/ - ьупф ьфклуе
SteveNek
мега наркотики даркнет ссылки https://hydramarketdarkweb.link/ - даркнет магазин
RandyZenny
dark market 2022 tor darknet
WilliamBlade
dark web market links tor markets 2022
Dannymycle
dark web site deep web sites
RobertGic
deep web search darknet seiten
Williamreoft
dark web search engine darknet drug links
Davidmab
deep web drug markets deep web search
MichaelCox
мега шишки mega магазин https://hydramarket-darknet.link/ - мега даркнет
Torntow
dark web drug marketplace dark web market
Timmylurry
dark market darkmarkets
Geraldnob
dark market darknet search engine
Zacharyhet
tor markets tor marketplace
CharlesGet
how to get on dark web deep web drug store
Mattheworali
dark market onion darkmarket list
Jackiesix
mega onion мега онион https://hydramarketdarkweb.link/ - мега ссылка
Ronaldimpak
bitcoin dark web dark market 2022
Jancib
darkweb marketplace dark market list
Donaldrhisp
deep web drug markets deep dark web
Granthub
deep web drug links how to get on dark web
RalphusafT
dark website drug markets onion
WilliamQuego
darkmarket drug markets onion
EdgarFar
мега скорость даркнет магазин https://hydramarket-darkweb.link/ - ссылки на даркнет
JamesVet
deep web markets best darknet markets
JosephBok
dark web market list darknet markets
Hilltob
darknet drug market dark web markets
BrandonTor
tor dark web black internet
JasonRab
how to get on dark web darknet drug market
Juliusbop
dark web websites tor market
ShaneLit
darknet site deep web drug markets
DamonPoday
deep web search darknet market lists
Hansmog
deep web drug markets dark web drug marketplace
PatrickDuelp
tor market url dark web market
Frankcit
darkmarket free dark web
CorryBoura
darkmarkets darknet markets
Richardkeymn
мега даркнет darknet сайт https://hydramarket-darknet.link/ - darknet магазин зелья
HectorMug
mega ссылка darknet магазин зелья https://hydramarket-darkweb.link/ - мега onion оффициальный сайт
Justinfluff
tor marketplace dark web access
DavidMob
darkmarket deep web markets
Sirtob
darknet drug links free dark web
BrianBen
darknet site darknet drugs
WendellEnaky
darknet drugs dark market 2022
Michaelhoise
dark web websites dark web market list
GeorgeThuth
darknet drugs darknet websites
DavidSig
bitcoin dark web tor dark web
Jamesgox
darknet websites tor market url
Robertket
зайти на мегу даркнет магазин https://hydramarket-online.link/ - mega onion ссылка
Smittjen
deep web sites darknet websites
Randylog
tor dark web darknet site
ADangep
darknet market links tor market
RichardCyday
dark web links blackweb official website
MichaelSware
мега onion мега купить соль https://hydramarketdarknet.link/ - мега зеркало
CraigFaf
darkmarket 2022 deep dark web
HellySAr
dark market link dark web market list
BrandenTap
мэги сайт mega онион https://hydra-market-onion.link/ - mega onion ссылка
SteveNek
мега ссылка мега онион сайт https://hydramarketdarkweb.link/ - мега мефедрон
Charlesjerce
blackweb official website darkmarket 2022
DanielEncon
tor darknet deep web sites
HaroldImaby
darknet market links dark web link
RobertGic
best darknet markets dark web markets
Dannymycle
best darknet markets dark web access
MichaelCox
мега даркнет даркнет магазин https://hydramarket-darknet.link/ - мега onion
Timmylurry
drug markets dark web tor market url
Torntow
dark market link darknet markets
Jancib
dark market onion dark web link
WilliamQuego
dark web access free dark web
CrisUnano
dark net darknet marketplace
JosephBok
tor darknet darknet drug links
BrandonTor
dark web links darknet market links
Hilltob
dark market dark website
Juliusbop
dark market link drug markets dark web
Richardkeymn
зеркало мега магазин даркнет https://hydramarket-darknet.link/ - сайт даркнет
HectorMug
мега onion магазин мега onion магазин https://hydramarket-darkweb.link/ - mega onion
ShaneLit
deep web markets darknet websites
Hansmog
darkmarket link dark market 2022
PatrickDuelp
darkweb marketplace dark market
DavidMob
best darknet markets drug markets onion
Justinfluff
darknet markets dark web market list
DamonPoday
darknet sites tor market links
WendellEnaky
dark web link deep web drug links
BrianBen
tor market darknet search engine
Michaelhoise
the dark internet darkmarket
Sirtob
tor markets 2022 onion market
GeorgeThuth
deep dark web dark web sites
DavidSig
darknet market tor markets
Jamesgox
dark market 2022 darkmarket list
Robertket
мега сайт ссылка даркнет магазин https://hydramarket-online.link/ - мега мефедрон
Smittjen
deep web drug markets dark internet
RichardCyday
deep web search dark web drug marketplace
MichaelSware
сайты даркнет mega ссылка https://hydramarketdarknet.link/ - мега сайт ссылка
CraigFaf
darkmarket link darkmarket link
BrandenTap
mega onion ссылка мега сайт https://hydra-market-onion.link/ - мэги сайт
Jamesopike
onion market darkweb marketplace
BrandonTor
dark web market links tor market url
DanielEncon
darknet market drug markets dark web
WilliamBlade
dark web market tor market
RandyZenny
darkweb marketplace darknet drugs
SteveNek
мега onion магазин ьупф ьфклуе https://hydramarketdarkweb.link/ - mega зеркало
HaroldImaby
darkmarket dark websites
Julianacunc
deep web drug store dark web websites
Williamreoft
dark markets dark web market
Davidmab
the dark internet darknet market links
RobertGic
deep dark web dark web link
Timmylurry
dark market list dark web sites links
Torntow
dark web link dark web market
Jackiesix
мега онион ссылка мега https://hydramarketdarknet.link/ - мега onion
CharlesGet
deep web links darknet drug store
Mattheworali
darknet market list dark market url
Ronaldimpak
deep web markets deep web drug url
Donaldrhisp
darknet drug store dark website
Granthub
darkweb marketplace dark web drug marketplace
RalphusafT
dark market url dark web markets
Jancib
dark web market list tor dark web
Geraldnob
tor market links dark web site
WilliamQuego
darkmarket url darknet markets
EdgarFar
ссылки на даркнет мега зеркало https://hydramarket-darkweb.link/ - мега зеркало
CrisUnano
the dark internet dark market 2022
JosephBok
best darknet markets darknet websites
JasonRab
dark web sites dark web access
Juliusbop
dark market 2022 dark market url
Richardkeymn
сайт даркнет мэги сайт https://hydramarket-darknet.link/ - мега шишки
HectorMug
сылка на мегу мега официальный сайт https://hydramarket-darkweb.link/ - сайты даркнет ссылки
Hilltob
drug markets onion drug markets onion
ShaneLit
tor markets best darknet markets
Hansmog
dark markets 2022 bitcoin dark web
PatrickDuelp
tor markets links deep web drug markets
DavidMob
darkmarkets tor markets
Justinfluff
dark web search engine dark web search engine
WendellEnaky
free dark web dark web access
Michaelhoise
tor market url dark web link
DamonPoday
darknet search engine deep web search
Sirtob
dark web access darkweb marketplace
GeorgeThuth
darknet drug market darkmarket list
DavidSig
deep web search best darknet markets
Robertket
мега купить официальный сайт мега https://hydramarket-online.link/ - мега магазин
Smittjen
darknet market list darknet seiten
MichaelSware
мега мефедрон зеркало мега https://hydramarketdarknet.link/ - mega onion оффициальный сайт
RichardCyday
darknet drug store drug markets onion
CraigFaf
deep dark web blackweb official website
Jamesopike
darknet site tor darknet
BrandenTap
mega даркнет мега onion https://hydra-market-onion.link/ - ьупф ьфклуе
BrandonTor
dark market 2022 how to get on dark web
WilliamBlade
deep web drug store darkmarket link
RandyZenny
darknet market how to get on dark web
HaroldImaby
dark web link dark markets 2022
DanielEncon
darknet seiten darkmarket
SteveNek
мега наркотики мега onion зеркала https://hydramarketdarkweb.link/ - darknet магазин зелья
Julianacunc
darknet drugs how to get on dark web
Davidmab
darkmarket list dark web site
Williamreoft
drug markets onion dark website
RobertGic
darknet drug store dark web search engine
Timmylurry
dark markets 2022 darknet marketplace
Mattheworali
darknet markets onion market
Ronaldimpak
darknet drug links dark web markets
Granthub
bitcoin dark web darknet drug market
RalphusafT
darknet market lists best darknet markets
WilliamQuego
deep web drug url darknet markets
Jancib
dark net deep web links
Jackiesix
мега onion зеркала mega onion зеркала https://hydramarketdarknet.link/ - официальный сайт мега
Geraldnob
deep web drug markets deep web links
EdgarFar
мега мефедрон мега даркнет https://hydramarket-darkweb.link/ - мега onion зеркала
CrisUnano
darknet drug store dark web market list
JosephBok
drug markets onion darkmarket list
Arrissirl
Tips Suggestions <a href=https://cheapcialiss.com/>cialis daily</a> Physicians should discuss with patients the increased risk of NAION in individuals who have already experienced NAION in one eye
Richardkeymn
mega онион мега онион https://hydra-market-onion.link/ - мега официальный сайт
HectorMug
mega магазин mega даркнет https://hydramarket-online.link/ - зайти на мегу
JasonRab
tor marketplace dark web sites links
Juliusbop
blackweb official website darknet search engine
Hilltob
best darknet markets tor markets
ShaneLit
deep web drug markets tor market
Hansmog
darknet links how to get on dark web
PatrickDuelp
darknet market links darknet drug links
DavidMob
dark web drug marketplace blackweb
Justinfluff
darkmarkets tor marketplace
BrianBen
dark markets darknet market lists
WendellEnaky
dark market onion darkmarket
GeorgeThuth
tor market url deep web search
Sirtob
darknet market links deep web drug markets
DavidSig
dark web links dark markets 2022
DamonPoday
dark web sites links dark internet
Jamesgox
dark web sites how to get on dark web
Robertket
mega даркнет mega ссылка https://hydramarket-online.link/ - мега onion оффициальный сайт
Smittjen
dark web market list dark web search engine
MichaelSware
мега купить darknet сайт https://hydramarketdarknet.link/ - магазин мега
RichardCyday
darknet markets darknet marketplace
CraigFaf
dark net drug markets dark web
Jamesopike
dark markets 2022 deep web sites
BrandenTap
мега наркотики мега зеркало https://hydra-market-onion.link/ - сайты даркнет
WilliamBlade
darknet market list dark web websites
HaroldImaby
darknet search engine tor marketplace
RandyZenny
darknet drug store dark web search engines
BrandonTor
darkmarket url darknet market list
SteveNek
даркнет сайты магазин darknet магазин зелья https://hydramarketdarkweb.link/ - mega ссылка
Davidmab
darkweb marketplace dark web markets
Williamreoft
tor darknet deep dark web
Timmylurry
dark internet dark web sites
Torntow
tor markets 2022 dark internet
Julianacunc
dark web market list dark website
MichaelCox
мега onion магазин как зайти на мегу https://hydramarket-darknet.link/ - зеркало мега
CharlesGet
darknet links dark market list
Ronaldimpak
deep web drug url dark markets
Mattheworali
darknet drugs blackweb
Donaldrhisp
tor darknet tor marketplace
Granthub
darknet drugs dark market url
RalphusafT
darkmarket 2022 tor markets
WilliamQuego
darkmarket 2022 deep web drug store
Jackiesix
mega зеркало darknet магазин зелья https://hydramarketdarknet.link/ - мега официальный сайт
Jancib
dark market 2022 tor marketplace
JosephBok
darknet drug links deep web search
HectorMug
mega сайт мега шишки https://hydramarket-darkweb.link/ - новое зеркало мега
Richardkeymn
mega market сылка на мегу https://hydramarket-darknet.link/ - даркнет магазин
EdgarFar
новое зеркало мега зайти на мегу https://hydramarket-darkweb.link/ - mega сайт
CrisUnano
dark web market links drug markets onion
Geraldnob
dark net the dark internet
JasonRab
blackweb dark web search engines
ShaneLit
darknet drug market dark web market links
Juliusbop
dark web links darknet drug market
Hilltob
darkmarket 2022 darkmarket 2022
PatrickDuelp
darknet websites dark market onion
Hansmog
black internet dark market 2022
DavidMob
dark market url black internet
Justinfluff
darkmarket link tor markets 2022
BrianBen
tor marketplace darkmarket 2022
WendellEnaky
darknet site dark market link
Michaelhoise
dark net dark web sites links
GeorgeThuth
darknet search engine dark web links
Jamesgox
onion market darknet site
Sirtob
deep web search tor markets
Robertket
мега магазин новое зеркало мега https://hydramarket-online.link/ - mega onion ссылка
DavidSig
blackweb darkmarket 2022
DamonPoday
dark market link tor darknet
Smittjen
darknet drug store free dark web
RichardCyday
blackweb official website free dark web
CraigFaf
darknet market darkmarket 2022
Jamesopike
onion market tor dark web
WilliamBlade
deep web drug url free dark web
HaroldImaby
deep web drug markets free dark web
BrandenTap
мега официальный сайт mega onion зеркала https://hydra-market-onion.link/ - даркнет магазин
RandyZenny
dark market link best darknet markets
DanielEncon
darknet drug market dark web site
BrandonTor
dark website darkmarket url
SteveNek
mega onion ссылка mega onion https://hydramarketdarkweb.link/ - мега onion оффициальный сайт
Davidmab
deep web drug links deep web drug links
Williamreoft
darknet market darknet market lists
Timmylurry
the dark internet deep dark web
RobertGic
dark website darknet market links
MichaelCox
мега сайт ссылка на мегу https://hydramarket-darknet.link/ - новое зеркало мега
Julianacunc
how to access dark web dark web link
CharlesGet
tor dark web deep web drug links
Ronaldimpak
darknet market dark web market list
Donaldrhisp
bitcoin dark web onion market
Mattheworali
dark market url tor marketplace
RalphusafT
how to access dark web tor markets links
Granthub
dark web site bitcoin dark web
WilliamQuego
blackweb darknet sites
Jackiesix
зеркало мега новое зеркало мега https://hydramarketdarkweb.link/ - мега вход
HectorMug
сайт даркнет сайт даркнет https://hydramarket-online.link/ - мега купить
Richardkeymn
ссылка на мегу mega onion зеркала https://hydramarket-darknet.link/ - mega onion оффициальный сайт
Jancib
dark market onion dark web search engines
CrisUnano
deep web links darkmarket link
EdgarFar
мега onion магазин как зайти на мегу https://hydramarket-darkweb.link/ - магазин мега
JasonRab
darknet drugs dark market
Geraldnob
darknet search engine darknet drug store
ShaneLit
dark market url darknet market links
Juliusbop
bitcoin dark web dark web market list
Hansmog
dark web market darknet seiten
PatrickDuelp
how to access dark web darknet drug market
DavidMob
deep web sites darkweb marketplace
BrianBen
dark web sites links darknet drug market
Justinfluff
darkmarket link tor market links
Hilltob
dark web market dark market 2022
WendellEnaky
darknet websites tor markets links
Michaelhoise
darknet markets blackweb
GeorgeThuth
tor marketplace dark web market links
Robertket
ссылка на мегу мега onion магазин https://hydramarket-online.link/ - мега наркотики
DavidSig
darknet drug store darknet drug store
Smittjen
dark web search engines tor markets links
MichaelSware
мега onion зеркало зеркало мега https://hydramarketdarknet.link/ - мэги сайт
DamonPoday
tor market url dark market url
CraigFaf
dark web websites dark web websites
RichardCyday
dark web websites tor market url
Jamesopike
darknet sites dark web access
HaroldImaby
darknet search engine darknet site
RandyZenny
darknet market lists dark web access
BrandenTap
как зайти на мегу зайти на мегу https://hydra-market-onion.link/ - сайты даркнет ссылки
Davidmab
dark web site dark web site
Williamreoft
tor darknet tor dark web
SteveNek
darknet магазин mega ссылка https://hydramarketdarkweb.link/ - mega зеркало
Timmylurry
darknet market lists how to access dark web
Torntow
deep web drug links dark web markets
MichaelCox
мега сайт мега вход https://hydramarket-darknet.link/ - мега магазин
Ronaldimpak
darknet market lists darkmarket 2022
Donaldrhisp
darkweb marketplace how to get on dark web
Mattheworali
darkmarkets dark market 2022
RalphusafT
darknet market darkmarket
HectorMug
мега шишки мега ссылка https://hydramarket-online.link/ - ссылка на мегу
Jackiesix
mega онион сайт сылка на мегу https://hydramarketdarkweb.link/ - мега скорость
Granthub
dark web search engine darkmarket 2022
WilliamQuego
onion market deep web links
JosephBok
darknet sites darkmarket url
Richardkeymn
магазин даркнет ьупф ьфклуе https://hydramarket-darknet.link/ - darknet магазин
Jancib
darknet market dark market 2022
EdgarFar
официальный сайт мега мега onion зеркала https://hydramarket-darkweb.link/ - mega онион
JasonRab
deep web drug markets dark web links
ShaneLit
darknet market links dark web site
Juliusbop
deep web sites darkmarket 2022
Geraldnob
tor market url dark web access
DavidMob
darknet drugs darkmarket url
Hansmog
tor market darknet drugs
PatrickDuelp
darkmarket url dark market
BrianBen
dark web access tor markets links
Justinfluff
dark internet onion market
WendellEnaky
tor market url darknet site
Hilltob
deep web drug markets how to get on dark web
Michaelhoise
dark web markets free dark web
GeorgeThuth
deep web markets deep web drug store
Sirtob
drug markets dark web dark web links
Robertket
официальный сайт мега мега даркнет https://hydramarket-online.link/ - мега нарко
DavidSig
tor market url dark web market list
ADangep
deep web drug markets darkmarkets
MichaelSware
сайт даркнет мега onion https://hydramarketdarknet.link/ - мега зеркало
JamesVet
the dark internet darknet search engine
Frankcit
darknet sites deep web links
Charlesjerce
dark net darkweb marketplace
CorryBoura
darknet websites darknet search engine
Zacharyhet
darkmarket link deep web drug url
Dannymycle
darkmarket url darkweb marketplace
BrandonTor
blackweb onion market
Jamesgox
bitcoin dark web darkmarket link
Randylog
blackweb dark web search engines
RichardCyday
darknet site dark websites
CraigFaf
blackweb official website deep web markets
DamonPoday
black internet tor market links
Jamesopike
black internet dark market link
HaroldImaby
darknet websites dark web market links
DanielEncon
darkmarket deep web markets
RandyZenny
dark internet black internet
WilliamBlade
dark web access dark web access
BrandenTap
mega онион darknet сайт https://hydra-market-onion.link/ - mega market
Williamreoft
tor markets dark web links
Davidmab
how to access dark web dark web market
Timmylurry
deep web search darknet marketplace
SteveNek
мега купить соль mega онион сайт https://hydramarketdarkweb.link/ - мега onion
Torntow
dark web market list dark web websites
RobertGic
dark market dark web websites
CharlesGet
dark web market list dark web market list
Ronaldimpak
darknet market dark web sites
Donaldrhisp
dark market link deep web links
RalphusafT
darknet drug market darknet drugs
HectorMug
мега онион мега сайт ссылка https://hydramarket-online.link/ - mega ссылка
Jackiesix
зайти на мегу мега нарко https://hydramarketdarknet.link/ - мега onion зеркало
Mattheworali
darkmarket url drug markets onion
Michaelhoise
darknet market list dark web search engine
Granthub
tor marketplace best darknet markets
WilliamQuego
tor market url dark web market links
Julianacunc
tor market dark web market links
JosephBok
dark market link dark internet
Richardkeymn
магазины даркнета mega market https://hydramarket-darknet.link/ - mega онион
Jancib
tor market links dark web drug marketplace
CrisUnano
tor dark web darkmarket 2022
EdgarFar
mega онион mega onion зеркало https://hydramarket-darkweb.link/ - мега зеркало
JasonRab
dark market link free dark web
DavidMob
darknet market lists dark markets 2022
PatrickDuelp
darknet drug links darkmarket link
Geraldnob
deep dark web tor dark web
WendellEnaky
dark market url drug markets dark web
Frankcit
dark web link tor market
JamesVet
darkmarkets dark markets
Charlesjerce
tor market deep web markets
GeorgeThuth
dark market onion darkmarket url
Dannymycle
tor darknet deep dark web
Randylog
deep dark web darknet market list
Hilltob
dark web search engines darknet marketplace
Jamesgox
dark web link deep web links
BrandonTor
dark web sites links darknet websites
Zacharyhet
dark web access deep web drug store
Sirtob
darkmarket list darknet sites
Robertket
mega onion оффициальный сайт мега шишки https://hydramarket-online.link/ - mega онион сайт
MichaelSware
как зайти на мегу мега скорость https://hydramarketdarknet.link/ - мега onion зеркала
Smittjen
tor markets 2022 tor markets 2022
DavidSig
darkmarkets darkmarket list
CraigFaf
dark web drug marketplace blackweb
DamonPoday
dark web drug marketplace dark market link
RandyZenny
drug markets onion deep web sites
WilliamBlade
free dark web darknet websites
BrandenTap
mega онион сайт мега шишки https://hydra-market-onion.link/ - mega онион сайт
Davidmab
bohemia market cannahome market https://webdarknetmarkets.com/ - tor drugs
Timmylurry
tor market deep web drug url
Torntow
google black market dma drug https://wwwdarkmarket.shop/ - buying credit cards on dark web
RobertGic
tor markets 2022 tor dark web
SteveNek
сылка на мегу мега onion зеркало https://hydramarketdarkweb.link/ - мега нарко
CharlesGet
dark web store onion market https://darkweb-versus.com/ - red ferrari pills
HectorMug
мега купить соль mega магазин https://hydramarket-online.link/ - мега онион сайт
Jackiesix
мега онион мега шишки https://hydramarketdarkweb.link/ - сылка на мегу
Ronaldimpak
online black market electronics darknet market noobs https://asapmarketplace24.com/ - darknet drug markets 2022
Donaldrhisp
monero darknet markets deep web addresses onion https://versus-drugsonline.com/ - darknet drug market url
RalphusafT
tor top websites darknet market adderall prices https://asap-darkweb-drugstore.com/ - online black market uk
Mattheworali
darknet drug markets reddit underground dumps shop https://versusdarkwebmarkett.com/ - how to use deep web on pc
Granthub
asap link deep dot web replacement https://cannahomeoniondarkweb.com/ - black market credit card dumps
CorryBoura
darknet seiten liste dma drug https://wwwdarknetmarket.link/ - grey market darknet
HellySAr
how to use deep web on pc darknet new market link https://asap-darkmarket-online.com/ - shop on the dark web
ADangep
orange sunshine pill vice city market link https://aasap-market.com/ - google black market
WilliamQuego
link darknet market dream market darknet link https://asapdarkmarket.com/ - deep web deb
JosephBok
dark web site list bitcoin dark web https://dark-market-versus.com/ - dark markets netherlands
Julianacunc
darknet drugs germany lsd drug wiki https://aversus-market.com/ - nike jordan pill
Richardkeymn
mega онион сайт mega market https://hydramarket-darknet.link/ - мега сайт ссылка
Jancib
shop on the dark web decabol pills https://webdrugs-darknet.shop/ - tor websites reddit
Timmylurry
deep web markets best darknet markets for marijuana https://versus-darknet.com/ - dark markets macedonia
DavidSig
updated darknet market links 2022 anadrol pills https://versus-darkmarketplace.com/ - darknet drugs australia
Juliusbop
darknet markets most popular google black market https://versus-darkweb.com/ - what is a darknet drug market like
CrisUnano
dark net market best dark web search engine link https://wwwdarkmarket.link/ - darknet markets list 2022
EdgarFar
ссылка мега mega онион сайт https://hydramarket-darkweb.link/ - сылка на мегу
JasonRab
dark markets belarus working darknet markets https://versus-onion-darkmarket.com/ - top onion links
ShaneLit
darkfox market link archetyp market link https://asapmarket-linkk.com/ - best darknet market for heroin
DavidMob
dark web step by step counterfeit money onion https://asapdrugsmarket.com/ - buying things from darknet markets
Hansmog
darknet links market dark web poison https://asap-darkmarketplace.com/ - outlaw darknet market url
PatrickDuelp
darknet market carding new darknet markets https://versus-dark-markett.com/ - dark web drugs
BrianBen
asap market best dark web markets 2022 https://versusdarknet.com/ - darknet websites wiki
Frankcit
dream market darknet url darknet markets with tobacco https://asap-marketplace.com/ - best black market websites
Charlesjerce
top 10 dark web url darknet market stats https://asap-drugs-market.com/ - darknet drug markets
Justinfluff
dark market sites darknet markets list 2022 https://asapdarknetdrugstore.com/ - best tor marketplaces
WendellEnaky
darknet markets onion address buy ssn dob with bitcoin https://asap-onlinedrugs.com/ - dark market
Jamesgox
market cypher darknet drug market url https://dark-web-asap.com/ - darknet markets still open
BrandonTor
deep web shopping site what darknet market to use https://darkmarketasap.com/ - most popular darknet market
Geraldnob
darknet list market drugs on deep web https://asapurl.com/ - alphabay market link
Dannymycle
dark web xanax Cocorico link https://versusdarkmarketonline.com/ - what is the best darknet market
GeorgeThuth
best darknet marketplaces darknet black market list https://cannahomemarketplace24.com/ - dark markets indonesia
MichaelSware
darknet сайт мега онион сайт https://hydramarketdarknet.link/ - mega зеркало
Hilltob
archetyp link Abacus Market https://web-darknet-market.link/ - darknet marketplace drugs
Sirtob
best dark net markets dark web links 2022 reddit https://asapdarkwebdrugstore.com/ - darknet drugs reddit
Zacharyhet
how to get on the dark web on laptop reddit darknet market 2022 https://versus-online-drugs.com/ - Cocorico Market
Robertket
зайти на мегу сайты даркнет ссылки https://hydramarket-online.link/ - мега шишки
CraigFaf
darknet market 2022 reddit cp onion https://asapmarketplacee.com/ - market deep web 2022
RichardCyday
tor search onion link darknet markets australia https://darkwebversus.com/ - vice city darknet market
Jamesopike
uncensored hidden wiki link currently darknet markets https://asap-onion-darkweb.com/ - tormarket onion
HaroldImaby
lsd drug wiki the darknet drugs https://versusdarkweb.com/ - best darknet markets for marijuana
DanielEncon
fresh onions link darknet market directory https://asapdarkmarketplace.com/ - tor2door darknet market
RandyZenny
darknet drug prices reddit dark markets turkey https://cannahomemarket-darknet.com/ - sichere darknet markets 2022
WilliamBlade
active darknet markets deep onion links https://asapdrugsonline.com/ - active darknet market urls
DamonPoday
tor marketplace tor marketplace https://asaponionmarket.com/ - tor darknet market address
Williamreoft
alphabay darknet market darknet market list url https://webdarknetmarkets.link/ - cvv black market
RobertGic
reddit darknet markets noobs dark web drugs ireland https://darkmarket-asap.com/ - asap darknet market
Davidmab
online black market electronics Cocorico Market link https://webdarknetmarkets.com/ - top darknet drug sites
Torntow
how to access dark net dark web search engine 2022 https://wwwdarknetmarket.com/ - how to get on the dark web android
Jackiesix
магазин мега мега скорость https://hydramarketdarknet.link/ - mega onion
HectorMug
мега нарко мега onion оффициальный сайт https://hydramarket-online.link/ - мега кокаин
CharlesGet
darknet markets japan darkfox market url https://darkweb-asap.com/ - onion seiten 2022
MichaelCox
мега кокаин зеркало мега https://hydramarket-darknet.link/ - официальный сайт мега
Donaldrhisp
best darknet market uk deep web links 2022 https://versus-drugs-online.com/ - buying from darknet market with electrum
Ronaldimpak
darknet black market dark web counterfeit money https://asapmarketplace24.com/ - best website to buy cc
SteveNek
мега onion оффициальный сайт mega onion shop https://hydramarketdarkweb.link/ - ссылки на даркнет
CorryBoura
what darknet market to use deep onion links https://wwwdarknetmarket.shop/ - asap url
HellySAr
how to access darknet markets reddit darknet markets https://asap-dark-market.com/ - dark web search tool
ADangep
grey market darknet link alphabay market https://acannahome-market.com/ - darknet market onions
RalphusafT
darknet market credit cards best darknet gun market https://asap-darknet.com/ - reliable darknet markets reddit
Mattheworali
new dark web links dark markets bulgaria https://versusdarkwebmarkett.com/ - darknet market links safe
Juliusbop
black market reddit cypher market darknet https://versus-darkweb.com/ - how to buy drugs dark web
Timmylurry
darknet markets fake id darknet drugs guide https://versus-darknet.com/ - marijuana dark web
DavidSig
updated darknet market list versus market url https://versus-darkmarket.com/ - dark web sites for drugs
Granthub
dark net market list reddit dark markets germany https://cannahomeoniondarkweb.com/ - new darknet markets 2022
Michaelhoise
dma drug darknet link drugs https://versus-darkwebmarket.com/ - Kingdom darknet Market
WilliamQuego
best mdma vendor darknet market reddit dark markets slovenia https://asapdarkmarket.com/ - assassination market darknet
JosephBok
bohemia link site darknet market https://dark-market-asap.com/ - onion linkek
Richardkeymn
зайти на мегу mega онион https://hydra-market-onion.link/ - мега мефедрон
Jancib
cheapest drugs on darknet dark markets albania https://webdrugs-darknet.link/ - how to get to darknet market
Julianacunc
Heineken Express url onion live links https://aversus-market.com/ - dark web fake money
CrisUnano
darknet drug store vice city link https://wwwdarkmarket.link/ - best darknet market for steroids
JamesVet
hacking tools darknet markets darknet stock market https://asap-darkwebmarket.com/ - drugs on darknet
Frankcit
Kingdom url darkweb market https://asap-marketplace.com/ - most popular darknet market
Charlesjerce
online black market uk monero darknet markets https://asap-drugs-online.com/ - darknet guide
JasonRab
darknet credit card market dark web markets 2022 https://versus-marketplace24.com/ - darknet market litecoin
EdgarFar
даркнет сайты магазин mega магазин https://hydramarket-darkweb.link/ - ссылки на даркнет
ShaneLit
alphabay market how to buy things off the black market https://asapmarket-linkk.com/ - list of darknet markets 2022
DavidMob
dark markets colombia darkfox url https://asapdrugsmarketplace.com/ - fresh onions link
Hansmog
black market reddit alphabay market net https://asap-darkmarketplace.com/ - Cocorico link
PatrickDuelp
dark markets germany asap url https://versus-darkmarket-online.com/ - dark web search engine 2022
BrianBen
assassination market darknet blackweb darknet market https://versusdarknet.com/ - deep market
Jamesgox
what darknet markets are live darknet list market https://dark-web-asap.com/ - wiki sticks drugs
BrandonTor
buying drugs online on openbazaar dark markets norge https://darkmarketversus.com/ - dark web trading
Justinfluff
list of darknet drug markets how to buy from the darknet markets https://asapdarknetdrugstore.com/ - onion sex shop
Sirtob
onion directory how to browse the dark web reddit https://asapdarkwebdrugstore.com/ - brucelean darknet market
WendellEnaky
drugs on the dark web versus project market link https://asap-onion-market.com/ - darknet drug links
GeorgeThuth
darknet drugs how to create a darknet market https://cannahomemarketplace24.com/ - dark markets usa
Dannymycle
deep web deb dark web links adult https://versusdarkmarketonline.com/ - hidden uncensored wiki
MichaelSware
ссылка на мегу зеркало мега https://hydramarketdarknet.link/ - darknet магазин
Randylog
dark web drug marketplace safe darknet markets https://versus-onion-market.com/ - darkfox market darknet
Geraldnob
deep dark web markets links darknet market arrests https://asapurl.com/ - dark markets
Robertket
даркнет магазин мега кокаин https://hydramarket-online.link/ - мега ссылка
Smittjen
deep web addresses onion darknet markets deepdotweb https://asap-darkmarket.com/ - darknet links markets
CraigFaf
buying drugs online best darknet market for steroids https://asaponiondarkmarket.com/ - best lsd darknet market
Zacharyhet
darknet drugs india best market darknet drugs https://versus-online-drugs.com/ - most popular darknet markets 2022
Hilltob
what is the best darknet market cannabis dark web https://web-darknet-market.com/ - cannazon market darknet
RichardCyday
dark markets malta buy bitcoin for dark web https://darkwebasap.com/ - Kingdom Market url
HaroldImaby
best darknet market reddit 2022 wiki darknet market https://versusdarkweb.com/ - how to get on the dark web on laptop
Jamesopike
i2p darknet markets black market dark web links https://asap-onion-darkmarket.com/ - asap market
DanielEncon
vice city market incognito market link https://asapdarknet.com/ - dark markets belgium
WilliamBlade
darknet markets list darknet market vendors search https://asapmarket-darknet.com/ - darknet market dash
RandyZenny
Kingdom darknet Market dark market 2022 https://cypherdarkwebdrugstore.com/ - new darknet marketplaces
Davidmab
list of online darknet market links tor 2022 https://webdarknetmarkets.com/ - darknet markets
BrandenTap
mega market mega магазин https://hydra-market-onion.link/ - мега магазин
HectorMug
ссылка мега мега вход https://hydramarket-online.link/ - новое зеркало мега
DamonPoday
uk darknet markets tor markets https://asaponiondarkweb.com/ - dark web marketplace
ADangep
darknet market url list hidden marketplace https://aasap-market.com/ - tor onion search
HellySAr
black market websites 2022 what is escrow darknet markets https://asap-dark-market.com/ - deep web search engines 2022
CorryBoura
legit darknet sites darkfox url https://wwwdarknetmarket.shop/ - deep web onion url
CharlesGet
dark markets uk darknet drug vendors https://darkweb-versus.com/ - darknet in person drug sales
Torntow
black market webshop darknet drug prices reddit https://wwwdarknetmarket.com/ - reddit darknet markets 2022
Ronaldimpak
dark web cheap electronics darknet market list links https://asapmarketplace24.com/ - darknet markets norge
MichaelCox
darknet магазин mega ссылка https://hydramarket-darknet.link/ - даркнет магазин
DavidSig
asap link bitcoin cash darknet markets https://versus-darkmarketplace.com/ - dark web drugs australia
Juliusbop
dark web live duckduckgo onion site https://versus-darkweb.com/ - darknet drugs 2022
Timmylurry
dark web site list incognito market https://versus-darknet.com/ - alphabay market onion link
RalphusafT
tor darknet market which darknet market are still up https://asap-darknet.com/ - underground market online
Mattheworali
deep web software market dark web cvv https://versusdarkwebmarkett.com/ - 2022 working darknet market
Granthub
darknet market prices reliable darknet markets reddit https://cannahomeoniondarkweb.com/ - reddit darknet market how to
Michaelhoise
darknet market drug prices darknet steroid markets https://versus-drugs-market.com/ - dark markets canada
Jackiesix
даркнет ссылки мега купить https://hydramarketdarknet.link/ - мега кокаин
Charlesjerce
onion dark web list buy drugs darknet https://asap-drugs-online.com/ - 2022 darknet market
JamesVet
trusted darknet vendors tor darknet market address https://asap-darkweb.com/ - versus market link
Julianacunc
bohemia market darkmarket 2022 https://aversus-market.com/ - how to get to darknet market safe
JasonRab
agora darknet market darknet markets reddit https://versus-onion-darkmarket.com/ - best australian darknet market
EdgarFar
mega сайт mega onion shop https://hydramarket-darkweb.link/ - мега сайт ссылка
Jancib
google black market dark web search engines 2022 https://webdrugs-darknet.shop/ - best darknet market links
BrandonTor
bohemia market link how to access the dark web 2022 https://darkmarketasap.com/ - Kingdom link
ShaneLit
dnm market tor marketplace https://asapmarket-linkk.com/ - dark markets norge
Jamesgox
darknet stock market darknet dream market reddit https://dark-web-versus.com/ - dark markets singapore
DavidMob
how to access dark web markets bitcoin darknet markets https://asapdrugsmarket.com/ - lsd drug wiki
Hansmog
archetyp market darknet bitcoin black market https://asap-darknet-drugstore.com/ - deep web drug url
PatrickDuelp
dark web buy bitcoin reddit darknet market guide https://versus-dark-markett.com/ - asap darknet market
BrianBen
dark markets russia darknet market prices https://versusdarkmarketplace.com/ - dark markets montenegro
CrisUnano
dark net markets crypto market darknet https://wwwdarkmarket.com/ - darknet markets reddit links
Justinfluff
deep net access darknet drugs australia https://asapdarknetdrugstore.com/ - dark markets netherlands
WendellEnaky
how to get on the dark web Abacus Market link https://asap-onion-market.com/ - darknet market url
Richardkeymn
даркнет ссылки мега купить https://hydramarket-darknet.link/ - мега шишки
Sirtob
tor2door market url hidden wiki tor onion urls directories https://asapdarkwebmarket.com/ - darknet markets urls
Dannymycle
darkfox market cannabis dark web https://versusdarkmarketlink.com/ - tor market darknet
GeorgeThuth
darknet market get pills how to access the darknet market https://cannahomemarketplace24.com/ - darknet litecoin
MichaelSware
мега onion магазин магазины даркнета https://hydramarketdarknet.link/ - мэги сайт
Randylog
dark web store darknet market list https://versus-onion-darkweb.com/ - onion tube porn
Robertket
mega магазин mega ссылка https://hydramarket-online.link/ - мега вход
Smittjen
dark markets guyana market deep web 2022 https://cannahome-darkweb-drugstore.com/ - dark markets croatia
CraigFaf
grey market darknet reliable darknet markets https://asapmarketplacee.com/ - best darknet drug market 2022
Geraldnob
dark web search engine 2022 darknet drugs india https://asapurl.com/ - dark web drugs
Zacharyhet
deep web onion url history of darknet markets https://versus-onlinedrugs.com/ - archetyp link
RichardCyday
dark markets greece dark web sites name list https://darkwebversus.com/ - tor market links 2022
Hilltob
darknet market sites tma drug https://web-darknet-market.com/ - dark web store
Jamesopike
darknet links markets darknet link drugs https://asap-onion-darkweb.com/ - reliable darknet markets lsd
WilliamBlade
Kingdom Market url cannazone https://asapmarket-darknet.com/ - darknet market package
RandyZenny
dbol steroid pills deep net access https://cannahomemarket-darknet.com/ - darknet market black
RobertGic
list of darknet drug markets uk darknet markets https://darkmarket-versus.com/ - deep web cc sites
HectorMug
сайты даркнет ссылки мега онион сайт https://hydramarket-darkweb.link/ - mega market
HellySAr
reddit darknet markets links dark web prostitution https://asap-dark-market.com/ - dark markets mexico
ADangep
links deep web tor how to access deep web safely reddit https://aasap-market.com/ - darknet sites url
Davidmab
legit darknet sites best onion sites 2022 https://web-darknet-market.shop/ - how to darknet market
Williamreoft
dark web sites drugs darknet onion markets reddit https://webdarknetmarkets.link/ - dark web sales
CorryBoura
darknet markets for steroids incognito market url https://wwwdarknetmarket.link/ - dark markets turkey
Timmylurry
darknet market dash dark market onion https://versus-darknet-drugstore.com/ - best darknet market links
Juliusbop
guide to using darknet markets reddit working darknet markets https://versus-darkweb.com/ - Kingdom url
DamonPoday
darknet prices darknet market reddit https://asaponiondarkweb.com/ - dark web buy bitcoin
Torntow
dark markets guyana black market bank account https://wwwdarknetmarket.com/ - drug market
Ronaldimpak
darknet market alphabay dark markets usa https://asapmarket-urll.com/ - darknet market vendors
CharlesGet
dream market darknet url darknet cannabis markets https://darkweb-asap.com/ - new onion darknet market
Donaldrhisp
black market online website trusted darknet markets weed https://versus-drugs-online.com/ - adresse dark web
MichaelCox
мега onion зеркала зеркало мега https://hydramarket-darknet.link/ - даркнет магазин
RalphusafT
dark markets switzerland reddit best darknet market https://asap-darkweb-drugstore.com/ - best market darknet drugs
Mattheworali
cannahome darknet market darknet cannabis markets https://versusdarkwebdrugstore.com/ - cypher market link
SteveNek
зайти на мегу ссылка мега https://hydramarketdarkweb.link/ - мега onion оффициальный сайт
Frankcit
new darknet markets 2022 darknet drugs links https://asap-drugsonline.com/ - darknet market comparison chart
JamesVet
dark web drugs bitcoin dark markets belgium https://asap-darkwebmarket.com/ - dark web sales
Granthub
incognito url cypher market darknet https://asap-online-drugs.com/ - how to access the dark web on pc
JosephBok
black market drugs dark markets philippines https://dark-market-versus.com/ - darknet markets reddit links
Michaelhoise
best onion sites 2022 good dark web search engines https://versus-drugs-market.com/ - best darknet market for psychedelics
Charlesjerce
onion links 2022 dark markets indonesia https://asap-drugs-market.com/ - deep web drug url
BrandonTor
dark markets poland active darknetmarkets https://darkmarketasap.com/ - best deep web markets
JasonRab
link darknet market darknet online drugs https://versus-marketplace24.com/ - cannabis dark web
EdgarFar
мега онион сайт мега onion магазин https://hydramarket-darkweb.link/ - mega onion ссылка
DavidMob
darknet list blackweb darknet market https://asapdrugsmarket.com/ - dot onion websites
Jancib
how to pay with bitcoin on dark web best darknet market for lsd https://webdrugs-darknet.shop/ - dark net market links 2022
Julianacunc
tor onion search deep website search engine https://aversus-market.com/ - deep web shopping site
Hansmog
new darknet market reddit dark web drugs australia https://asap-darkmarketplace.com/ - active darknet market urls
PatrickDuelp
reddit darknet reviews darknet markets list reddit https://versus-dark-markett.com/ - darknet new market link
BrianBen
darknet market list url alphabay market link https://versusdarknet.com/ - tor2door market link
CrisUnano
cannazon link new darknet market reddit https://wwwdarkmarket.link/ - alphabay market url darknet adresse
Justinfluff
alphabay market onion link monkey x pill https://asapdarkweb.com/ - dream market darknet link
WendellEnaky
xanax on darknet best darknet market may 2022 reddit https://asap-onion-market.com/ - which darknet markets are up
Richardkeymn
даркнет ссылки даркнет магазин https://hydra-market-onion.link/ - мега официальный сайт
Sirtob
darkfox darknet market darknet drugs url https://asapdarkwebmarket.com/ - darknet markets list reddit
MichaelSware
мега сайт ссылка зайти на мегу https://hydramarketdarknet.link/ - mega onion
Dannymycle
buying drugs online darknet bitcoin market https://versusdarkmarketlink.com/ - darknet markets norge
GeorgeThuth
best dark net markets alphabay market url https://cannahomemarketplace24.com/ - darknet markets that take ethereum
Randylog
best tor marketplaces what is darknet markets https://versus-onion-market.com/ - darknet marketplace drugs
CraigFaf
superman pills mg darknet market noobs guide https://asaponiondarkmarket.com/ - darknet markets 2022
Robertket
мега наркотики мега онион https://hydramarket-online.link/ - ьупф ьфклуе
Smittjen
dark markets belarus what darknet markets are live https://asap-darkmarket.com/ - darknet market vendors search
Zacharyhet
illegal black market dark web website links https://versus-online-drugs.com/ - new darknet market reddit
RichardCyday
deep web search engine 2022 how to buy bitcoin and use on dark web https://darkwebversus.com/ - what darknet markets are open
Geraldnob
what darknet markets are live popular darknet markets https://asapurl.com/ - archetyp market darknet
Jamesopike
darknet markets that take ethereum dark markets ukraine https://asap-onion-darkmarket.com/ - darknet market alaska
HaroldImaby
how to buy bitcoin for the dark web darknet market dmt https://versusdarkweb.com/ - deep web drugs reddit
DanielEncon
deep web drugs hidden marketplace https://asapdarknet.com/ - orange sunshine pill
WilliamBlade
onion websites for credit cards darknet market adderall https://asapdrugsonline.com/ - bohemia darknet market
RandyZenny
darknet market black incognito url https://cannahomemarket-darknet.com/ - biggest darknet markets
HellySAr
decabol pills best darknet market 2022 https://asap-dark-market.com/ - darknet new market link
ADangep
best dark web search engine link phenethylamine drugs https://acannahome-market.com/ - live dark web
HectorMug
mega market мега наркотики https://hydramarket-darkweb.link/ - mega онион сайт
Timmylurry
cp links dark web links da deep web 2022 https://versus-darknet-drugstore.com/ - darkweb sites reddit
Juliusbop
darknet market adressen the dark market https://versus-darkweb-drugstore.com/ - dark web adderall
DavidSig
darknet bank accounts hidden uncensored wiki https://versus-darkmarketplace.com/ - darknet black market list
BrandenTap
мега onion ссылка мега onion зеркало https://hydra-market-onion.link/ - официальный сайт мега
Williamreoft
versus project link cannahome market darknet https://webdrugs-darknet.com/ - buy bitcoin for dark web
RobertGic
which darknet markets are up incognito market link https://darkmarket-versus.com/ - darknet markets most popular
CorryBoura
live onion Abacus darknet Market https://wwwdarknetmarket.link/ - darknet market noobs reddit
Torntow
tor market nz dark markets sweden https://wwwdarkmarket.shop/ - market cypher
Ronaldimpak
darknet market that has ssn database superman pills mg https://asapmarketplace24.com/ - buy drugs from darknet
CharlesGet
darknet market 2022 reddit darknet drug store https://darkweb-asap.com/ - mdm love drug
Donaldrhisp
crypto market darknet onion links for deep web https://versus-drugsonline.com/ - darknet market arrests
RalphusafT
darknet market bible darknet markets 2022 https://asap-darkweb-drugstore.com/ - what is darknet markets
DamonPoday
reddit darknet market noobs bible tor websites reddit https://asaponiondarkweb.com/ - black market cryptocurrency
Frankcit
versus project darknet market darknet adressen https://asap-marketplace.com/ - best darknet market for weed 2022
JamesVet
darknet market noobs bible incognito link https://asap-darkweb.com/ - how to pay with bitcoin on dark web
SteveNek
mega зеркало мэги сайт https://hydramarketdarkweb.link/ - мега onion
WilliamQuego
darkmarkets versus project link https://asapdarkmarketonline.com/ - best website to buy cc
JosephBok
Abacus Market url cannazon link https://dark-market-versus.com/ - how to install deep web
Michaelhoise
versus link credit card dark web links https://versus-drugs-market.com/ - darknet market iphone
Jackiesix
мега купить mega onion оффициальный сайт https://hydramarketdarknet.link/ - darknet сайт
BrandonTor
tor market safe darknet markets https://darkmarketasap.com/ - alphabay market link
Jamesgox
tor market dark web drugs https://dark-web-asap.com/ - darkmarket link
Charlesjerce
where to find onion links how to access the dark web through tor https://asap-drugs-market.com/ - darknet market prices
Granthub
darknet market steroids dark markets hungary https://cannahomeoniondarkweb.com/ - darknet market url
JasonRab
deep web link 2022 dark markets lithuania https://versus-onion-darkmarket.com/ - darknet markets fake id
ShaneLit
darknet onion links drugs deep web link 2022 https://asapmarket-linkk.com/ - dark net market links 2022
DavidMob
tor2door market link reddit darknet reviews https://asapdrugsmarketplace.com/ - site darknet fermГ©
EdgarFar
darknet магазин зелья мега магазин https://hydramarket-darkweb.link/ - mega onion оффициальный сайт
Jancib
current list of darknet markets site onion liste https://webdrugs-darknet.shop/ - archetyp link
BrianBen
pyramid pill dark web search tool https://versusdarknet.com/ - verified darknet market
Hansmog
deep web trading dark web vendors https://asap-darkmarketplace.com/ - cheap darknet websites dor drugs
Julianacunc
cypher link black market drugs https://cannahome-marketplace.com/ - versus market
CrisUnano
onion links credit card dark markets switzerland https://wwwdarkmarket.com/ - darknet escrow markets
WendellEnaky
onion marketplace drugs tor websites reddit https://asap-onlinedrugs.com/ - currently darknet markets
Justinfluff
how to buy from the darknet markets lsd what is a darknet drug market like https://asapdarknetdrugstore.com/ - most popular darknet markets 2022
Dannymycle
tor market url best darknet market now https://versusdarkmarketonline.com/ - ketamine darknet market
MichaelSware
mega onion ссылка ссылки на даркнет https://hydramarketdarknet.link/ - мега зеркало
GeorgeThuth
best dark web links how to use darknet markets https://cannahomemarketplacee.com/ - buying on dark web
Sirtob
online black market uk darknet market bible https://asapdarkwebmarket.com/ - access darknet markets
Richardkeymn
мега купить соль мега сайт ссылка https://hydramarket-darknet.link/ - мега магазин
CraigFaf
asap url reddit darknet market links https://asapmarketplacee.com/ - darknet credit card market
Robertket
мэги сайт официальный сайт мега https://hydramarket-online.link/ - mega даркнет
Randylog
best darknet market uk best darknet drug sites https://versus-onion-darkweb.com/ - deep web weed prices
Smittjen
darknet market redit Heineken Express url https://asap-darkmarket.com/ - tor darknet markets
RichardCyday
marijuana dark web darknet markets reddit links https://darkwebversus.com/ - dark markets united kingdom
Zacharyhet
dark markets mexico dark net market list https://versus-online-drugs.com/ - how to access the dark web 2022
Jamesopike
underground market online what are darknet drug markets https://asap-onion-darkweb.com/ - dark web markets reddit 2022
ADangep
working darknet markets 2022 deep dark web https://acannahome-market.com/ - url hidden wiki
HellySAr
archetyp link darknet drugs sales https://asap-dark-market.com/ - dark web trading
HaroldImaby
darknet drug prices reddit dot onion websites https://versusdarkweb.com/ - darknet market oz
DanielEncon
onion deep web wiki dark net market links 2022 https://asapdarkmarketplace.com/ - underground dumps shop
Timmylurry
the best onion sites red ferrari pills https://versus-darknet.com/ - darknet bank accounts
Juliusbop
darknet drugs australia monkey x pill https://versus-darkweb-drugstore.com/ - dark markets montenegro
DavidSig
Cocorico Market link darknet market adressen https://versus-darkmarket.com/ - dark web sites name list
WilliamBlade
safe darknet markets onion tube porn https://asapdrugsonline.com/ - site darknet onion
Geraldnob
deep web drug url dark web markets 2022 https://asaponlinedrugs.com/ - how to use darknet markets
RandyZenny
dark markets iceland nike jordan pill https://cypherdarkwebdrugstore.com/ - black market bank account
CharlesGet
duckduckgo onion site dark markets hungary https://darkweb-asap.com/ - darknet market onions
HectorMug
ьупф ьфклуе мега официальный сайт https://hydramarket-online.link/ - ссылка на мегу
Hilltob
top darknet markets darknet market steroids https://web-darknet-market.link/ - duckduckgo dark web search
RobertGic
market cypher deep web updated links https://darkmarket-versus.com/ - alphabay market url darknet adresse
BrandenTap
мега официальный сайт мега официальный сайт https://hydra-market-onion.link/ - мега официальный сайт
Davidmab
dark market url cannahome market link https://webdarknetmarkets.com/ - versus market link
Williamreoft
how to access the dark web through tor current list of darknet markets https://webdarknetmarkets.link/ - how to buy things off the black market
CorryBoura
reddit working darknet markets tor darknet https://wwwdarknetmarket.link/ - deep web onion url
Torntow
versus project darknet market unicorn pill https://wwwdarkmarket.shop/ - reddit darknet reviews
Frankcit
darknet buy drugs dark markets poland https://asap-marketplace.com/ - buy darknet market email address
Ronaldimpak
dark web address list dark market url https://asapmarket-urll.com/ - deep web drugs
Donaldrhisp
darkfox market darknet tor market list https://versus-drugs-online.com/ - incognito darknet market
RalphusafT
back market trustworthy the armory tor url https://asap-darknet.com/ - list of darknet markets reddit
MichaelCox
мега зеркало mega onion shop https://hydramarket-darknet.link/ - мега onion зеркала
Mattheworali
onion marketplace drugs Abacus darknet Market https://versusdarkwebdrugstore.com/ - deep web url links
DamonPoday
darknet market lightning network dark web electronics https://asaponiondarkweb.com/ - darknet market adressen
SteveNek
mega onion shop мега сайт ссылка https://hydramarketdarkweb.link/ - мега вход
BrandonTor
deep web drug store darknet markets onion addresses https://darkmarketasap.com/ - deep web drug prices
WilliamQuego
where to find darknet market links redit how to anonymously use darknet markets https://asapdarkmarketonline.com/ - what darknet markets are up
Jamesgox
darknet bitcoin market dark markets colombia https://dark-web-versus.com/ - darknet market carding
JosephBok
vice city market url reddit darknet market noobs bible https://dark-market-asap.com/ - dark web escrow service
Jackiesix
мега официальный сайт мега кокаин https://hydramarketdarknet.link/ - зеркало мега
Michaelhoise
deep web drugs darknet market guide reddit https://versus-darkwebmarket.com/ - dark web buy credit cards
JasonRab
escrow dark web top ten dark web sites https://versus-onion-darkmarket.com/ - darknet market litecoin
DavidMob
darknet seiten liste tor link list 2022 https://asapdrugsmarket.com/ - darknet database market
ShaneLit
darknet drug store anadrol pills https://asapmarket-linkk.com/ - top dumps shop
Jancib
darknet market lists incognito darknet market https://webdrugs-darknet.shop/ - project versus
PatrickDuelp
darknet steroid markets dark markets serbia https://versus-darkmarket-online.com/ - underground card shop
EdgarFar
mega магазин ьупф ьфклуе https://hydramarket-darkweb.link/ - мега наркотики
BrianBen
reddit darknet markets links dark markets netherlands https://versusdarknet.com/ - dark web sites xxx
Hansmog
black market online website most popular darknet market https://asap-darknet-drugstore.com/ - dark markets thailand
CrisUnano
what darknet markets still work vice city market link https://wwwdarkmarket.com/ - litecoin darknet markets
Justinfluff
dark web markets reddit 2022 cypher market https://asapdarkweb.com/ - Abacus Market link
WendellEnaky
dark web escrow service darknet markets norge https://asap-onion-market.com/ - deep web drugs reddit
Julianacunc
dark web prepaid cards reddit verified dark web links https://aversus-market.com/ - versus project market
Dannymycle
buy darknet market email address darknet market avengers https://versusdarkmarketonline.com/ - deep web links 2022
MichaelSware
сайт мега мега сайт https://hydramarketdarknet.link/ - сайты даркнет ссылки
GeorgeThuth
versus market link deep web updated links https://cannahomemarketplace24.com/ - darkmarket url
Sirtob
how to access darknet market dark web uk https://asapdarkwebdrugstore.com/ - onion links 2022
Richardkeymn
сайты даркнет мега купить соль https://hydramarket-darknet.link/ - mega зеркало
Smittjen
dark markets liechtenstein how to access the dark web 2022 https://cannahome-darkweb-drugstore.com/ - the onion directory
Randylog
dark web vendors onion deep web search https://versus-onion-market.com/ - online onion market
ADangep
reddit working darknet markets deep onion links https://aasap-market.com/ - working darknet markets 2022
HellySAr
reddit darknet market uk active darknet markets 2022 https://asap-dark-market.com/ - how to get on the dark web on laptop
Timmylurry
onion live deep web link 2022 https://versus-darknet-drugstore.com/ - underground card shop
Juliusbop
buy bank accounts darknet dark web poison https://versus-darkweb.com/ - dark web weed
DavidSig
darknetlive dark web search engines link https://versus-darkmarket.com/ - darknet market forum
RichardCyday
dark web sites links darknet steroid markets https://darkwebversus.com/ - darknet drugs dublin
Zacharyhet
dark markets guyana buy bank accounts darknet https://versus-online-drugs.com/ - dark web market list
Jamesopike
russian darknet market access the dark web reddit https://asap-onion-darkweb.com/ - Cocorico Market darknet
HaroldImaby
best dark web search engine link dark markets austria https://versusdarkweb.com/ - versus project market
DanielEncon
cvv black market best darknet market australia https://asapdarknet.com/ - darknet market lists
WilliamBlade
best dark web markets reddit darknet market links https://asapdrugsonline.com/ - the best onion sites
RandyZenny
grey market darknet link black market websites tor https://cypherdarkwebdrugstore.com/ - cannazone
HectorMug
мега онион сайт мега onion магазин https://hydramarket-online.link/ - mega market
RobertGic
agora darknet market deep net websites https://darkmarket-versus.com/ - bohemia market url
CorryBoura
tor search onion link dark market links https://wwwdarknetmarket.link/ - how to pay with bitcoin on dark web
JamesVet
most popular darknet market the onion directory https://asap-darkweb.com/ - bitcoin dark website
Torntow
fullz darknet market dream market darknet https://wwwdarkmarket.shop/ - cypher market darknet
Donaldrhisp
darknet markets wax weed dark web step by step https://versus-drugsonline.com/ - black market buy online
RalphusafT
best fraud market darknet core market darknet https://asap-darknet.com/ - dark markets belarus
MichaelCox
мега шишки магазин даркнет https://hydramarket-darknet.link/ - mega onion shop
Frankcit
darknet market vendors cp links dark web https://asap-marketplace.com/ - dark markets austria
Jamesgox
dark markets belarus darknet markets reddit 2022 https://dark-web-asap.com/ - outlaw market darknet
Mattheworali
assassination market darknet darknet guns market https://versusdarkwebmarkett.com/ - deep deep web links
WilliamQuego
darkshades marketplace phenylethylamine https://asapdarkmarket.com/ - onion market url
DamonPoday
dream market darknet trusted darknet markets weed https://asaponionmarket.com/ - dark web links reddit
Jackiesix
mega онион сайт mega сайт https://hydramarketdarknet.link/ - darknet магазин зелья
Michaelhoise
cannahome market url black market drugs guns https://versus-darkwebmarket.com/ - which darknet markets accept zcash
Charlesjerce
dark web markets 2022 australia top ten dark web https://asap-drugs-market.com/ - darknet market place search
Granthub
darknet paypal accounts unicorn pill https://asap-online-drugs.com/ - darkweb marketplace
DavidMob
how to access deep web safely reddit darknet markets up https://asapdrugsmarketplace.com/ - how to access the dark web reddit
JasonRab
uk darknet markets how to buy bitcoin and use on dark web https://versus-onion-darkmarket.com/ - reddit where to buy drugs
ShaneLit
the dark web shop superlist darknet markets https://asapmarket-linkk.com/ - back market legit
PatrickDuelp
black market prescription drugs for sale best dark web counterfeit money https://versus-darkmarket-online.com/ - buy drugs darknet
Jancib
how to buy drugs on the darknet dark web drugs australia https://webdrugs-darknet.shop/ - darknet escrow markets
EdgarFar
mega onion mega ссылка https://hydramarket-darkweb.link/ - mega onion ссылка
Hansmog
steroid market darknet darknet market for noobs https://asap-darknet-drugstore.com/ - darknet software market
BrianBen
darknet market features buying drugs on darknet reddit https://versusdarkmarketplace.com/ - darknet market xanax
CrisUnano
dark markets usa reddit darknet markets list https://wwwdarkmarket.link/ - free deep web links
Justinfluff
incognito market url darknet market xanax https://asapdarknetdrugstore.com/ - mdm love drug
Dannymycle
black market drugs darknet markets working links https://versusdarkmarketlink.com/ - deep web cc shop
WendellEnaky
reddit best darknet market r darknet market https://asap-onion-market.com/ - deep web deb
GeorgeThuth
buy bank accounts darknet best darknet market may 2022 reddit https://cannahomemarketplace24.com/ - underground hackers black market
Sirtob
darknet markets norway 2022 dark web payment methods https://asapdarkwebmarket.com/ - buy drugs from darknet
Julianacunc
darknet market reddit 2022 darknet markets 2022 https://aversus-market.com/ - darknet websites list 2022
Richardkeymn
мэги сайт мега onion оффициальный сайт https://hydra-market-onion.link/ - мега ссылка
DavidSig
darknet drug vendor that takes paypal what is escrow darknet markets https://versus-darkmarketplace.com/ - top ten deep web
Timmylurry
buy bank accounts darknet deep web links reddit 2022 https://versus-darknet-drugstore.com/ - adresse onion
ADangep
dark web markets what darknet markets sell fentanyl https://aasap-market.com/ - darknet market busts
HellySAr
dark web market list dark web in spanish https://asap-dark-market.com/ - canazon
CraigFaf
deep web links reddit deep web search engines 2022 https://asapmarketplacee.com/ - dark markets brazil
Juliusbop
darknet market stats currently darknet markets https://versus-darkweb-drugstore.com/ - darknet escrow
Smittjen
the darknet drugs darknet reddit market https://asap-darkmarket.com/ - what darknet markets are live
Randylog
shop valid cvv dark web links 2022 https://versus-onion-darkweb.com/ - top ten dark web sites
Robertket
зеркало мега mega onion зеркало https://hydramarket-online.link/ - mega market
RichardCyday
how to access the dark web on pc best darknet market reddit https://darkwebasap.com/ - australian darknet vendors
Zacharyhet
top 10 dark web url dark markets australia https://versus-online-drugs.com/ - most reliable darknet markets
Jamesopike
new darknet markets 2022 Cocorico darknet Market https://asap-onion-darkweb.com/ - brick market
HaroldImaby
tor darknet darknet drugs india https://versusdarknetdrugstore.com/ - tor2door market darknet
DanielEncon
darknet market list how to order from dark web https://asapdarkmarketplace.com/ - darknet market noobs guide
WilliamBlade
underground black market website dark web sites links https://asapmarket-darknet.com/ - dark market url
RandyZenny
counterfeit money deep web grey market drugs https://cypherdarkwebdrugstore.com/ - darknet markets 2022 reddit
CharlesGet
what darknet market to use now dark web markets https://darkweb-versus.com/ - dark web site list
MichaelSware
mega онион сайт магазины даркнета https://hydramarketdarknet.link/ - mega onion ссылка
BrandenTap
mega market мега onion ссылка https://hydra-market-onion.link/ - darknet магазин зелья
RobertGic
the darknet drugs buying drugs on darknet reddit https://darkmarket-asap.com/ - legit darknet markets
HectorMug
мега ссылка магазин даркнет https://hydramarket-darkweb.link/ - мега кокаин
Torntow
crypto darknet drug shop tor darknet https://wwwdarkmarket.shop/ - live onion market
Geraldnob
cannazon dark web links adult https://asapurl.com/ - darknet onion markets reddit
JamesVet
alphabay link reddit sichere darknet markets 2022 https://asap-darkwebmarket.com/ - deep web drugs
Donaldrhisp
darknet drugs safe cypher market https://versus-drugs-online.com/ - onion dark web list
Ronaldimpak
darknet drugs url best darknet market for weed 2022 https://asapmarket-urll.com/ - darknet market vendors search
RalphusafT
Cocorico Market how to buy drugs on darknet https://asap-darkweb-drugstore.com/ - top darknet markets 2022
BrandonTor
darkweb форум dark markets norge https://darkmarketversus.com/ - best darknet markets reddit
MichaelCox
мега ссылка сайт мега https://hydramarket-darknet.link/ - даркнет ссылки
Frankcit
how to use darknet markets link darknet market https://asap-drugsonline.com/ - darknet market deep dot web
Mattheworali
versus market link the dark web url https://versusdarkwebmarkett.com/ - darknet market links buy ssn
JosephBok
cannazon link monero darknet markets https://dark-market-asap.com/ - legit darknet markets 2022
WilliamQuego
tor link list 2022 darknet paypal accounts https://asapdarkmarket.com/ - biggest darknet market 2022
SteveNek
магазины даркнета даркнет магазин https://hydramarketdarkweb.link/ - зеркало мега
Jackiesix
мега кокаин mega market https://hydramarketdarknet.link/ - даркнет сайты магазин
Michaelhoise
vice city market darknet market onion https://versus-drugs-market.com/ - bitcoins and darknet markets
DamonPoday
best darknet market reddit 2022 best darknet market now https://asaponiondarkweb.com/ - best tor marketplaces
Granthub
underground hackers black market darknet market search https://asap-online-drugs.com/ - new darknet markets
DavidMob
best darknet market urs onion directory list https://asapdrugsmarketplace.com/ - cvv black market
ShaneLit
dark web uk how to access dark net https://asapmarket-linkk.com/ - black market webshop
PatrickDuelp
tor top websites legit darknet markets https://versus-darkmarket-online.com/ - dark web search tool
JasonRab
hire an assassin dark web Abacus link https://versus-onion-darkmarket.com/ - darkfox market darknet
Jancib
Heineken Express darknet Market dark web prostitution https://webdrugs-darknet.shop/ - drugs on the deep web
Hansmog
buy drugs online darknet darknet market onions https://asap-darknet-drugstore.com/ - deep web link 2022
EdgarFar
сылка на мегу darknet сайт https://hydramarket-darkweb.link/ - магазин мега
BrianBen
best darknet markets uk cannahome market https://versusdarkmarketplace.com/ - grey market link
CrisUnano
buying drugs online on openbazaar dark market onion https://wwwdarkmarket.com/ - black market reddit
Dannymycle
best darknet markets 2022 dark markets singapore https://versusdarkmarketlink.com/ - drugs sold on dark web
Justinfluff
darknet bank accounts dark web search engine 2022 https://asapdarknetdrugstore.com/ - dark markets andorra
WendellEnaky
deep web links 2022 black market alternative https://asap-onion-market.com/ - dark web sales
GeorgeThuth
dark websites best dark web links https://cannahomemarketplace24.com/ - biggest darknet market
Timmylurry
darknet drug market dark web sites links https://versus-darknet.com/ - list of online darknet market
DavidSig
buy drugs online darknet buy drugs darknet https://versus-darkmarket.com/ - dark markets switzerland
ADangep
darknet drugs india how to access the dark web 2022 https://aasap-market.com/ - superman pills mg
HellySAr
tor best websites darknet sites drugs https://asap-dark-market.com/ - darknet drug links
Sirtob
how to access the dark web on pc dxm pills https://asapdarkwebmarket.com/ - australian darknet vendors
Richardkeymn
ьупф ьфклуе сайт мега https://hydramarket-darknet.link/ - сайт даркнет
Julianacunc
bitcoin drugs market dot onion websites https://cannahome-marketplace.com/ - shop online without cvv code
CraigFaf
darknet wiki link darknet onion markets reddit https://asapmarketplacee.com/ - dark web market
Juliusbop
shop online without cvv code buying drugs online https://versus-darkweb.com/ - darknet market xanax
Smittjen
pink versace pill best card shops https://asap-darkmarket.com/ - top 10 dark websites
Randylog
darknet drugs dublin best dark web markets 2022 https://versus-onion-darkweb.com/ - reddit onion list
Robertket
mega сайт даркнет сайты магазин https://hydramarket-online.link/ - мэги сайт
RichardCyday
russian anonymous marketplace dark web address list https://darkwebasap.com/ - dark markets malaysia
Davidmab
buy drugs online darknet onion darknet market https://webdarknetmarkets.com/ - tramadol dark web
Williamreoft
black market websites credit cards darkweb marketplace https://webdarknetmarkets.link/ - russian anonymous marketplace
Jamesopike
russian anonymous marketplace darknet gun market https://asap-onion-darkmarket.com/ - deep web link 2022
Zacharyhet
dark markets turkey dark net market list reddit https://versus-onlinedrugs.com/ - darknet litecoin
DanielEncon
grey market darknet dark web site list https://asapdarkmarketplace.com/ - darknet adressen
BrandenTap
мега скорость мега онион https://hydra-market-onion.link/ - мега даркнет
MichaelSware
мега купить соль мега скорость https://hydramarketdarknet.link/ - сайт мега
WilliamBlade
exploit market darknet dark markets switzerland https://asapmarket-darknet.com/ - reddit darknet market guide
CharlesGet
dark web sites drugs darknet market script https://darkweb-versus.com/ - outlaw darknet market url
CorryBoura
best working darknet market 2022 dark markets philippines https://wwwdarknetmarket.link/ - darknet drug links
Torntow
how to buy drugs on the darknet onion marketplace drugs https://wwwdarkmarket.shop/ - blockchain darknet markets
HectorMug
ссылка на мегу сайты даркнет ссылки https://hydramarket-online.link/ - мега даркнет
JamesVet
darknet markets florida outlaw darknet market url https://asap-darkweb.com/ - deep dark web markets links
Donaldrhisp
darknet market comparison what are darknet drug markets https://versus-drugsonline.com/ - deep web links reddit 2022
Ronaldimpak
best fraud market darknet darknet websites drugs https://asapmarketplace24.com/ - darknet market noobs step by step
BrandonTor
darknet market bust incognito link https://darkmarketversus.com/ - dark markets argentina
Geraldnob
how to install deep web best dark web marketplaces 2022 https://asapurl.com/ - the darknet markets
MichaelCox
мега onion зеркала мэги сайт https://hydramarket-darknet.link/ - mega онион сайт
Frankcit
url hidden wiki how to access the black market https://asap-drugsonline.com/ - versus project market url
Mattheworali
decabol pills darknet markets may 2022 https://versusdarkwebdrugstore.com/ - how to access the black market
WilliamQuego
dark market link market street darknet https://asapdarkmarket.com/ - dark markets austria
JosephBok
dark markets japan asap market link https://dark-market-asap.com/ - berlin telegram group drugs
Jackiesix
мега зеркало сайты даркнет https://hydramarketdarkweb.link/ - mega onion оффициальный сайт
Michaelhoise
dark web payment methods dark web buy bitcoin https://versus-drugs-market.com/ - credit card dark web links
Charlesjerce
alphabay url what is the best darknet market https://asap-drugs-market.com/ - step by step dark web
DamonPoday
best darknet market reddit 2022 bohemia url https://asaponiondarkweb.com/ - darknet seiten
ShaneLit
duckduckgo onion site darknet drug dealer https://asapmarket-linkk.com/ - dark markets greece
DavidMob
onion deep web search what bitcoins are accepted by darknet markets https://asapdrugsmarket.com/ - the armory tor url
PatrickDuelp
nike jordan pill darknet market wiki https://versus-darkmarket-online.com/ - Heineken Express Market
JasonRab
dark markets south korea darknet markets financial times https://versus-marketplace24.com/ - onion darknet market
EdgarFar
ссылка мега магазин мега https://hydramarket-darkweb.link/ - mega onion shop
Hansmog
buy ssn and dob dark net market https://asap-darkmarketplace.com/ - darknet drugs 2022
BrianBen
search darknet markets deep web link 2022 https://versusdarknet.com/ - darknet market adderall prices
ADangep
darknet drug vendors darkfox market darknet https://aasap-market.com/ - buying drugs online
HellySAr
underground card shop dark markets liechtenstein https://asap-darkmarket-online.com/ - onion directory list
DavidSig
onion sex shop best darknet market urs https://versus-darkmarketplace.com/ - darknet guide
Dannymycle
top darknet drug sites new onion darknet market https://versusdarkmarketonline.com/ - how to use the darknet markets
Timmylurry
reddit onion list reddit darknet reviews https://versus-darknet.com/ - darknet markets lsd-25 2022
Justinfluff
best darknet markets uk darknet markets list reddit https://asapdarknetdrugstore.com/ - best darknet drug market 2022
GeorgeThuth
current darknet market the best onion sites https://cannahomemarketplace24.com/ - url hidden wiki
WendellEnaky
black market websites credit cards dark web drug marketplace https://asap-onion-market.com/ - site darknet liste
Sirtob
deep web search engine url ruonion https://asapdarkwebmarket.com/ - dbol steroid pills
CrisUnano
dark markets turkey dark markets norge https://wwwdarkmarket.link/ - how to access the black market
Richardkeymn
мега магазин mega ссылка https://hydramarket-darknet.link/ - как зайти на мегу
CraigFaf
tor darknet market address darknet market links buy ssn https://asaponiondarkmarket.com/ - darknet serious market
Juliusbop
deep web drugs reddit darkfox market darknet https://versus-darkweb-drugstore.com/ - dark markets montenegro
Smittjen
darknet drug prices reddit drugs dark web https://asap-darkmarket.com/ - site darknet fermГ©
Julianacunc
bitcoin dark website carding dark web https://cannahome-marketplace.com/ - reddit biggest darknet market place
Randylog
darknet drugs australia how to buy drugs dark web https://versus-onion-market.com/ - dark web hitmen
BrandenTap
mega магазин новое зеркало мега https://hydra-market-onion.link/ - darknet сайт
MichaelSware
mega зеркало как зайти на мегу https://hydramarketdarknet.link/ - мега нарко
RichardCyday
deep web search engine 2022 reddit darknet market how to https://darkwebasap.com/ - gray market place
Robertket
mega onion мега сайт https://hydramarket-online.link/ - магазин даркнет
HaroldImaby
most popular darknet markets 2022 links the hidden wiki https://versusdarknetdrugstore.com/ - verified darknet market
Davidmab
darknet guns market dark market https://webdarknetmarkets.com/ - market street darknet
Jamesopike
top darknet markets 2022 naked lady ecstasy pill https://asap-onion-darkweb.com/ - reliable darknet markets
Williamreoft
best lsd darknet market most popular darknet markets 2022 https://webdrugs-darknet.com/ - weed only darknet market
Zacharyhet
live darknet markets core market darknet https://versus-online-drugs.com/ - darknet markets florida
DanielEncon
back market trustworthy incognito market https://asapdarknet.com/ - deep web drugs reddit
RandyZenny
tor markets links grey market darknet link https://cannahomemarket-darknet.com/ - brick market
CorryBoura
onion directory best darknet drug market 2022 https://wwwdarknetmarket.shop/ - orange sunshine pill
RobertGic
active darknet markets dark web shop https://darkmarket-asap.com/ - best tor marketplaces
WilliamBlade
dnm market bohemia url https://asapdrugsonline.com/ - tor best websites
Torntow
site darknet fermГ© live onion https://wwwdarknetmarket.com/ - darknet markets still up
BrandonTor
underground website to buy drugs online onion market https://darkmarketasap.com/ - dark web shopping
Jamesgox
site onion liste bohemia link https://dark-web-asap.com/ - what darknet markets are available
HectorMug
darknet магазин ьупф ьфклуе https://hydramarket-online.link/ - mega онион
JamesVet
darknet site blackweb darknet market https://asap-darkweb.com/ - darknet market ddos
Donaldrhisp
darknet sites url best dark net markets https://versus-drugs-online.com/ - how to order from dark web
Ronaldimpak
top darknet markets dark web escrow service https://asapmarketplace24.com/ - how to enter the black market online
RalphusafT
credit card dark web links dark web step by step https://asap-darknet.com/ - black market cryptocurrency
Geraldnob
deep dark web markets links dark web sites drugs https://asapurl.com/ - darknet market comparison chart
MichaelCox
мега купить соль мега мефедрон https://hydramarket-darknet.link/ - магазин даркнет
Mattheworali
darknet markets address wiki sticks drugs https://versusdarkwebmarkett.com/ - deep web markets
SteveNek
мега ссылка мега скорость https://hydramarketdarkweb.link/ - мега онион сайт
Frankcit
how to buy things off the black market verified darknet market https://asap-drugsonline.com/ - what darknet markets are still open
JosephBok
how to get to darknet market safe dark web markets https://dark-market-asap.com/ - wired darknet markets
WilliamQuego
darknet market avengers uk darknet markets https://asapdarkmarket.com/ - darknet markets guide
Granthub
dot onion websites hidden financial services deep web https://asap-online-drugs.com/ - open darknet markets
Jackiesix
мега onion ссылка mega onion ссылка https://hydramarketdarkweb.link/ - сылка на мегу
Michaelhoise
darknet markets australia incognito market url https://versus-darkwebmarket.com/ - darknet markets that take ethereum
Charlesjerce
darknet markets onion address dark web adderall https://asap-drugs-online.com/ - tor drugs
DavidMob
dark markets australia onion directory https://asapdrugsmarketplace.com/ - deep web weed prices
Jancib
darknet market alphabay what darknet markets are still open https://webdrugs-darknet.shop/ - dark web drugs bitcoin
PatrickDuelp
drugs from darknet markets dark markets slovakia https://versus-darkmarket-online.com/ - phenylethylamine
ShaneLit
deep dark web markets links cannazon url https://asapmarket-linkk.com/ - cypher market link
JasonRab
tor market links 2022 the onion directory https://versus-marketplace24.com/ - drug market
DamonPoday
deep net links dark markets https://asaponionmarket.com/ - onion live
ADangep
black market online website darknet wiki link https://acannahome-market.com/ - vice city darknet market
HellySAr
darknet market onion links dream market darknet https://asap-darkmarket-online.com/ - black market buy online
Hansmog
darknet gun market darknet market vendor guide https://asap-darknet-drugstore.com/ - onion live links
BrianBen
dark web fake money buy darknet market email address https://versusdarknet.com/ - credit card dark web links
Timmylurry
bitcoins and darknet markets black market websites credit cards https://versus-darknet.com/ - dark markets belarus
DavidSig
darknet site dark web shopping https://versus-darkmarketplace.com/ - onion seiten
EdgarFar
мега onion зеркало darknet сайт https://hydramarket-darkweb.link/ - darknet магазин зелья
Dannymycle
dark markets norge cannahome market https://versusdarkmarketonline.com/ - how to access deep web safely reddit
Justinfluff
best dark net markets currently darknet markets https://asapdarknetdrugstore.com/ - deep net websites
GeorgeThuth
cannazon market url gbl drug wiki https://cannahomemarketplacee.com/ - top 10 dark web url
WendellEnaky
darknet credit card market current best darknet market https://asap-onion-market.com/ - onion dark web list
Sirtob
reddit darknet market list hidden uncensored wiki https://asapdarkwebdrugstore.com/ - the armory tor url
CrisUnano
biggest darknet markets onion directory list https://wwwdarkmarket.com/ - hacking tools darknet markets
Richardkeymn
мега мефедрон mega onion shop https://hydra-market-onion.link/ - mega даркнет
BrandenTap
даркнет сайты магазин mega магазин https://hydra-market-onion.link/ - магазин мега
MichaelSware
сылка на мегу mega онион https://hydramarketdarknet.link/ - mega onion ссылка
Smittjen
darknet market vendors search how to search the dark web reddit https://cannahome-darkweb-drugstore.com/ - links the hidden wiki
Randylog
onion live links best darknet market 2022 https://versus-onion-market.com/ - underground black market website
Robertket
мега onion зеркало mega onion зеркало https://hydramarket-online.link/ - новое зеркало мега
HaroldImaby
Kingdom Market darknet darknet drug prices https://versusdarkweb.com/ - cheap darknet websites dor drugs
DanielEncon
reddit darknet markets noobs how to darknet market https://asapdarkmarketplace.com/ - dark markets macedonia
Williamreoft
dark web sites for drugs darknet adress https://webdarknetmarkets.link/ - best fraud market darknet
Davidmab
dark web sites drugs buying on dark web https://webdarknetmarkets.com/ - access the black market
Zacharyhet
best darknet market reddit list of dark net markets https://versus-online-drugs.com/ - australian dark web markets
RobertGic
darknet markets reddit 2022 deep web directory onion https://darkmarket-asap.com/ - dark web links
RandyZenny
darknet market 2022 reddit drug markets dark web https://cannahomemarket-darknet.com/ - buy ssn dob with bitcoin
BrandonTor
deep web software market dark web links 2022 reddit https://darkmarketasap.com/ - dark markets lithuania
Jamesgox
the onion directory dark web marketplace https://dark-web-versus.com/ - reddit darknet market list
WilliamBlade
darknet market avengers blacknet drugs https://asapmarket-darknet.com/ - darkweb sites reddit
Torntow
legit darknet markets 2022 top dark net markets https://wwwdarknetmarket.com/ - darknet drugs market
Julianacunc
best darknet market for weed 2022 dark chart https://cannahome-marketplace.com/ - darknet market 2022 reddit
JamesVet
darknet market listing black market net https://asap-darkweb.com/ - we amsterdam
Donaldrhisp
dark net markets darknet market pills vendor https://versus-drugsonline.com/ - tor link search engine
HectorMug
даркнет сайты магазин новое зеркало мега https://hydramarket-darkweb.link/ - mega onion shop
Ronaldimpak
wiki darknet market hidden uncensored wiki https://asapmarketplace24.com/ - drugs on darknet
RalphusafT
darknet guns market best darknet market uk https://asap-darkweb-drugstore.com/ - reddit darknet market uk
SteveNek
мега онион сайт зайти на мегу https://hydramarketdarkweb.link/ - сылка на мегу
MichaelCox
мега ссылка mega onion зеркало https://hydramarket-darknet.link/ - мега onion оффициальный сайт
Mattheworali
escrow market darknet dark web site list https://versusdarkwebdrugstore.com/ - darknet market bust
Frankcit
dn market best darknet market 2022 https://asap-marketplace.com/ - gbl drug wiki
Geraldnob
onion market url dark markets colombia https://asapurl.com/ - darknet market drug prices
JosephBok
darknet market reddits trusted darknet markets weed https://dark-market-asap.com/ - versus project market url
WilliamQuego
darknet market alternatives darknet market updates 2022 https://asapdarkmarketonline.com/ - deep web drug url
Granthub
underground website to buy drugs tor onion search https://asap-online-drugs.com/ - dark markets monaco
Michaelhoise
biggest darknet markets 2022 dark markets san marino https://versus-drugs-market.com/ - deep web link 2022
Jackiesix
мега вход mega onion оффициальный сайт https://hydramarketdarknet.link/ - mega onion оффициальный сайт
Charlesjerce
asap market darknet darknet market 2022 reddit https://asap-drugs-market.com/ - deep dot web replacement
DavidMob
darkshades marketplace darkfox darknet market https://asapdrugsmarket.com/ - Kingdom link
Jancib
tramadol dark web bohemia link https://webdrugs-darknet.shop/ - best darknet markets reddit
ADangep
alphabay market url darknet adresse darknet market guide reddit https://acannahome-market.com/ - best darknet markets reddit
HellySAr
tor market darknet Kingdom link https://asap-dark-market.com/ - cypher market darknet
DavidSig
black market url deep web best darknet markets reddit https://versus-darkmarket.com/ - dark web counterfeit money
JasonRab
onion marketplace drugs reddit biggest darknet market place https://versus-onion-darkmarket.com/ - darknet market wikia
Timmylurry
cypher market darknet dark markets ukraine https://versus-darknet-drugstore.com/ - darknet search
Hansmog
dark web buy bitcoin the armory tor url https://asap-darkmarketplace.com/ - black market online website
BrianBen
dark market tramadol dark web https://versusdarknet.com/ - bohemia market link
DamonPoday
best mdma vendor darknet market reddit french dark web https://asaponionmarket.com/ - blue lady e pill
EdgarFar
сайт мега мега вход https://hydramarket-darkweb.link/ - магазин мега
Dannymycle
buying things from darknet markets darknet drug market https://versusdarkmarketlink.com/ - hire an assassin dark web
Justinfluff
online onion market dark web links market https://asapdarknetdrugstore.com/ - cannahome market darknet
GeorgeThuth
dark markets france drug website dark web https://cannahomemarketplace24.com/ - darknet sites
CrisUnano
hacking tools darknet markets black market drugs guns https://wwwdarkmarket.com/ - darknet markets that take ethereum
Sirtob
legit darknet markets dark web drug marketplace https://asapdarkwebdrugstore.com/ - dark markets argentina
BrandenTap
зеркало мега сайты даркнет ссылки https://hydra-market-onion.link/ - mega сайт
MichaelSware
магазин мега зайти на мегу https://hydramarketdarknet.link/ - darknet магазин
Richardkeymn
как зайти на мегу mega магазин https://hydra-market-onion.link/ - сайт даркнет
Juliusbop
darknet markets list 2022 decabol pills https://versus-darkweb.com/ - site darknet market
CraigFaf
counterfeit money dark web reddit drugs on deep web https://asapmarketplacee.com/ - best darknet market australia
Randylog
darknet in person drug sales darkweb sites reddit https://versus-onion-market.com/ - wiki sticks drugs
CorryBoura
dark markets switzerland incognito link https://wwwdarknetmarket.link/ - darknet drugs india
HaroldImaby
deep dark web how to pay with bitcoin on dark web https://versusdarkweb.com/ - florida darknet markets
Robertket
mega onion зеркало ьупф ьфклуе https://hydramarket-online.link/ - мега ссылка
DanielEncon
darknet market deep dot web dark net markets https://asapdarknet.com/ - drug trading website
Jamesgox
dark markets germany Cocorico link https://dark-web-versus.com/ - tma drug
RobertGic
darknet markets for steroids dark web links adult https://darkmarket-asap.com/ - what is a darknet drug market like
BrandonTor
most popular darknet market deep web drug links https://darkmarketasap.com/ - best dark web links
Jamesopike
gray market place darknet adress https://asap-onion-darkmarket.com/ - darknet links 2022 drugs
Williamreoft
dark web markets 2022 australia darknet market wiki https://webdarknetmarkets.link/ - bitcoins and darknet markets
Davidmab
darknet market status darknet market arrests https://webdarknetmarkets.com/ - unicorn pill
Zacharyhet
darknet search engine url dark net market links 2022 https://versus-online-drugs.com/ - active darknet market urls
RandyZenny
uncensored hidden wiki link dark markets liechtenstein https://cannahomemarket-darknet.com/ - alphabay market url
WilliamBlade
cypher market link escrow market darknet https://asapmarket-darknet.com/ - decentralized darknet market
Torntow
tor2door market dark markets belgium https://wwwdarkmarket.shop/ - darknet drugs germany
JamesVet
dark websites reddit deep net access https://asap-darkweb.com/ - darknet markets ranked 2022
Donaldrhisp
asap market link deep web drug markets https://versus-drugs-online.com/ - dark web search engines link
HectorMug
мега сайт мега скорость https://hydramarket-online.link/ - магазин мега
Julianacunc
new darknet market reddit blockchain darknet markets https://aversus-market.com/ - darknet gun market
Ronaldimpak
versus project market darknet Kingdom Market link https://asapmarket-urll.com/ - Kingdom url
RichardCyday
darknet market search best darknet market 2022 reddit https://darkwebversus.com/ - darknet markets address
PatrickDuelp
best darknet markets duckduckgo onion site https://versus-dark-markett.com/ - dxm pills
CharlesGet
dark markets spain which darknet markets are still open https://darkweb-asap.com/ - how to buy from darknet markets
RalphusafT
tfmpp pills versus project market darknet https://asap-darknet.com/ - dark web marketplace
SteveNek
мега купить соль darknet магазин https://hydramarketdarkweb.link/ - магазины даркнета
MichaelCox
ссылка на мегу мэги сайт https://hydramarket-darknet.link/ - мега скорость
Frankcit
darkfox link darknet drugs dublin https://asap-marketplace.com/ - counterfeit money deep web
WilliamQuego
darkweb markets black market sites 2022 https://asapdarkmarketonline.com/ - black market bank account
JosephBok
how to order from dark web black market illegal drugs https://dark-market-versus.com/ - black market drugs guns
Granthub
how to use onion sites dark markets denmark https://asap-online-drugs.com/ - dark web counterfeit money
Geraldnob
darknet list best darknet market for weed https://asaponlinedrugs.com/ - deep web url links
ADangep
cypher market dark web prostitution https://aasap-market.com/ - url hidden wiki
HellySAr
dark markets albania dark markets serbia https://asap-darkmarket-online.com/ - deep web cc shop
Michaelhoise
deep net links guide to darknet markets https://versus-drugs-market.com/ - black market website
Jackiesix
мега onion оффициальный сайт магазин мега https://hydramarketdarkweb.link/ - мега кокаин
Charlesjerce
alphabay link reddit pyramid pill https://asap-drugs-online.com/ - best lsd darknet market
DavidMob
dark web search engines link dark markets albania https://asapdrugsmarketplace.com/ - 0day onion
DavidSig
underground website to buy drugs reddit best darknet market https://versus-darkmarket.com/ - how to create a darknet market
Jancib
darknet market sites and how to access phenylethylamine https://webdrugs-darknet.link/ - darknet drug market list
Timmylurry
darknet market lists darknet market bible https://versus-darknet-drugstore.com/ - current darknet market
ShaneLit
dark markets venezuela current darknet market https://asapmarket-url.com/ - darknet markets
JasonRab
market deep web 2022 dark web markets reddit 2022 https://versus-marketplace24.com/ - best darknet market for weed 2022
Hansmog
how to access deep web safely reddit new darknet marketplaces https://asap-darknet-drugstore.com/ - dark markets russia
BrianBen
vice city market link darknet market lists https://versusdarkmarketplace.com/ - darknet market vendor guide
Dannymycle
black market online website asap link https://versusdarkmarketonline.com/ - agora darknet market
EdgarFar
мега onion ссылка сайт даркнет https://hydramarket-darkweb.link/ - darknet магазин зелья
DamonPoday
tor dark web access darknet markets https://asaponionmarket.com/ - darknet market comparison
Justinfluff
dark markets bolivia best darknet market for weed 2022 https://asapdarkweb.com/ - darknet drugs guide
GeorgeThuth
black market prices for drugs tor darknet market https://cannahomemarketplace24.com/ - darknet drugs market
WendellEnaky
versus project market link wiki sticks drugs https://asap-onlinedrugs.com/ - deep web links 2022 reddit
MichaelSware
сайт даркнет mega сайт https://hydramarketdarknet.link/ - даркнет сайты магазин
BrandenTap
мега onion мега онион сайт https://hydra-market-onion.link/ - mega market
CrisUnano
darknet market noobs bible Kingdom Market link https://wwwdarkmarket.link/ - darknet markets list
Sirtob
black market cryptocurrency tor market links 2022 https://asapdarkwebdrugstore.com/ - dark web search engine 2022
Juliusbop
how to get on the dark web biggest darknet market https://versus-darkweb.com/ - tor market links
Richardkeymn
mega онион mega onion оффициальный сайт https://hydramarket-darknet.link/ - как зайти на мегу
CraigFaf
dark net markets cannazon market link https://asaponiondarkmarket.com/ - darknet market and monero
Smittjen
best deep web markets reddit darknet market list https://cannahome-darkweb-drugstore.com/ - dark web steroids
CorryBoura
darknet drug prices dark web drugs bitcoin https://wwwdarknetmarket.shop/ - cheap darknet websites dor drugs
BrandonTor
what is the best darknet market darknet market credit cards https://darkmarketversus.com/ - dark web drugs
RobertGic
darknet markets that take ethereum best darknet market for counterfeit https://darkmarket-asap.com/ - best darknet market for steroids
Randylog
versus project darknet market site onion liste https://versus-onion-market.com/ - Cocorico url
Jamesgox
cannahome market link darkfox market url https://dark-web-versus.com/ - current darknet market
Robertket
mega даркнет сайты даркнет https://hydramarket-online.link/ - мега сайт
DanielEncon
deep web links reddit 2022 onion link reddit https://asapdarknet.com/ - how to get on the dark web on laptop
RandyZenny
hidden wiki tor onion urls directories alphabay market net https://cypherdarkwebdrugstore.com/ - superman pills mg
Zacharyhet
Heineken Express darknet Market darknet drugs 2022 https://versus-online-drugs.com/ - exploit market darknet
Davidmab
dark markets singapore darknet market drug https://web-darknet-market.shop/ - top dumps shop
Williamreoft
dark web links 2022 tor link search engine https://webdrugs-darknet.com/ - darknet drug vendors
HaroldImaby
vice city market link darknet marketplace drugs https://versusdarkweb.com/ - drugs sold on dark web
Torntow
buying drugs on the darknet deep sea darknet market https://wwwdarkmarket.shop/ - best darknet market links
WilliamBlade
darkmarket link the dark web url https://asapmarket-darknet.com/ - Abacus Market
Donaldrhisp
darknet markets dynabolts pills https://versus-drugsonline.com/ - dark web market
JamesVet
duckduckgo dark web search darknet drug vendor that takes paypal https://asap-darkwebmarket.com/ - tor market
RichardCyday
archetyp link darkweb markets https://darkwebasap.com/ - live onion market
CharlesGet
dream market darknet darknet market reddit https://darkweb-asap.com/ - fresh onions link
PatrickDuelp
onion link search engine vice city market darknet https://versus-darkmarket-online.com/ - ketamine darknet market
HectorMug
mega onion оффициальный сайт mega onion shop https://hydramarket-online.link/ - мега сайт ссылка
SteveNek
мега onion ссылка мега официальный сайт https://hydramarketdarkweb.link/ - мега зеркало
Ronaldimpak
best dark web links top darknet market now https://asapmarket-urll.com/ - bitcoin darknet markets
RalphusafT
price of black market drugs what darknet markets are available https://asap-darkweb-drugstore.com/ - pax marketplace
Julianacunc
darknet market forum alphabay market url https://cannahome-marketplace.com/ - reddit where to buy drugs
Mattheworali
reddit darknet market superlist market street darknet https://versusdarkwebmarkett.com/ - buy drugs on darknet
Frankcit
buy real money buying drugs on the darknet https://asap-marketplace.com/ - what darknet markets sell fentanyl
HellySAr
which darknet market are still up darknet markets australia https://asap-darkmarket-online.com/ - dark markets united kingdom
ADangep
best darknet markets blacknet drugs https://aasap-market.com/ - 2022 darknet market
Granthub
escrow dark web dnm market https://asap-online-drugs.com/ - underground hackers black market
Timmylurry
best mdma vendor darknet market reddit deep market https://versus-darknet-drugstore.com/ - cannazon url
DavidSig
darknet markets deepdotweb dark market 2022 https://versus-darkmarket.com/ - how to access the dark web on pc
Michaelhoise
shop ccs carding dxm pills https://versus-darkwebmarket.com/ - buy real money
Jackiesix
ссылки на даркнет мега сайт https://hydramarketdarknet.link/ - mega сайт
Charlesjerce
darknet websites drugs best black market websites https://asap-drugs-online.com/ - current darknet markets
Jancib
drug trading website darknet credit card market https://webdrugs-darknet.link/ - deep web drugs
DavidMob
asap market url dark markets andorra https://asapdrugsmarket.com/ - bitcoin cash darknet markets
ShaneLit
bitcoin dark website online onion market https://asapmarket-url.com/ - darknet market oxycontin
JasonRab
drug market darknet darknet markets address https://versus-marketplace24.com/ - deep deep web links
Hansmog
dark markets belarus darknet market alphabay https://asap-darknet-drugstore.com/ - the darknet market reddit
BrianBen
darknet drug markets 2022 best dark web counterfeit money https://versusdarkmarketplace.com/ - credit card dumps dark web
Dannymycle
dark markets darknet market google https://versusdarkmarketlink.com/ - darknet drugs india
MichaelSware
mega onion как зайти на мегу https://hydramarketdarknet.link/ - darknet магазин зелья
EdgarFar
даркнет магазин mega onion оффициальный сайт https://hydramarket-darkweb.link/ - мега скорость
Justinfluff
deep web websites reddit Abacus Market https://asapdarkweb.com/ - uncensored hidden wiki link
GeorgeThuth
pyramid pill Abacus Market darknet https://cannahomemarketplace24.com/ - darknet market status
WendellEnaky
dark web links 2022 reddit onion sex shop https://asap-onlinedrugs.com/ - darknet market ranking
CrisUnano
phenazepam pills dark markets malta https://wwwdarkmarket.com/ - dark markets romania
Juliusbop
reddit darknet market guide dark markets bolivia https://versus-darkweb-drugstore.com/ - darknet market lightning network
Richardkeymn
mega onion зеркало мега onion зеркало https://hydra-market-onion.link/ - мега onion зеркало
Jamaal
Hello! Would you mind if I share your blog with my myspace group? There’s a lot of folks that I think would really enjoy your content. Please let me know. Thanks
CraigFaf
darknet market list url dark markets serbia https://asaponiondarkmarket.com/ - darknet guns market
BrandonTor
deep dot web replacement tor market list https://darkmarketasap.com/ - cannazon market darknet
CorryBoura
google black market darknet litecoin https://wwwdarknetmarket.shop/ - how to browse the dark web reddit
Smittjen
how to get to darknet market outlaw darknet market url https://asap-darkmarket.com/ - incognito market link
Randylog
darkfox darknet market asap market https://versus-onion-darkweb.com/ - darknet market sites and how to access
Jamesgox
darknet markets deepdotweb how to browse the dark web reddit https://dark-web-versus.com/ - darknet websites wiki
Robertket
ссылки на даркнет mega onion ссылка https://hydramarket-online.link/ - мега мефедрон
DanielEncon
darknet market list 2022 best market darknet drugs https://asapdarkmarketplace.com/ - drug markets dark web
RandyZenny
dark web site list deep dot web replacement https://cypherdarkwebdrugstore.com/ - darknet escrow
Jamesopike
darknet illegal market Kingdom url https://asap-onion-darkweb.com/ - darknet links market
PatrickDuelp
how to access the dark web 2022 Kingdom url https://versus-darkmarket-online.com/ - cannahome
HaroldImaby
how to buy things off the black market incognito link https://versusdarknetdrugstore.com/ - darknet onion markets
CharlesGet
dark markets monaco darknet seiten liste https://darkweb-versus.com/ - illegal black market
Zacharyhet
onion dark web list current list of darknet markets https://versus-online-drugs.com/ - cannazon darknet market
JamesVet
bitcoin market on darknet tor deep web onion url https://asap-darkwebmarket.com/ - versus project link
Torntow
black market sites 2022 alphabay link reddit https://wwwdarknetmarket.com/ - dnm market
Donaldrhisp
dark web steroids what is the best darknet market https://versus-drugsonline.com/ - dark markets brazil
WilliamBlade
dark markets guyana best current darknet market https://asapmarket-darknet.com/ - dark markets romania
RichardCyday
decabol pills darknet marketplace drugs https://darkwebasap.com/ - what is darknet markets
SteveNek
mega зеркало мега купить соль https://hydramarketdarkweb.link/ - даркнет сайты магазин
Ronaldimpak
tor link list 2022 search deep web engine https://asapmarketplace24.com/ - 2022 working darknet market
HectorMug
мега onion магазин mega onion ссылка https://hydramarket-darkweb.link/ - даркнет сайты магазин
RalphusafT
darknetlive dbol steroid pills https://asap-darkweb-drugstore.com/ - how to get to the black market online
HellySAr
cypher market best darknet market reddit 2022 https://asap-dark-market.com/ - darknet markets guide
ADangep
alphabay solutions reviews deep web search engine url https://aasap-market.com/ - darknet market canada
MichaelCox
mega онион сайт зайти на мегу https://hydramarket-darknet.link/ - darknet сайт
Timmylurry
dark markets serbia versus link https://versus-darknet.com/ - asap market link
DavidSig
cannahome market darknet which darknet market are still up https://versus-darkmarketplace.com/ - dark markets norge
JosephBok
what darknet markets still work r darknet market https://dark-market-asap.com/ - reddit darknet market deals
WilliamQuego
urls for darknet markets cypher url https://asapdarkmarketonline.com/ - dark web market links
Frankcit
market links darknet darknet market guide reddit https://asap-marketplace.com/ - deep market
Granthub
black market website names darknet markets 2022 reddit https://cannahomeoniondarkweb.com/ - reddit darknet market australia
Mattheworali
best darknet drug market 2022 dark markets bosnia https://versusdarkwebmarkett.com/ - reliable darknet markets
Michaelhoise
darknet cannabis markets darknet market guide https://versus-drugs-market.com/ - dark markets indonesia
Jancib
darknet bank accounts dark web hitman for hire https://webdrugs-darknet.shop/ - open darknet markets
DavidMob
dark web market list versus market https://asapdrugsmarketplace.com/ - darknet market iphone
Charlesjerce
0day onion reddit darknet market noobs bible https://asap-drugs-online.com/ - darknet market script
Jackiesix
ьупф ьфклуе магазин мега https://hydramarketdarknet.link/ - мега onion оффициальный сайт
ShaneLit
alphabay url darknet seiten https://asapmarket-url.com/ - dark web sites xxx
JasonRab
drugs dark web dark markets chile https://versus-onion-darkmarket.com/ - darknet market comparison chart
Hansmog
darknet markets reddit 2022 new onion darknet market https://asap-darknet-drugstore.com/ - tor2door market
BrianBen
xanax darknet reddit darknet gun market https://versusdarkmarketplace.com/ - how to darknet market
BrandenTap
мега сайт ссылка mega onion зеркала https://hydra-market-onion.link/ - мега нарко
Dannymycle
darknet drugs guide underground website to buy drugs https://versusdarkmarketlink.com/ - dark web market
MichaelSware
mega onion зеркало мега https://hydramarketdarknet.link/ - новое зеркало мега
EdgarFar
мега официальный сайт мега onion зеркала https://hydramarket-darkweb.link/ - мега сайт ссылка
GeorgeThuth
darknet seiten dream market the dark web links 2022 https://cannahomemarketplacee.com/ - site onion liste
Justinfluff
onion link reddit black market deep https://asapdarknetdrugstore.com/ - alphabay solutions reviews
WendellEnaky
dnm xanax drugs dark web https://asap-onlinedrugs.com/ - darknet drug markets
Juliusbop
darknet market francais the dark web url https://versus-darkweb.com/ - dark web address list
CrisUnano
reddit darknet markets list bohemia market url https://wwwdarkmarket.com/ - deep web marketplaces reddit
Sirtob
deep web cc sites dark web link https://asapdarkwebmarket.com/ - deep web search engines 2022
RobertGic
bitcoins and darknet markets best deep web markets https://darkmarket-asap.com/ - best current darknet market
CorryBoura
darknet drug markets 2022 dumps shop https://wwwdarknetmarket.link/ - urls for darknet markets
Richardkeymn
darknet магазин mega онион https://hydra-market-onion.link/ - мега наркотики
CraigFaf
updated darknet market links 2022 best market darknet drugs https://asaponiondarkmarket.com/ - asap darknet market
Smittjen
cypher darknet market currently darknet markets https://cannahome-darkweb-drugstore.com/ - best darknet market australia
Randylog
dread onion reliable darknet markets https://versus-onion-darkweb.com/ - darknet drug dealer
Jamesgox
euroguns deep web reliable darknet markets reddit https://dark-web-versus.com/ - crypto darknet drug shop
DanielEncon
working darknet markets 2022 wiki darknet market https://asapdarkmarketplace.com/ - cypher market url
Robertket
мега кокаин mega магазин https://hydramarket-online.link/ - даркнет магазин
HaroldImaby
legit darknet sites how to darknet market https://versusdarknetdrugstore.com/ - darknet drug links
PatrickDuelp
history of darknet markets dark markets usa https://versus-dark-markett.com/ - darknet reddit market pills
RandyZenny
tor markets links darknet market list https://cannahomemarket-darknet.com/ - how to get on the dark web android
Jamesopike
dark web markets reddit 2022 darknet escrow https://asap-onion-darkweb.com/ - darknet market links reddit
escolla
Global reports suggest that 40 98 of pregnant women have 25 OH D levels below 50 nmol L and 15 84 have levels below 25 nmol L 192, 193. <a href=https://clomida.com/>clomid in males</a> AND ONE THING I CAN T UNDERSTAND.
JamesVet
darknet market adderall prices dark web shop https://asap-darkwebmarket.com/ - black market access
Donaldrhisp
onion sex shop top darknet markets 2022 https://versus-drugsonline.com/ - dark markets south korea
CharlesGet
duckduckgo dark web search darknet drug prices https://darkweb-asap.com/ - darknet drugs germany
Torntow
darknet websites wiki credit card dark web links https://wwwdarknetmarket.com/ - deep web cc sites
WilliamBlade
tor top websites dread onion https://asapmarket-darknet.com/ - deep net websites
SteveNek
магазин мега мега магазин https://hydramarketdarkweb.link/ - сайт мега
RichardCyday
dark web electronics asap market https://darkwebversus.com/ - darknet markets australia
Zacharyhet
dark web search tool drug website dark web https://versus-onlinedrugs.com/ - the dark market
Ronaldimpak
dark web market Kingdom link https://asapmarket-urll.com/ - legit darknet markets
HectorMug
мэги сайт мега onion ссылка https://hydramarket-online.link/ - магазин даркнет
HellySAr
2022 darknet markets url hidden wiki https://asap-dark-market.com/ - how to access darknet market
ADangep
google black market deep web drug prices https://acannahome-market.com/ - deep web markets
RalphusafT
where to find darknet market links redit darknet markets florida https://asap-darkweb-drugstore.com/ - dark markets italy
DavidSig
darknet drugs 2022 what is darknet markets https://versus-darkmarketplace.com/ - dark web links reddit
Timmylurry
new dark web links archetyp darknet market https://versus-darknet.com/ - how to buy from darknet
MichaelCox
мега мефедрон мега ссылка https://hydramarket-darknet.link/ - mega onion ссылка
JosephBok
hacking tools darknet markets best darknet markets reddit https://dark-market-asap.com/ - darknet search engine
Frankcit
darknet litecoin best market darknet drugs https://asap-marketplace.com/ - dynabolts pills
Granthub
cannahome market link drugs on the dark web https://cannahomeoniondarkweb.com/ - how to buy bitcoin and use on dark web
Mattheworali
dark web sales naked lady ecstasy pill https://versusdarkwebmarkett.com/ - hire an assassin dark web
Jancib
dark markets macedonia archetyp url https://webdrugs-darknet.link/ - buy drugs online darknet
DavidMob
deep deep web links dark web website links https://asapdrugsmarketplace.com/ - dark web poison
Charlesjerce
darknet market prices how to anonymously use darknet markets https://asap-drugs-online.com/ - darknet markets noob
Jackiesix
сайт мега mega ссылка https://hydramarketdarknet.link/ - мега onion зеркало
ShaneLit
bohemia market darknet onion market url https://asapmarket-url.com/ - back market trustworthy
MichaelSware
мега onion зеркала даркнет ссылки https://hydramarketdarknet.link/ - даркнет магазин
JasonRab
berlin telegram group drugs weed darknet market https://versus-marketplace24.com/ - darknet market lightning network
BrandenTap
мега мефедрон как зайти на мегу https://hydra-market-onion.link/ - mega onion зеркало
Hansmog
drugs dark web dark web market place links https://asap-darknet-drugstore.com/ - darknet markets urls
BrianBen
darknet market arrests best websites dark web https://versusdarknet.com/ - darknet markets onion addresses
Dannymycle
darknet market status verified dark web links https://versusdarkmarketlink.com/ - how to get on the dark web on laptop
EdgarFar
сайт даркнет мега купить соль https://hydramarket-darkweb.link/ - mega даркнет
Justinfluff
dark web links market guide to using darknet markets https://asapdarknetdrugstore.com/ - legit darknet sites
GeorgeThuth
dark web market darknet markets still up https://cannahomemarketplacee.com/ - onion deep web search
Juliusbop
best darknet market for counterfeit darknet market dash https://versus-darkweb.com/ - reddit darknet markets list
WendellEnaky
buying on dark web how to browse the dark web reddit https://asap-onlinedrugs.com/ - incognito url
RobertGic
darknet escrow markets asap url https://darkmarket-versus.com/ - naked lady ecstasy pill
BrandonTor
best darknet market 2022 reddit black market drugs https://darkmarketversus.com/ - dn market
CrisUnano
black market net tormarket onion https://wwwdarkmarket.link/ - darknet adress
CorryBoura
tor marketplaces darknet market pills vendor https://wwwdarknetmarket.shop/ - dark web website links
Sirtob
versus project darknet market how to get to the black market online https://asapdarkwebdrugstore.com/ - dark markets philippines
Richardkeymn
мега нарко магазин мега https://hydra-market-onion.link/ - мега кокаин
CraigFaf
tor drugs drugs on deep web https://asaponiondarkmarket.com/ - biggest darknet market
Randylog
tor darknet best darknet market drugs https://versus-onion-market.com/ - tor drugs
Jamesgox
darknet drug markets 2022 onion links for deep web https://dark-web-versus.com/ - darknet market and monero
HaroldImaby
escrow dark web dark markets china https://versusdarknetdrugstore.com/ - black market access
DanielEncon
darknet market directory tor2door market link https://asapdarkmarketplace.com/ - dark markets macedonia
Robertket
мега onion зеркало магазин мега https://hydramarket-online.link/ - ссылка на мегу
PatrickDuelp
what darknet markets are available Heineken Express darknet https://versus-darkmarket-online.com/ - new darknet markets 2022
RandyZenny
how to access darknet markets asap market https://cypherdarkwebdrugstore.com/ - darknet black market list
Jamesopike
best darknet market urs uk darknet markets https://asap-onion-darkmarket.com/ - reddit darknet market deals
Donaldrhisp
reddit darknet market deals duckduckgo dark web search https://versus-drugsonline.com/ - dark web sites xxx
JamesVet
dark web illegal links darknet сайты список https://asap-darkwebmarket.com/ - black market deep
Torntow
darknet market security dark web drug markets https://wwwdarkmarket.shop/ - back market legit
CharlesGet
incognito market pax marketplace https://darkweb-asap.com/ - best website to buy cc
SteveNek
mega market мега наркотики https://hydramarketdarkweb.link/ - mega onion ссылка
WilliamBlade
best darknet markets for vendors incognito darknet market https://asapmarket-darknet.com/ - online black market electronics
RichardCyday
deep web drug markets active darknet markets 2022 https://darkwebversus.com/ - darknet links market
Zacharyhet
hidden uncensored wiki list of darknet markets 2022 https://versus-online-drugs.com/ - deep web deb
HectorMug
mega зеркало мега даркнет https://hydramarket-online.link/ - магазин мега
Timmylurry
buy drugs online darknet darknet drug prices uk https://versus-darknet-drugstore.com/ - dark web hitman
DavidSig
darknetlive deep net websites https://versus-darkmarketplace.com/ - best current darknet market
RalphusafT
how to buy drugs on the darknet darknet drugs sites https://asap-darknet.com/ - list of darknet markets reddit
JosephBok
how to dark web reddit best working darknet market 2022 https://dark-market-versus.com/ - darkweb market
MichaelCox
mega онион darknet магазин зелья https://hydramarket-darknet.link/ - мега кокаин
WilliamQuego
fresh onions link dark web vendors https://asapdarkmarket.com/ - tor market list
Mattheworali
cvv black market market links darknet https://versusdarkwebdrugstore.com/ - fake id onion
Michaelhoise
deep net access dark market list https://versus-darkwebmarket.com/ - darknet market dmt
Jancib
darknet xanax dark web prepaid cards reddit https://webdrugs-darknet.link/ - online black market uk
DavidMob
darknet markets best dark web counterfeit money https://asapdrugsmarketplace.com/ - darknet markets address
BrandenTap
мега официальный сайт мега шишки https://hydra-market-onion.link/ - darknet сайт
MichaelSware
ссылки на даркнет магазин мега https://hydramarketdarknet.link/ - mega сайт
Charlesjerce
tor search engine link darknet market oz https://asap-drugs-online.com/ - how to buy drugs on darknet
ShaneLit
dark net market counterfeit money onion https://asapmarket-linkk.com/ - current darknet market
Jackiesix
мега вход мега сайт ссылка https://hydramarketdarkweb.link/ - ссылка мега
JasonRab
darknet market place search darknet drug delivery https://versus-onion-darkmarket.com/ - Abacus darknet Market
Hansmog
accessing darknet market darknet market drug prices https://asap-darknet-drugstore.com/ - darkfox darknet market
Dannymycle
Heineken Express url tor link search engine https://versusdarkmarketonline.com/ - dark markets argentina
BrianBen
darkmarket link assassination market darknet https://versusdarknet.com/ - incognito market url
BrandonTor
dark web links 2022 reddit dark web trading https://darkmarketasap.com/ - reddit darknet market noobs
GeorgeThuth
bitcoin black market black market reddit https://cannahomemarketplacee.com/ - darknet onion links drugs
RobertGic
dark web login guide dark markets monaco https://darkmarket-versus.com/ - bitcoin cash darknet markets
Juliusbop
Kingdom Market link darknet bitcoin market https://versus-darkweb-drugstore.com/ - bitcoins and darknet markets
Justinfluff
cheap darknet websites dor drugs buying drugs on the darknet https://asapdarkweb.com/ - dark markets malta
EdgarFar
mega onion зеркала darknet магазин зелья https://hydramarket-darkweb.link/ - mega onion зеркало
WendellEnaky
how to access the dark web through tor black market websites credit cards https://asap-onion-market.com/ - working darknet market links
CorryBoura
dark markets chile escrow dark web https://wwwdarknetmarket.link/ - darknet market alaska
CrisUnano
darknet drugs sites best darknet market uk https://wwwdarkmarket.link/ - darknet website for drugs
Sirtob
best darknet market australia blue lady e pill https://asapdarkwebdrugstore.com/ - best website to buy cc
Richardkeymn
mega market мега официальный сайт https://hydramarket-darknet.link/ - мега мефедрон
CraigFaf
dark web drugs ireland darknet список сайтов https://asapmarketplacee.com/ - dark market sites
Smittjen
russian anonymous marketplace darknet seiten dream market https://asap-darkmarket.com/ - dark web store
Jamesgox
dark market reddit darknet links markets https://dark-web-asap.com/ - current list of darknet markets
HaroldImaby
darknet market francais ketamine darknet market https://versusdarkweb.com/ - drugs on the dark web
DanielEncon
darknet market avengers the dark web url https://asapdarkmarketplace.com/ - new alphabay darknet market
RandyZenny
darknet dream market link fake id onion https://cannahomemarket-darknet.com/ - how to access darknet markets
PatrickDuelp
what darknet markets are still up darknet wiki link https://versus-darkmarket-online.com/ - darknet escrow
Robertket
mega onion ссылка на мегу https://hydramarket-online.link/ - mega даркнет
Jamesopike
deep web links reddit 2022 dark web illegal links https://asap-onion-darkmarket.com/ - darknet markets japan
JamesVet
darknet market carding r darknet market https://asap-darkweb.com/ - how to access darknet markets
ADangep
adresse onion tor2door link https://acannahome-market.com/ - dark market list
HellySAr
darknet drug trafficking dark web links 2022 reddit https://asap-darkmarket-online.com/ - darknet market ranking
SteveNek
mega онион сайт mega даркнет https://hydramarketdarkweb.link/ - мега скорость
Torntow
darkweb marketplace legit darknet markets 2022 https://wwwdarkmarket.shop/ - dark websites
CharlesGet
dark web fake money darknet reinkommen https://darkweb-asap.com/ - ordering drugs on dark web
Timmylurry
what is the darknet market dark markets canada https://versus-darknet.com/ - darknet steroid markets
DavidSig
Kingdom Market link how to get on the dark web android https://versus-darkmarketplace.com/ - the darknet markets
RichardCyday
darknet market avengers live onion market https://darkwebversus.com/ - darknet market comparison chart
Ronaldimpak
access the dark web reddit drug trading website https://asapmarketplace24.com/ - dark markets ukraine
HectorMug
зеркало мега mega ссылка https://hydramarket-online.link/ - mega market
RalphusafT
step by step dark web cypher url https://asap-darknet.com/ - blackweb darknet market
WilliamQuego
darknet markets address superlist darknet markets https://asapdarkmarketonline.com/ - cypher market link
MichaelCox
мега onion ссылка ссылка на мегу https://hydramarket-darknet.link/ - mega onion
Frankcit
reddit darknet market uk dark net market list reddit https://asap-marketplace.com/ - dark net market
Granthub
reddit darknet market deals hire an assassin dark web https://asap-online-drugs.com/ - tor markets
MichaelSware
даркнет ссылки mega ссылка https://hydramarketdarknet.link/ - мега сайт ссылка
BrandenTap
mega onion shop мега onion зеркала https://hydra-market-onion.link/ - ьупф ьфклуе
Michaelhoise
new darknet markets 2022 vice city market darknet https://versus-darkwebmarket.com/ - tramadol dark web
Mattheworali
darknet market vendors search counterfeit money onion https://versusdarkwebmarkett.com/ - top 10 dark websites
Jancib
darknet links market how to enter the black market online https://webdrugs-darknet.link/ - darknet marketplace drugs
DavidMob
versus project market url darknet market script https://asapdrugsmarketplace.com/ - dark markets guyana
Charlesjerce
shop online without cvv code dark markets brazil https://asap-drugs-online.com/ - darknet drugs
ShaneLit
drugs on the darknet darknet drug prices https://asapmarket-url.com/ - deep web websites reddit
Jackiesix
сайт мега ьупф ьфклуе https://hydramarketdarkweb.link/ - мега наркотики
Hansmog
onion deep web search dark markets indonesia https://asap-darkmarketplace.com/ - drugs from darknet markets
Dannymycle
dark market link the armory tor url https://versusdarkmarketlink.com/ - top dark net markets
BrandonTor
how to get on the dark web top darknet markets https://darkmarketasap.com/ - darknet markets dread
RobertGic
buying drugs online best darknet markets https://darkmarket-versus.com/ - counterfeit money dark web reddit
BrianBen
dark markets moldova darkshades marketplace https://versusdarknet.com/ - onion market url
Juliusbop
darknet сайты список darknet market drug prices https://versus-darkweb.com/ - how to get access to darknet
CorryBoura
darknet drugs germany deep web deb https://wwwdarknetmarket.link/ - darknet market carding
GeorgeThuth
darknet market reddit 2022 deep dark web markets links https://cannahomemarketplace24.com/ - best onion sites 2022
EdgarFar
магазин мега мега нарко https://hydramarket-darkweb.link/ - mega onion ссылка
Justinfluff
darkweb market darknet prices https://asapdarkweb.com/ - the darknet drugs
WendellEnaky
hidden financial services deep web reddit darknet market guide https://asap-onion-market.com/ - onion sex shop
CrisUnano
deep web drugs darknet market buying mdma usa https://wwwdarkmarket.link/ - dark markets macedonia
Sirtob
site onion liste how to access dark net https://asapdarkwebmarket.com/ - black market dark web links
Richardkeymn
магазин мега mega магазин https://hydra-market-onion.link/ - mega onion ссылка
CraigFaf
dark markets ukraine darknet market list url https://asapmarketplacee.com/ - underground market place darknet
Smittjen
tor2door market bitcoin black market https://cannahome-darkweb-drugstore.com/ - black market net
Jamesgox
tor marketplace illegal black market https://dark-web-versus.com/ - dark web markets reddit
Randylog
archetyp market url onion linkek https://versus-onion-market.com/ - darknet market fake id
HaroldImaby
monero darknet market dark markets ecuador https://versusdarkweb.com/ - tor darknet market
HellySAr
how to access the dark web through tor redit safe darknet markets https://asap-dark-market.com/ - dark web drug marketplace
ADangep
tor market links 2022 tor markets links https://aasap-market.com/ - live dark web
DanielEncon
biggest darknet market 2022 access the dark web reddit https://asapdarkmarketplace.com/ - best lsd darknet market
RandyZenny
darknet market security darknet onion markets https://cannahomemarket-darknet.com/ - darknet markets most popular
Donaldrhisp
how to use deep web on pc online black market electronics https://versus-drugs-online.com/ - reddit darknet markets list
PatrickDuelp
buying drugs off darknet dark web illegal links https://versus-darkmarket-online.com/ - tor market links
JamesVet
underground market place darknet new dark web links https://asap-darkwebmarket.com/ - darknet drugs australia
Robertket
мега магазин новое зеркало мега https://hydramarket-online.link/ - mega onion shop
Jamesopike
darknet database market drug market darknet https://asap-onion-darkweb.com/ - dark web sites name list
Timmylurry
darknet market bitcoin black market https://versus-darknet.com/ - cannazon link
DavidSig
xanax on darknet darknet markets 2022 https://versus-darkmarketplace.com/ - darknet market directory
WilliamBlade
darknet seiten liste guns dark market https://asapdrugsonline.com/ - buds express
SteveNek
mega зеркало даркнет сайты магазин https://hydramarketdarkweb.link/ - ссылка мега
CharlesGet
versus market darknet reddit best darknet market https://darkweb-versus.com/ - reddit darknet market how to
Ronaldimpak
best dark web links black market net https://asapmarket-urll.com/ - darkmarket link
RichardCyday
current best darknet market adress darknet https://darkwebasap.com/ - dark web sites name list
Zacharyhet
step by step dark web darknet markets with tobacco https://versus-online-drugs.com/ - black market url deep web
HectorMug
darknet сайт mega сайт https://hydramarket-online.link/ - даркнет сайты магазин
RalphusafT
versus market open darknet markets https://asap-darkweb-drugstore.com/ - drug trading website
JosephBok
cypher link best dark web search engine link https://dark-market-asap.com/ - the darknet market reddit
WilliamQuego
darknet market fake id darknet steroid markets https://asapdarkmarketonline.com/ - best darknet market for steroids
MichaelCox
мега купить соль mega onion shop https://hydramarket-darknet.link/ - мега зеркало
MichaelSware
ьупф ьфклуе mega onion shop https://hydramarketdarknet.link/ - mega сайт
Frankcit
darknet reddit market pills darknet market litecoin https://asap-drugsonline.com/ - black market sites 2022
Granthub
dark markets korea darknet market noobs step by step https://cannahomeoniondarkweb.com/ - dark markets monaco
Michaelhoise
darknet market comparison chart darknet markets financial times https://versus-drugs-market.com/ - australian dark web vendors
Mattheworali
dark markets belgium dark markets chile https://versusdarkwebmarkett.com/ - weed only darknet market
Jancib
new darknet markets 2022 drugs onion https://webdrugs-darknet.link/ - how to pay with bitcoin on dark web
DavidMob
shop valid cvv search deep web engine https://asapdrugsmarket.com/ - how to use darknet markets
Charlesjerce
dark markets ukraine open darknet markets https://asap-drugs-online.com/ - onion deep web wiki
BrandonTor
darknet database market darknet market security https://darkmarketasap.com/ - dark market sites
RobertGic
dark web prepaid cards reddit deep web onion url https://darkmarket-versus.com/ - darknet illegal market
Jackiesix
мега onion мега ссылка https://hydramarketdarknet.link/ - mega onion оффициальный сайт
Hansmog
dark web shopping dark markets monaco https://asap-darknet-drugstore.com/ - the dark web url
Dannymycle
onion market bohemia url https://versusdarkmarketonline.com/ - drugs on the darknet
JasonRab
darknet illicit drugs darknet search engine https://versus-onion-darkmarket.com/ - black market online website
Juliusbop
darknet markets that take ethereum tor darknet markets https://versus-darkweb.com/ - darknet markets fake id
BrianBen
black market drugs guns Abacus Market https://versusdarkmarketplace.com/ - active darknet markets
CorryBoura
ordering drugs on dark web darkmarkets https://wwwdarknetmarket.link/ - dark markets russia
GeorgeThuth
2022 working darknet market deep web markets https://cannahomemarketplacee.com/ - onion dark web list
Justinfluff
dark markets russia top darknet market now https://asapdarknetdrugstore.com/ - darknet market directory
EdgarFar
мега onion мега онион https://hydramarket-darkweb.link/ - даркнет сайты магазин
WendellEnaky
incognito market link deep web links updated https://asap-onlinedrugs.com/ - tor websites reddit
CrisUnano
darknet stock market asap url https://wwwdarkmarket.com/ - archetyp darknet market
Sirtob
darkweb markets onion link search engine https://asapdarkwebmarket.com/ - cypher url
Richardkeymn
mega ссылка мега ссылка https://hydra-market-onion.link/ - мега сайт
CraigFaf
archetyp market darknet dark markets norge https://asaponiondarkmarket.com/ - buying from darknet market with electrum
Smittjen
dark web cheap electronics darknet onion markets https://asap-darkmarket.com/ - verified darknet market
BrandenTap
официальный сайт мега мега купить https://hydra-market-onion.link/ - мега нарко
ADangep
free deep web links dark markets malta https://aasap-market.com/ - illegal black market
HellySAr
incognito url tor search engine link https://asap-dark-market.com/ - dxm pills
Randylog
bitcoins and darknet markets how to buy drugs dark web https://versus-onion-market.com/ - cannahome darknet market
HaroldImaby
the darknet market reddit cannazon https://versusdarknetdrugstore.com/ - new darknet marketplaces
DanielEncon
darknet market dash darknet market list links https://asapdarknet.com/ - dot onion websites
Donaldrhisp
dark web cvv tor search onion link https://versus-drugsonline.com/ - dark web store
DavidSig
dark markets colombia how to dark web reddit https://versus-darkmarket.com/ - darknet market noobs step by step
Timmylurry
marijuana dark web cannazon market darknet https://versus-darknet.com/ - bitcoin dark web
RandyZenny
how to dark web reddit darknet markets still up https://cypherdarkwebdrugstore.com/ - darknet market litecoin
JamesVet
darkmarkets bohemia url https://asap-darkweb.com/ - how to access the dark web through tor
Jamesopike
best darknet gun market dark web drug marketplace https://asap-onion-darkmarket.com/ - darknet market bust
Robertket
как зайти на мегу mega ссылка https://hydramarket-online.link/ - мега onion оффициальный сайт
Torntow
top 10 dark web url back market legit https://wwwdarknetmarket.com/ - asap url
CharlesGet
phenylethylamine deep web links reddit https://darkweb-versus.com/ - dark web website links
WilliamBlade
top ten dark web darknet markets dread https://asapdrugsonline.com/ - top dark net markets
SteveNek
мега мефедрон мега onion зеркало https://hydramarketdarkweb.link/ - мега онион
PatrickDuelp
dark markets ireland the real deal market darknet https://versus-darkmarket-online.com/ - how to browse the dark web reddit
Ronaldimpak
black market prescription drugs darknet site https://asapmarket-urll.com/ - darknet site
RichardCyday
bitcoin black market darknet market drug https://darkwebasap.com/ - current darknet market list
Zacharyhet
deep web search engines 2022 bitcoin dark website https://versus-onlinedrugs.com/ - dark web hitman
HectorMug
сылка на мегу мега скорость https://hydramarket-darkweb.link/ - mega магазин
RalphusafT
largest darknet market tor drugs https://asap-darknet.com/ - darknet prices
JosephBok
dark markets ecuador dark web illegal links https://dark-market-versus.com/ - buying credit cards on dark web
WilliamQuego
darknet links markets hitman for hire dark web https://asapdarkmarketonline.com/ - black market buy online
Frankcit
darknet drugs australia what darknet market to use now https://asap-drugsonline.com/ - darknet markets deepdotweb
MichaelSware
mega market мега даркнет https://hydramarketdarknet.link/ - darknet магазин зелья
MichaelCox
mega онион сайт мега официальный сайт https://hydramarket-darknet.link/ - mega onion оффициальный сайт
Granthub
working darknet markets Abacus link https://asap-online-drugs.com/ - dark net market list
Michaelhoise
black market prescription drugs darkmarket website https://versus-darkwebmarket.com/ - darknet best drugs
Mattheworali
reddit darknet market links cp links dark web https://versusdarkwebdrugstore.com/ - dark markets ukraine
Jancib
i2p darknet markets how to buy bitcoin and use on dark web https://webdrugs-darknet.shop/ - darknet drug market
DavidMob
what darknet markets are still up top dumps shop https://asapdrugsmarket.com/ - asap market link
BrandonTor
shop valid cvv darknet gun market https://darkmarketasap.com/ - carding deep web links
RobertGic
project versus dark web links https://darkmarket-versus.com/ - 2022 darknet markets
Charlesjerce
reddit darknet market uk top dumps shop https://asap-drugs-online.com/ - dark web live
ShaneLit
where to find darknet market links deep web links updated https://asapmarket-url.com/ - Kingdom Market url
Juliusbop
dark web sites links dark web login guide https://versus-darkweb-drugstore.com/ - redit safe darknet markets
Jackiesix
мега купить mega onion shop https://hydramarketdarkweb.link/ - мега магазин
Hansmog
working darknet market links how to get to darknet market safe https://asap-darknet-drugstore.com/ - what darknet market to use now
Dannymycle
drugs dark web price how to get access to darknet https://versusdarkmarketonline.com/ - black market net
JasonRab
dark market links deep web links reddit 2022 https://versus-onion-darkmarket.com/ - buying drugs on darknet reddit
CorryBoura
darkfox link darknet market reddit 2022 https://wwwdarknetmarket.shop/ - black market reddit
BrianBen
what darknet markets are up dark markets argentina https://versusdarkmarketplace.com/ - how to buy drugs on the darknet
Davidmab
reddit darknet reviews darknet link drugs https://web-darknet-market.shop/ - popular dark websites
Williamreoft
top dark net markets online black market electronics https://webdrugs-darknet.com/ - tor market nz
DamonPoday
trusted darknet markets search deep web engine https://asaponionmarket.com/ - darknet markets wax weed
Geraldnob
best tor marketplaces how to get on darknet market https://asapurl.com/ - online onion market
GeorgeThuth
dark markets 2022 dark web buy bitcoin https://cannahomemarketplacee.com/ - darknet marketplace
Hilltob
what darknet market to use now deep web updated links https://web-darknet-market.com/ - darknet market dash
Julianacunc
bohemia market darknet best darknet market links https://aversus-market.com/ - dark markets moldova
EdgarFar
mega onion мега магазин https://hydramarket-darkweb.link/ - mega market
WendellEnaky
darknet market oxycontin wired darknet markets https://asap-onlinedrugs.com/ - black market website names
Sirtob
darknet market oxycontin how to access the dark web 2022 https://asapdarkwebmarket.com/ - darknet bank accounts
CraigFaf
incognito darknet market best card shops https://asapmarketplacee.com/ - vice city market link
Richardkeymn
ссылки на даркнет магазины даркнета https://hydra-market-onion.link/ - mega даркнет
Jamesgox
darknet market buying mdma usa what is escrow darknet markets https://dark-web-asap.com/ - current darknet market
ADangep
buy bank accounts darknet tor dark web https://aasap-market.com/ - dark web markets
HellySAr
tor2door market darknet dark web links 2022 https://asap-dark-market.com/ - good dark web search engines
Smittjen
asap market url dark markets philippines https://asap-darkmarket.com/ - onion tube porn
BrandenTap
зеркало мега даркнет сайты магазин https://hydra-market-onion.link/ - новое зеркало мега
Randylog
how to search the dark web reddit best darknet market for guns https://versus-onion-market.com/ - darkfox market link
Timmylurry
oniondir deep web link directory darkweb market https://versus-darknet.com/ - guide to using darknet markets
HaroldImaby
deep website search engine dark web xanax https://versusdarkweb.com/ - darknet new market link
Donaldrhisp
reddit darknet markets links black market net https://versus-drugsonline.com/ - which darknet market are still up
DanielEncon
darkweb markets best darknet marketplaces https://asapdarknet.com/ - australian darknet markets
RandyZenny
dark web xanax reddit darknet market australia https://cypherdarkwebdrugstore.com/ - darkweb marketplace
Jamesopike
darknet market busts darkmarket url https://asap-onion-darkmarket.com/ - darknet vendor reviews
Robertket
mega зеркало mega онион https://hydramarket-online.link/ - ьупф ьфклуе
Torntow
dread onion reddit biggest darknet market place https://wwwdarknetmarket.com/ - deep dark web
CharlesGet
darknet market vendor guide how to install deep web https://darkweb-versus.com/ - dark markets moldova
WilliamBlade
dark markets usa deep web directory onion https://asapmarket-darknet.com/ - versus project link
Hilltob
dark markets montenegro top dark net markets https://web-darknet-market.link/ - onion links credit card
SteveNek
мега зеркало сылка на мегу https://hydramarketdarkweb.link/ - мега onion зеркало
PatrickDuelp
tma drug dark web counterfeit money https://versus-dark-markett.com/ - reddit darknetmarket
Zacharyhet
darknet marketplace wiki darknet market https://versus-online-drugs.com/ - archetyp market link
RichardCyday
wiki sticks drugs best darknet market for heroin https://darkwebversus.com/ - black market websites 2022
HectorMug
ссылка на мегу мега нарко https://hydramarket-darkweb.link/ - сайты даркнет
RalphusafT
buy bank accounts darknet asap darknet market https://asap-darknet.com/ - ruonion
Ronaldimpak
buy ssn dob with bitcoin escrow market darknet https://asapmarket-urll.com/ - active darknet market urls
JosephBok
dark web step by step darknet market links https://dark-market-versus.com/ - onion tube porn
WilliamQuego
list of darknet markets 2022 darknet market 2022 reddit https://asapdarkmarketonline.com/ - tor search onion link
MichaelCox
мега onion зеркала ссылка на мегу https://hydramarket-darknet.link/ - mega onion shop
Frankcit
darknet drug markets best darknet drug market 2022 https://asap-marketplace.com/ - top dark net markets
Michaelhoise
reddit darknet markets list cannazon market darknet https://versus-drugs-market.com/ - how to buy from darknet
Granthub
dark markets italy cheap darknet websites dor drugs https://asap-online-drugs.com/ - darknet drugs price
MichaelSware
мега onion магазин mega onion shop https://hydramarketdarknet.link/ - мега onion
Mattheworali
trusted darknet markets deep web market links reddit https://versusdarkwebdrugstore.com/ - hidden uncensored wiki
RobertGic
dark web search engines link site darknet liste https://darkmarket-versus.com/ - darknet telegram group
BrandonTor
dark web market russian anonymous marketplace https://darkmarketversus.com/ - onion darknet market
Jancib
dark web sites name list darknet market https://webdrugs-darknet.shop/ - darknet drugs germany
DavidMob
darknet drugs url dark web market reviews https://asapdrugsmarketplace.com/ - onionhub
Charlesjerce
deep dot web markets how to anonymously use darknet markets https://asap-drugs-market.com/ - onion links credit card
ShaneLit
how to buy drugs on the darknet how to access the dark web 2022 https://asapmarket-linkk.com/ - dark web sites for drugs
Juliusbop
darknet best drugs darkmarket https://versus-darkweb-drugstore.com/ - reddit where to buy drugs
Jackiesix
mega даркнет официальный сайт мега https://hydramarketdarkweb.link/ - мега onion зеркало
Hansmog
best darknet drug market 2022 best darknet markets uk https://asap-darknet-drugstore.com/ - open darknet markets
CorryBoura
deep web links reddit 2022 black market access https://wwwdarknetmarket.shop/ - black market drugs
Dannymycle
darknet markets australia how to create a darknet market https://versusdarkmarketlink.com/ - dark markets austria
JasonRab
uk darknet markets dark markets luxembourg https://versus-marketplace24.com/ - the dark web links 2022
BrianBen
how to access deep web safely reddit deep web drugs reddit https://versusdarknet.com/ - versus project link
DamonPoday
tor onion search shop valid cvv https://asaponiondarkweb.com/ - dream market darknet url
Justinfluff
wiki darknet market alphabay url https://asapdarkweb.com/ - fresh onions link
GeorgeThuth
tor dark web darknet seiten dream market https://cannahomemarketplace24.com/ - which darknet markets are still open
EdgarFar
сайт мега даркнет ссылки https://hydramarket-darkweb.link/ - сайты даркнет
WendellEnaky
best dark web counterfeit money pax marketplace https://asap-onlinedrugs.com/ - darknet drug vendor that takes paypal
Williamreoft
alpha market url bitcoin drugs market https://webdarknetmarkets.link/ - darknet new market link
Davidmab
darknet websites drugs best darknet markets uk https://webdarknetmarkets.com/ - tor search onion link
CrisUnano
darknet market xanax how to browse the dark web reddit https://wwwdarkmarket.com/ - cp onion
Jamesgox
darknet drugs shipping darknet market list reddit https://dark-web-versus.com/ - anadrol pills
CraigFaf
alphabay market darknet drug trafficking https://asapmarketplacee.com/ - what darknet markets are available
ADangep
darknet market pills vendor deep web onion url https://acannahome-market.com/ - where to find onion links
HellySAr
dark net market links 2022 darknet market wiki https://asap-dark-market.com/ - darknet market arrests
Richardkeymn
mega onion мега ссылка https://hydramarket-darknet.link/ - мега сайт
Smittjen
underground market online onion link search engine https://asap-darkmarket.com/ - dark web drugs
DavidSig
good dark web search engines tor darknet market address https://versus-darkmarketplace.com/ - darknet drug prices
Timmylurry
top 10 dark websites onion seiten 2022 https://versus-darknet.com/ - link de hiden wiki
BrandenTap
darknet магазин зелья магазин мега https://hydra-market-onion.link/ - mega ссылка
Randylog
onion deep web search cannahome https://versus-onion-darkweb.com/ - best darknet market now
HaroldImaby
darknet market bible dark markets macedonia https://versusdarkweb.com/ - cheapest drugs on darknet
Donaldrhisp
onion directory 2022 tor market list https://versus-drugs-online.com/ - dark markets finland
JamesVet
Heineken Express darknet Market darknet markets for steroids https://asap-darkweb.com/ - reddit darknet market list
DanielEncon
dark market 2022 bitcoin dark web https://asapdarkmarketplace.com/ - deep net links
RandyZenny
monkey x pill versus market url https://cypherdarkwebdrugstore.com/ - darknet market deep dot web
Jamesopike
good dark web search engines adresse onion https://asap-onion-darkmarket.com/ - dark markets malta
Torntow
bitcoin cash darknet markets Heineken Express darknet https://wwwdarkmarket.shop/ - reddit darknet market list 2022
Robertket
darknet сайт мега кокаин https://hydramarket-online.link/ - мега сайт ссылка
CharlesGet
dark web links reddit underground card shop https://darkweb-versus.com/ - what darknet markets still work
WilliamBlade
2022 working darknet market darknet market news https://asapmarket-darknet.com/ - verified darknet market
SteveNek
мега кокаин мэги сайт https://hydramarketdarkweb.link/ - даркнет сайты магазин
PatrickDuelp
darknet drugs malayisa monero darknet market https://versus-dark-markett.com/ - dark markets uk
RalphusafT
guide to using darknet markets tor search engine link https://asap-darkweb-drugstore.com/ - onion directory
HectorMug
мега кокаин мега купить https://hydramarket-online.link/ - мега зеркало
Ronaldimpak
cannazon market link deep web links updated https://asapmarketplace24.com/ - reddit darknet markets links
Zacharyhet
drugs on the dark web brucelean darknet market https://versus-online-drugs.com/ - cannabis dark web
JosephBok
tfmpp pills best dark net markets https://dark-market-asap.com/ - darknet market dmt
WilliamQuego
deep web software market live onion market https://asapdarkmarketonline.com/ - darknet market bust
BrandonTor
dark web links 2022 reddit top darknet market 2022 https://darkmarketasap.com/ - how to find the black market online
RobertGic
price of black market drugs dark market sites https://darkmarket-asap.com/ - darknet market links 2022
Frankcit
best dark web marketplaces 2022 decentralized darknet market https://asap-drugsonline.com/ - dark markets bolivia
Michaelhoise
market onion counterfeit money onion https://versus-darkwebmarket.com/ - darknet market pills vendor
MichaelSware
mega онион сылка на мегу https://hydramarketdarknet.link/ - мега нарко
Granthub
dark markets korea reddit best darknet markets https://asap-online-drugs.com/ - darknet websites list 2022
Mattheworali
darknet in person drug sales black market website https://versusdarkwebdrugstore.com/ - adresse onion black market
MichaelCox
мега сайт зайти на мегу https://hydramarket-darknet.link/ - мега нарко
Jancib
Cocorico Market link dark web sites name list https://webdrugs-darknet.shop/ - online black market uk
DavidMob
best darknet market reddit 2022 dark markets switzerland https://asapdrugsmarket.com/ - darknet black market
Juliusbop
darknet new market link tor markets 2022 https://versus-darkweb-drugstore.com/ - buds express
Charlesjerce
versus darknet market deep web link 2022 https://asap-drugs-market.com/ - best fraud market darknet
ShaneLit
drug market biggest darknet markets https://asapmarket-url.com/ - darknet market search engine
Jackiesix
магазины даркнета mega магазин https://hydramarketdarknet.link/ - darknet магазин
Dannymycle
darknet drugs url darknet market oz https://versusdarkmarketlink.com/ - deep onion links
JasonRab
best darknet market for steroids active darknetmarkets https://versus-onion-darkmarket.com/ - dark markets indonesia
BrianBen
darknet sites url buying drugs online on openbazaar https://versusdarknet.com/ - darkmarket website
GeorgeThuth
darknet prices archetyp market link https://cannahomemarketplacee.com/ - dynabolts pills
Justinfluff
best darknet market links darknet new market link https://asapdarknetdrugstore.com/ - best darknet markets
EdgarFar
мега onion зеркало mega onion https://hydramarket-darkweb.link/ - как зайти на мегу
WendellEnaky
darkweb marketplace where to find darknet market links https://asap-onlinedrugs.com/ - tor marketplace
CrisUnano
darknet market buying mdma usa dark web login guide https://wwwdarkmarket.link/ - carding dark web
Jamesgox
darknet market iphone Heineken Express darknet https://dark-web-versus.com/ - grey market darknet
ADangep
tor2door market darknet dark markets slovenia https://acannahome-market.com/ - dark web cvv
HellySAr
drugs on darknet australian darknet vendors https://asap-darkmarket-online.com/ - illegal black market
Sirtob
how to access the dark web reddit trusted darknet markets https://asapdarkwebdrugstore.com/ - darknet live markets
CraigFaf
darknet market steroids archetyp market https://asapmarketplacee.com/ - dark web website links
DavidSig
dark markets ecuador alpha market url https://versus-darkmarketplace.com/ - deep web links reddit 2022
Timmylurry
darknet markets onion addresses cannazon market https://versus-darknet-drugstore.com/ - dark markets finland
Richardkeymn
mega онион сайт mega зеркало https://hydramarket-darknet.link/ - mega onion зеркало
Smittjen
darknet market onions australian darknet vendors https://cannahome-darkweb-drugstore.com/ - deep web drug store
BrandenTap
мега сайт ссылка мега сайт https://hydra-market-onion.link/ - официальный сайт мега
Randylog
dark web uk dark markets united kingdom https://versus-onion-market.com/ - darknet market sites
HaroldImaby
cannahome market url cannahome market darknet https://versusdarknetdrugstore.com/ - darknet paypal accounts
Donaldrhisp
darknet market dark web step by step https://versus-drugs-online.com/ - versus darknet market
JamesVet
active darknet market urls darknet market reddit https://asap-darkweb.com/ - darknet markets most popular
DanielEncon
darknet websites wiki best darknet gun market https://asapdarkmarketplace.com/ - drugs on the darknet
RandyZenny
black market websites tor darknet markets 2022 updated https://cannahomemarket-darknet.com/ - dark chart
Jamesopike
reddit biggest darknet market place tor2door link https://asap-onion-darkweb.com/ - dark markets albania
Torntow
darknet market get pills darknet markets with tobacco https://wwwdarkmarket.shop/ - archetyp market
Robertket
мега наркотики магазины даркнета https://hydramarket-online.link/ - darknet магазин
CharlesGet
guide to using darknet markets adresse dark web https://darkweb-versus.com/ - darknet telegram group
WilliamBlade
black market credit card dumps best australian darknet market https://asapmarket-darknet.com/ - dark web electronics
SteveNek
мега скорость ссылки на даркнет https://hydramarketdarkweb.link/ - мега сайт ссылка
Ronaldimpak
reliable darknet markets lsd dark web sites drugs https://asapmarket-urll.com/ - deep web cc shop
RalphusafT
darknet drugs reddit how to buy from darknet https://asap-darknet.com/ - hitman for hire dark web
Zacharyhet
darknet drug markets carding dark web https://versus-onlinedrugs.com/ - darknet drug dealer
HectorMug
мега онион сайт мега онион сайт https://hydramarket-online.link/ - мега онион
PatrickDuelp
buy real money dark markets france https://versus-darkmarket-online.com/ - the onion directory
RobertGic
best website to buy cc core market darknet https://darkmarket-versus.com/ - brick market
BrandonTor
reddit darknet markets 2022 darknet markets best https://darkmarketasap.com/ - tor market list
RichardCyday
list of darknet markets reddit counterfeit money dark web reddit https://darkwebversus.com/ - best australian darknet market
WilliamQuego
Cocorico Market darknet drug market list https://asapdarkmarketonline.com/ - alphabay market darknet
Michaelhoise
legit darknet sites darknet markets that take ethereum https://versus-drugs-market.com/ - where to find onion links
Frankcit
dark markets latvia how to get access to darknet https://asap-marketplace.com/ - dark web search engines link
Mattheworali
reddit darknet markets uk darknet link drugs https://versusdarkwebdrugstore.com/ - deep web drugs reddit
Granthub
how to buy from the darknet markets lsd onion directory https://cannahomeoniondarkweb.com/ - drugs darknet vendors
MichaelSware
мега onion мэги сайт https://hydramarketdarknet.link/ - mega онион
MichaelCox
мега даркнет мега onion ссылка https://hydramarket-darknet.link/ - мега даркнет
Juliusbop
onion market dark markets croatia https://versus-darkweb.com/ - step by step dark web
DavidMob
darknet market updates 2022 best darknet market 2022 reddit https://asapdrugsmarket.com/ - counterfeit money onion
CorryBoura
Heineken Express darknet Market incognito market url https://wwwdarknetmarket.shop/ - tor top websites
ShaneLit
tor marketplace darknet wiki link https://asapmarket-url.com/ - darknet xanax
Charlesjerce
darknet black market list how to buy from darknet markets https://asap-drugs-online.com/ - Cocorico darknet Market
Dannymycle
top ten dark web the darknet drugs https://versusdarkmarketlink.com/ - bohemia market url
Jackiesix
мега официальный сайт ьупф ьфклуе https://hydramarketdarknet.link/ - мега официальный сайт
Hansmog
dark web engine search links the hidden wiki https://asap-darkmarketplace.com/ - best working darknet market 2022
JasonRab
how to use deep web on pc wikipedia darknet market https://versus-marketplace24.com/ - darkweb markets
DamonPoday
darknet drugs links versus market darknet https://asaponionmarket.com/ - what are darknet drug markets
Julianacunc
dark markets russia new darknet markets https://aversus-market.com/ - reddit darknet market uk
Geraldnob
dark websites reddit the best onion sites https://asaponlinedrugs.com/ - onion links credit card
BrianBen
onion domain and kingdom euroguns deep web https://versusdarkmarketplace.com/ - darknet prices
Justinfluff
best darknet market for guns dark web link https://asapdarkweb.com/ - the armory tor url
GeorgeThuth
best darknet markets for vendors darknet illegal market https://cannahomemarketplacee.com/ - dark markets norway
ADangep
deep web drug url tor best websites https://acannahome-market.com/ - guide to using darknet markets
HellySAr
darknet drugs links dark web market list https://asap-darkmarket-online.com/ - darknet selling drugs
WendellEnaky
best darknet market for weed uk reliable darknet markets https://asap-onlinedrugs.com/ - best working darknet market 2022
EdgarFar
сайты даркнет ссылки мэги сайт https://hydramarket-darkweb.link/ - даркнет ссылки
CrisUnano
wiki darknet market buy bank accounts darknet https://wwwdarkmarket.com/ - best dark web marketplaces 2022
Jamesgox
which darknet markets accept zcash darknet prices https://dark-web-versus.com/ - darknet drug market list
Timmylurry
darknet markets list 2022 onion links credit card https://versus-darknet.com/ - best dark web search engine link
DavidSig
ordering drugs on dark web where to find darknet market links https://versus-darkmarket.com/ - darknet drug trafficking
Sirtob
best deep web markets asap market link https://asapdarkwebmarket.com/ - Heineken Express Market
CraigFaf
dark markets turkey largest darknet market https://asapmarketplacee.com/ - darknet illegal market
BrandenTap
зайти на мегу mega даркнет https://hydra-market-onion.link/ - ьупф ьфклуе
Smittjen
reddit darknet market how to darknet market drug https://cannahome-darkweb-drugstore.com/ - dark web vendors
JamesVet
darknet market controlled delivery dark net market list reddit https://asap-darkweb.com/ - dark web electronics
HaroldImaby
darknet market that has ssn database counterfeit euro deep web https://versusdarkweb.com/ - deep web hitmen url
Donaldrhisp
uncensored hidden wiki link dark markets portugal https://versus-drugs-online.com/ - deep web directory onion
Randylog
anadrol pills drugs on the deep web https://versus-onion-darkweb.com/ - darknet sites url
RandyZenny
biggest darknet market darknet market alaska https://cannahomemarket-darknet.com/ - escrow market darknet
DanielEncon
dark markets albania darknet drugs market https://asapdarkmarketplace.com/ - site darknet onion
Justinfluff
cannahome market darknet darknet telegram group https://asapdarknetdrugstore.com/ - deep onion links
GeorgeThuth
Abacus Market darknet how to access the dark web safely reddit https://cannahomemarketplace24.com/ - best darknet market for counterfeit
Julianacunc
ruonion site darknet liste https://aversus-market.com/ - tor best websites
BrianBen
archetyp url darknet market fake id https://versusdarknet.com/ - urls for darknet markets
WendellEnaky
2022 darknet market the real deal market darknet https://asap-onion-market.com/ - online onion market
CrisUnano
cannahome url darknet markets still open https://wwwdarkmarket.com/ - Abacus link
EdgarFar
mega onion оффициальный сайт мега сайт https://hydramarket-darkweb.link/ - mega онион
CraigFaf
how to access deep web safely reddit deep web shopping site https://asapmarketplacee.com/ - what darknet markets are still up
Sirtob
deep web market links reddit darknet markets reddit 2022 https://asapdarkwebmarket.com/ - Cocorico link
Smittjen
core market darknet black market buy online https://cannahome-darkweb-drugstore.com/ - credit card dumps dark web
JamesVet
onion links for deep web dark markets denmark https://asap-darkwebmarket.com/ - phenazepam pills
Richardkeymn
мега onion зеркала зайти на мегу https://hydramarket-darknet.link/ - darknet магазин
BrandenTap
мега onion зеркало мега https://hydra-market-onion.link/ - ссылка на мегу
Donaldrhisp
wired darknet markets deep dot web markets https://versus-drugs-online.com/ - versus market url
HaroldImaby
Kingdom link orange sunshine lsd https://versusdarknetdrugstore.com/ - onion marketplace drugs
RobertGic
onion sex shop cp onion https://darkmarket-asap.com/ - darknet market black
BrandonTor
what is escrow darknet markets versus market link https://darkmarketasap.com/ - dark web hitman for hire
Randylog
dark web sites darknet reinkommen https://versus-onion-market.com/ - drugs onion
DanielEncon
top ten dark web sites what darknet markets sell fentanyl https://asapdarkmarketplace.com/ - duckduckgo onion site
RandyZenny
lsd drug wiki carding deep web links https://cannahomemarket-darknet.com/ - dark web links market
Torntow
dark markets sweden darknet black market url https://wwwdarknetmarket.com/ - biggest darknet markets
Jamesopike
darkfox market darknet drug trafficking https://asap-onion-darkweb.com/ - how to dark web reddit
Robertket
mega онион сайт даркнет ссылки https://hydramarket-online.link/ - мега онион
WilliamBlade
most popular darknet market deep sea darknet market https://asapdrugsonline.com/ - grey market darknet
Ronaldimpak
grey market darknet link versus market https://asapmarket-urll.com/ - darknet seiten
PatrickDuelp
Cocorico Market link phenazepam pills https://versus-darkmarket-online.com/ - site onion liste
RalphusafT
most popular darknet market darknet market url list https://asap-darknet.com/ - dark markets new zealand
HectorMug
мега onion ссылка официальный сайт мега https://hydramarket-online.link/ - mega onion оффициальный сайт
Zacharyhet
dark net market list how to buy drugs on the darknet https://versus-onlinedrugs.com/ - darknet search
RichardCyday
top darknet market now dark web market https://darkwebversus.com/ - where to find darknet market links redit
CharlesGet
dark chart darknet market drug prices https://darkweb-asap.com/ - monkey x pill
Mattheworali
best current darknet market best darknet gun market https://versusdarkwebdrugstore.com/ - dark markets croatia
WilliamQuego
darknet market links 2022 darknet markets working links https://asapdarkmarket.com/ - reddit darknet market deals
JosephBok
dark markets germany buying drugs on darknet https://dark-market-asap.com/ - reddit darknet market noobs
Michaelhoise
legit darknet markets 2022 darknet market wiki https://versus-drugs-market.com/ - the dark web links 2022
Frankcit
bitcoin darknet drugs outlaw market darknet https://asap-drugsonline.com/ - biggest darknet market
Granthub
good dark web search engines assassination market darknet https://asap-online-drugs.com/ - tor markets links
MichaelSware
сайт даркнет mega магазин https://hydramarketdarknet.link/ - mega onion зеркало
CorryBoura
dark web markets reddit 2022 darknet marketplace drugs https://wwwdarknetmarket.shop/ - dark markets russia
Juliusbop
the real deal market darknet orange sunshine lsd https://versus-darkweb-drugstore.com/ - incognito market darknet
DavidMob
monkey xtc pill cannahome market https://asapdrugsmarket.com/ - phenethylamine drugs
Timmylurry
darknet drug vendor that takes paypal dark markets usa https://versus-darknet-drugstore.com/ - how to buy from the darknet markets lsd
DavidSig
lsd drug wiki darkmarket link https://versus-darkmarket.com/ - darknet market superlist
MichaelCox
mega onion зеркало mega onion зеркала https://hydramarket-darknet.link/ - магазин даркнет
ADangep
best darknet market for counterfeit tor market https://aasap-market.com/ - darknet drugs price
ShaneLit
darknet market oz dark markets indonesia https://asapmarket-url.com/ - darknet market status
HellySAr
dark markets slovakia dark web weed https://asap-dark-market.com/ - darknet market adressen
Dannymycle
dark net market links 2022 how to install deep web https://versusdarkmarketlink.com/ - reddit biggest darknet market place
Hansmog
darkweb markets how to order from dark web https://asap-darknet-drugstore.com/ - buy drugs online darknet
DamonPoday
best fraud market darknet adresse onion black market https://asaponiondarkweb.com/ - cannazon
Geraldnob
cvv black market dark web drugs bitcoin https://asapurl.com/ - dark web site list
Charlesjerce
top darknet markets darknet marketplace https://asap-drugs-online.com/ - free deep web links
Jamesgox
largest darknet market drugs on the dark web https://dark-web-versus.com/ - darknet guns market
Jackiesix
мега купить mega онион https://hydramarketdarkweb.link/ - mega onion shop
JasonRab
how to get access to darknet black market deep https://versus-onion-darkmarket.com/ - buy drugs online darknet
GeorgeThuth
how to get on the dark web dark web markets https://cannahomemarketplacee.com/ - market deep web 2022
Justinfluff
darknet markets bitcoin drugs market https://asapdarkweb.com/ - the onion directory
BrianBen
darkfox link darknet markets 2022 https://versusdarkmarketplace.com/ - darknet market alternatives
Julianacunc
darkfox market url how to use darknet markets https://cannahome-marketplace.com/ - the darknet market reddit
CrisUnano
best darknet market for psychedelics how to buy from the darknet markets lsd https://wwwdarkmarket.com/ - how to install deep web
CraigFaf
buy drugs on darknet darknet in person drug sales https://asaponiondarkmarket.com/ - online black market electronics
Sirtob
credit card dumps dark web archetyp market link https://asapdarkwebdrugstore.com/ - site darknet market
EdgarFar
мега onion зеркала мега кокаин https://hydramarket-darkweb.link/ - mega onion shop
WendellEnaky
Kingdom Market link darknet online drugs https://asap-onion-market.com/ - deepdotweb markets
JamesVet
Abacus Market darknet underground dumps shop https://asap-darkwebmarket.com/ - tor market darknet
Smittjen
darknet drug markets 2022 darknet markets https://asap-darkmarket.com/ - crypto darknet drug shop
RobertGic
how to buy bitcoin for the dark web darknet websites wiki https://darkmarket-asap.com/ - deep onion links
BrandonTor
fake id onion darknet escrow markets https://darkmarketasap.com/ - darknet onion markets reddit
BrandenTap
мега кокаин магазин мега https://hydra-market-onion.link/ - mega onion
Richardkeymn
mega onion зеркала мэги сайт https://hydra-market-onion.link/ - официальный сайт мега
Donaldrhisp
darkfox link the armory tor url https://versus-drugs-online.com/ - darknet market place search
Randylog
bohemia market url deep dot web links https://versus-onion-darkweb.com/ - darknetlive
HaroldImaby
darknet market buying mdma usa darknet market thc oil https://versusdarkweb.com/ - how to create a darknet market
DanielEncon
deep web drugs reddit brick market https://asapdarknet.com/ - biggest darknet market
Torntow
alphabay darknet market dot onion websites https://wwwdarkmarket.shop/ - reddit darknet markets 2022
Jamesopike
darknet markets onion addresses darkfox darknet market https://asap-onion-darkweb.com/ - darknet market buying mdma usa
Robertket
ссылка на мегу мега зеркало https://hydramarket-online.link/ - мега onion магазин
WilliamBlade
dark markets uk best darknet drug sites https://asapmarket-darknet.com/ - alphabay market link
Ronaldimpak
guide to darknet markets list of dark net markets https://asapmarket-urll.com/ - litecoin darknet markets
PatrickDuelp
darknet markets with tobacco darknet online drugs https://versus-darkmarket-online.com/ - onion websites for credit cards
SteveNek
mega зеркало darknet магазин https://hydramarketdarkweb.link/ - darknet магазин
RalphusafT
the dark market reddit darknet market noobs bible https://asap-darkweb-drugstore.com/ - shop valid cvv
HectorMug
сайты даркнет ссылки даркнет сайты магазин https://hydramarket-online.link/ - мега онион
Zacharyhet
uncensored deep web darknet links market https://versus-online-drugs.com/ - which darknet markets are still open
Michaelhoise
reliable darknet markets darknet markets norway 2022 https://versus-drugs-market.com/ - top ten dark web sites
RichardCyday
credit card black market websites link de hiden wiki https://darkwebversus.com/ - dark market sites
Mattheworali
trusted darknet markets wiki darknet market https://versusdarkwebmarkett.com/ - underground market online
WilliamQuego
russian anonymous marketplace drugs sold on dark web https://asapdarkmarketonline.com/ - cheap darknet websites dor drugs
JosephBok
darknet market francais the darknet markets https://dark-market-asap.com/ - darknet drugs shipping
CharlesGet
mdm love drug darknet market vendors search https://darkweb-asap.com/ - alphabay link
Frankcit
Heineken Express link black market prices for drugs https://asap-marketplace.com/ - darknet market link updates
Granthub
working darknet markets darknet market iphone https://asap-online-drugs.com/ - cp links dark web
Timmylurry
deep web addresses onion decentralized darknet market https://versus-darknet-drugstore.com/ - list of dark net markets
Juliusbop
florida darknet markets dark markets ukraine https://versus-darkweb.com/ - what darknet markets are open
DavidSig
where to find darknet market links tor darknet market address https://versus-darkmarket.com/ - dark markets malta
MichaelSware
mega сайт мега купить https://hydramarketdarknet.link/ - сылка на мегу
CorryBoura
grey market drugs reddit darknet market 2022 https://wwwdarknetmarket.shop/ - reddit darknet markets links
MichaelCox
магазин даркнет сайт мега https://hydramarket-darknet.link/ - mega даркнет
Jancib
best fraud market darknet versus link https://webdrugs-darknet.shop/ - the dark web links 2022
DavidMob
dark markets switzerland buying drugs on the darknet https://asapdrugsmarket.com/ - darkfox url
HellySAr
dark web drug markets darknet market search https://asap-darkmarket-online.com/ - dark markets ukraine
ADangep
new alphabay darknet market cannazon https://acannahome-market.com/ - biggest darknet market
ShaneLit
best dark net markets superlist darknet markets https://asapmarket-url.com/ - onion links for deep web
Hansmog
i2p darknet markets blacknet drugs https://asap-darkmarketplace.com/ - free deep web links
Jamesgox
darkmarket 2022 list of darknet markets reddit https://dark-web-versus.com/ - trusted darknet vendors
Charlesjerce
buy ssn dob with bitcoin cp onion https://asap-drugs-market.com/ - buy real money
Jackiesix
мега даркнет mega зеркало https://hydramarketdarkweb.link/ - мега сайт ссылка
GeorgeThuth
which darknet market are still up darknet bitcoin market https://cannahomemarketplacee.com/ - how to access darknet markets reddit
Justinfluff
Cocorico Market link incognito url https://asapdarkweb.com/ - onion live
BrianBen
tor markets links black market drugs https://versusdarkmarketplace.com/ - russian anonymous marketplace
JasonRab
dark web xanax darkweb sites reddit https://versus-onion-darkmarket.com/ - darknet список сайтов
CrisUnano
dark markets bolivia exploit market darknet https://wwwdarkmarket.com/ - cypher market
WendellEnaky
cannahome market url darknet market noobs guide https://asap-onlinedrugs.com/ - tor markets
BrandonTor
darknet onion links drugs dark markets montenegro https://darkmarketversus.com/ - darknet seiten
RobertGic
deep web updated links french deep web link https://darkmarket-asap.com/ - darknet market directory
CraigFaf
live onion superlist darknet markets https://asapmarketplacee.com/ - cypher link
Julianacunc
darkfox url darknet markets financial times https://aversus-market.com/ - dark web market links
JamesVet
what darknet market to use now darknet markets list reddit https://asap-darkweb.com/ - underground dumps shop
Smittjen
Kingdom Market link deep web software market https://cannahome-darkweb-drugstore.com/ - blue lady e pill
BrandenTap
мега кокаин mega онион сайт https://hydra-market-onion.link/ - сайты даркнет
Richardkeymn
сайты даркнет ссылки магазин мега https://hydramarket-darknet.link/ - mega зеркало
Donaldrhisp
dark market 2022 dark web fake money https://versus-drugs-online.com/ - incognito market darknet
Randylog
search deep web engine deep web links 2022 https://versus-onion-darkweb.com/ - working dark web links
RandyZenny
current best darknet market darknet market links safe https://cannahomemarket-darknet.com/ - online black market uk
HaroldImaby
ethereum darknet markets australian darknet markets https://versusdarkweb.com/ - adresse onion black market
DanielEncon
underground black market website ruonion https://asapdarkmarketplace.com/ - darknet illicit drugs
Jamesopike
versus project darknet market darknet vendor reviews https://asap-onion-darkmarket.com/ - darknet websites wiki
Robertket
мэги сайт как зайти на мегу https://hydramarket-online.link/ - mega онион сайт
WilliamBlade
dark web marketplace core market darknet https://asapmarket-darknet.com/ - darknet drugs india
Ronaldimpak
uncensored deep web dark web engine search https://asapmarket-urll.com/ - how to buy drugs on the darknet
PatrickDuelp
dn market incognito darknet market https://versus-darkmarket-online.com/ - the dark web shop
HectorMug
мега шишки мега onion магазин https://hydramarket-online.link/ - mega онион
Zacharyhet
guide to darknet markets search darknet markets https://versus-onlinedrugs.com/ - biggest darknet markets
Michaelhoise
new alphabay darknet market dark websites https://versus-drugs-market.com/ - how to get on the dark web on laptop
Juliusbop
darknet market black oniondir deep web link directory https://versus-darkweb-drugstore.com/ - dark web steroids
Timmylurry
tor market list darknet drug market url https://versus-darknet.com/ - dark markets ecuador
JosephBok
how to access dark web markets tor markets https://dark-market-versus.com/ - tor market links
DavidSig
best dark web search engine link darknet market place search https://versus-darkmarket.com/ - how to buy drugs on the darknet
Mattheworali
dynabolts pills pink versace pill https://versusdarkwebdrugstore.com/ - cannahome market link
RichardCyday
cannazone how to access the dark web 2022 https://darkwebversus.com/ - dark markets czech republic
Frankcit
dark markets netherlands buy bank accounts darknet https://asap-marketplace.com/ - superlist darknet markets
CharlesGet
buying drugs on darknet reddit which darknet markets accept zcash https://darkweb-asap.com/ - deep web search engines 2022
Granthub
deep web link 2022 darknet market google https://asap-online-drugs.com/ - top darknet markets
MichaelCox
мега onion зеркала мега onion ссылка https://hydramarket-darknet.link/ - мега ссылка
MichaelSware
мега официальный сайт новое зеркало мега https://hydramarketdarknet.link/ - даркнет магазин
ADangep
the darknet drugs Cocorico Market https://aasap-market.com/ - darknet market search
HellySAr
deep web drug prices darkweb market https://asap-dark-market.com/ - what is the darknet market
Jancib
escrow dark web darknet drugs sales https://webdrugs-darknet.link/ - dark web market list
ShaneLit
darknet drugs market dark markets malaysia https://asapmarket-url.com/ - deep net links
Jamesgox
darknet market thc oil can you buy drugs on darknet https://dark-web-versus.com/ - hacking tools darknet markets
Hansmog
darknet seiten wired darknet markets https://asap-darknet-drugstore.com/ - deep web onion url
Charlesjerce
darknet market bible best current darknet market https://asap-drugs-market.com/ - buy bitcoin for dark web
DamonPoday
how to access the darknet market litecoin darknet markets https://asaponiondarkweb.com/ - current darknet market
Geraldnob
counterfeit money onion darknet market noobs bible https://asapurl.com/ - darkweb форум
Dannymycle
darknet drug prices how to access the darknet market https://versusdarkmarketonline.com/ - best darknet drug market 2022
Jackiesix
мега onion mega сайт https://hydramarketdarknet.link/ - мега onion оффициальный сайт
GeorgeThuth
buds express darknet market superlist https://cannahomemarketplacee.com/ - black market drugs guns
Justinfluff
reddit darknet markets list how to browse the dark web reddit https://asapdarkweb.com/ - fake id onion
JasonRab
black market reddit tor markets https://versus-onion-darkmarket.com/ - dark web link
BrianBen
Kingdom Market darknet dark markets russia https://versusdarknet.com/ - how to access dark web markets
RobertGic
underground dumps shop how to order from dark web https://darkmarket-versus.com/ - versus project link
BrandonTor
darknet market thc oil buy ssn and dob https://darkmarketasap.com/ - best darknet gun market
HaroldImaby
darknet prices onion directory list https://versusdarknetdrugstore.com/ - tor drugs
CrisUnano
dark web markets 2022 australia nike jordan pill https://wwwdarkmarket.com/ - darknet dream market link
WendellEnaky
onion directory drugs sold on dark web https://asap-onion-market.com/ - alphabay solutions reviews
CraigFaf
darknet onion markets the darknet drugs https://asaponiondarkmarket.com/ - trusted darknet vendors
Julianacunc
onion links 2022 how to access the darknet market https://cannahome-marketplace.com/ - online onion market
JamesVet
how to buy from darknet markets dark markets uruguay https://asap-darkweb.com/ - asap market
BrandenTap
официальный сайт мега мега onion зеркало https://hydra-market-onion.link/ - mega onion зеркало
Smittjen
hidden financial services deep web darknet drugs https://cannahome-darkweb-drugstore.com/ - darknet search
Sirtob
unicorn pill darknet market busts https://asapdarkwebmarket.com/ - onion live
Donaldrhisp
deep onion links drugs from darknet markets https://versus-drugsonline.com/ - buy drugs online darknet
Richardkeymn
сайты даркнет мега даркнет https://hydra-market-onion.link/ - mega onion оффициальный сайт
Randylog
black market url deep web cypher market https://versus-onion-market.com/ - darknet new market link
RandyZenny
best drug darknet trusted darknet vendors https://cannahomemarket-darknet.com/ - darknet drug store
DanielEncon
darknetlive carding dark web https://asapdarknet.com/ - xanax on darknet
Torntow
cypher darknet market darknet onion markets https://wwwdarkmarket.shop/ - dark websites reddit
EdgarFar
мега onion оффициальный сайт мега onion зеркало https://hydramarket-darkweb.link/ - mega onion shop
Jamesopike
alphabay market darknet active darknet markets https://asap-onion-darkmarket.com/ - bohemia market darknet
Robertket
как зайти на мегу сайт мега https://hydramarket-online.link/ - сайты даркнет ссылки
WilliamBlade
archetyp url black market access https://asapdrugsonline.com/ - phenazepam pills
RalphusafT
best darknet market for weed darknet market features https://asap-darknet.com/ - black market drugs
SteveNek
зеркало мега мега сайт https://hydramarketdarkweb.link/ - mega market
Timmylurry
safe darknet markets dark market 2022 https://versus-darknet-drugstore.com/ - dark web buy credit cards
Juliusbop
darknet market ranking dark markets japan https://versus-darkweb.com/ - dbol steroid pills
DavidSig
Abacus link dark web cvv https://versus-darkmarket.com/ - dark markets san marino
HectorMug
магазины даркнета даркнет ссылки https://hydramarket-online.link/ - мега онион
Michaelhoise
reddit working darknet markets how to access the dark web reddit https://versus-darkwebmarket.com/ - mdm love drug
Zacharyhet
darknet market prices best darknet market for heroin https://versus-online-drugs.com/ - darknet market place search
Mattheworali
black market alternative deep web links reddit 2022 https://versusdarkwebdrugstore.com/ - canazon
Frankcit
best current darknet market dark net markets https://asap-drugsonline.com/ - shop on the dark web
JosephBok
darknet market comparison chart cannazon darknet market https://dark-market-versus.com/ - deep web drug store
WilliamQuego
bohemia darknet market credit card black market websites https://asapdarkmarket.com/ - outlaw market darknet
RichardCyday
darknet drug prices black market prescription drugs for sale https://darkwebversus.com/ - fake id onion
ADangep
deep web drugs reddit bohemia url https://acannahome-market.com/ - reddit darknet market links
CorryBoura
darkmarket 2022 how to buy from the darknet markets https://wwwdarknetmarket.shop/ - deep dark web
Granthub
google black market the dark web url https://cannahomeoniondarkweb.com/ - popular dark websites
Jancib
darkweb market dark markets canada https://webdrugs-darknet.shop/ - dark markets russia
CharlesGet
best darknet market for weed 2022 best market darknet drugs https://darkweb-asap.com/ - current list of darknet markets
MichaelCox
mega onion зеркало мега зеркало https://hydramarket-darknet.link/ - darknet магазин
MichaelSware
официальный сайт мега даркнет сайты магазин https://hydramarketdarknet.link/ - мега onion зеркала
DavidMob
back market legit dark web market list https://asapdrugsmarketplace.com/ - what is darknet markets
ShaneLit
darknet stock market best darknet market for steroids https://asapmarket-linkk.com/ - darknet drugs url
Jamesgox
dark web markets reddit black market online https://dark-web-asap.com/ - phenazepam pills
Hansmog
darknet drugs malayisa darknet xanax https://asap-darknet-drugstore.com/ - dark web illegal links
Charlesjerce
cannazon buy ssn dob with bitcoin https://asap-drugs-market.com/ - darknet in person drug sales
Dannymycle
how to dark web reddit biggest darknet markets 2022 https://versusdarkmarketlink.com/ - the dark market
Jackiesix
мега onion зеркала ссылка мега https://hydramarketdarknet.link/ - мега официальный сайт
GeorgeThuth
dark markets greece Abacus Market https://cannahomemarketplacee.com/ - deep cp links
Justinfluff
darkmarket list darknet markets japan https://asapdarkweb.com/ - black market drugs guns
BrandonTor
anadrol pills dark markets china https://darkmarketasap.com/ - deep web markets
RobertGic
best darknet markets for vendors darknet market comparison https://darkmarket-versus.com/ - dark markets serbia
JasonRab
adresse onion darknet adressen https://versus-onion-darkmarket.com/ - archetyp market darknet
BrianBen
darknet market lists dark web shop https://versusdarknet.com/ - bitcoin market on darknet tor
CrisUnano
how to get on the dark web on laptop dark markets uruguay https://wwwdarkmarket.com/ - grey market drugs
HaroldImaby
what is escrow darknet markets best darknet markets https://versusdarkweb.com/ - dark web prostitution
WendellEnaky
darknet live markets tor market list https://asap-onion-market.com/ - dream market darknet
BrandenTap
мега onion магазин даркнет сайты магазин https://hydra-market-onion.link/ - сылка на мегу
JamesVet
tor2door market weed only darknet market https://asap-darkweb.com/ - step by step dark web
Smittjen
most popular darknet market darknet litecoin https://cannahome-darkweb-drugstore.com/ - onion seiten
Donaldrhisp
darknet markets availability alphabay market net https://versus-drugs-online.com/ - ketamine darknet market
RandyZenny
where to find darknet market links redit darknet search https://cypherdarkwebdrugstore.com/ - dark market url
Richardkeymn
сайт мега mega onion оффициальный сайт https://hydramarket-darknet.link/ - мега купить
Randylog
live onion darknet adress https://versus-onion-darkweb.com/ - incognito darknet market
DanielEncon
active darknet markets 2022 deep deep web links https://asapdarkmarketplace.com/ - dark web market reviews
Torntow
dark net market cypher darknet market https://wwwdarkmarket.shop/ - deep web links 2022
EdgarFar
сылка на мегу магазины даркнета https://hydramarket-darkweb.link/ - мега ссылка
Jamesopike
tor darknet markets drug markets onion https://asap-onion-darkweb.com/ - reddit working darknet markets
WilliamBlade
darknet drugs sales darknet market guide https://asapmarket-darknet.com/ - what is escrow darknet markets
Juliusbop
darknet markets most popular online black market electronics https://versus-darkweb-drugstore.com/ - dark web link
Timmylurry
how to buy things off the black market drugs dark web price https://versus-darknet.com/ - tramadol dark web
DavidSig
darknet market comparison darknet drug dealer https://versus-darkmarketplace.com/ - blockchain darknet markets
Robertket
mega market mega магазин https://hydramarket-online.link/ - мега сайт
PatrickDuelp
what is darknet markets brucelean darknet market https://versus-dark-markett.com/ - dark web site list
RalphusafT
best darknet markets 2022 darknet market comparison https://asap-darkweb-drugstore.com/ - market deep web 2022
SteveNek
мега онион мега onion оффициальный сайт https://hydramarketdarkweb.link/ - мега onion ссылка
Michaelhoise
dark market link grey market link https://versus-drugs-market.com/ - tor link list 2022
HectorMug
мега onion зеркало mega market https://hydramarket-darkweb.link/ - mega onion shop
Zacharyhet
gbl drug wiki reliable darknet markets lsd https://versus-online-drugs.com/ - alphabay market net
CorryBoura
ordering drugs on dark web best websites dark web https://wwwdarknetmarket.shop/ - what darknet markets are up
ADangep
darknet live markets dark markets paraguay https://aasap-market.com/ - dark markets montenegro
HellySAr
how to create a darknet market dark web address list https://asap-darkmarket-online.com/ - legit darknet markets 2022
Mattheworali
which darknet markets accept zcash darknet markets list https://versusdarkwebmarkett.com/ - phenazepam pills
Frankcit
darknet market prices darknet markets norway 2022 https://asap-marketplace.com/ - best darknet markets 2022
WilliamQuego
crypto darknet drug shop verified dark web links https://asapdarkmarket.com/ - onion market url
RichardCyday
Kingdom Market link darknet website for drugs https://darkwebversus.com/ - links the hidden wiki
Granthub
dark markets albania deep net links https://asap-online-drugs.com/ - tor marketplaces
Jancib
black market website legit what is the best darknet market https://webdrugs-darknet.shop/ - how to get access to darknet
DavidMob
deep web search engine 2022 top darknet market now https://asapdrugsmarket.com/ - darknetlive
MichaelCox
ссылка на мегу мега официальный сайт https://hydramarket-darknet.link/ - мега даркнет
CharlesGet
darknet список сайтов top 10 dark web url https://darkweb-versus.com/ - Kingdom Market
MichaelSware
мега наркотики mega onion shop https://hydramarketdarknet.link/ - mega market
Jamesgox
buy drugs from darknet reliable darknet markets https://dark-web-asap.com/ - buy real money
Hansmog
dark net market list darknet black market url https://asap-darknet-drugstore.com/ - dark markets latvia
Charlesjerce
top darknet markets links deep web tor https://asap-drugs-online.com/ - darknet guns market
Dannymycle
best market darknet drugs reddit darknet market 2022 https://versusdarkmarketlink.com/ - best dark web marketplaces 2022
DamonPoday
live onion best dark web counterfeit money https://asaponionmarket.com/ - wiki darknet market
BrandonTor
versus project market link legit darknet markets https://darkmarketversus.com/ - incognito darknet market
RobertGic
Cocorico darknet Market euroguns deep web https://darkmarket-asap.com/ - tor2door market url
Jackiesix
сайт мега мега сайт ссылка https://hydramarketdarkweb.link/ - мега onion зеркала
GeorgeThuth
deep web drug store list of online darknet market https://cannahomemarketplacee.com/ - dark web prepaid cards reddit
Justinfluff
tma drug darknet markets reddit 2022 https://asapdarknetdrugstore.com/ - site darknet onion
JasonRab
can you buy drugs on darknet dark markets japan https://versus-onion-darkmarket.com/ - grey market darknet link
BrianBen
dark web legit sites darknet market bible https://versusdarkmarketplace.com/ - google black market
CrisUnano
incognito url darknet prices https://wwwdarkmarket.link/ - how to buy from the darknet markets lsd
HaroldImaby
darkfox url how to access the black market https://versusdarknetdrugstore.com/ - dark web cvv
WendellEnaky
how to access the darknet market onion seiten https://asap-onlinedrugs.com/ - drug markets onion
CraigFaf
how to buy from darknet darknet market lists https://asaponiondarkmarket.com/ - the armory tor url
JamesVet
asap darknet market trusted darknet markets https://asap-darkweb.com/ - current darknet market list
BrandenTap
мега ссылка мега онион сайт https://hydra-market-onion.link/ - darknet сайт
Smittjen
ketamine darknet market dark web cvv https://asap-darkmarket.com/ - ordering drugs on dark web
Donaldrhisp
buy darknet market email address Heineken Express darknet Market https://versus-drugsonline.com/ - darknet market script
Julianacunc
what are darknet drug markets darknet new market link https://cannahome-marketplace.com/ - bitcoin cash darknet markets
Randylog
buy ssn and dob the darknet market reddit https://versus-onion-darkweb.com/ - how to use deep web on pc
Richardkeymn
зайти на мегу darknet магазин https://hydramarket-darknet.link/ - mega onion ссылка
RandyZenny
anadrol pills buy drugs darknet https://cypherdarkwebdrugstore.com/ - dark markets greece
Sirtob
darknet links market darknet market adderall https://asapdarkwebmarket.com/ - dark web engine search
DanielEncon
deep web drug links dark web shopping https://asapdarknet.com/ - Heineken Express link
Torntow
trusted darknet markets weed darknet list https://wwwdarkmarket.shop/ - current darknet market
DavidSig
bitcoin darknet markets the dark web url https://versus-darkmarketplace.com/ - darknet drug prices uk
EdgarFar
mega онион сайт мега onion https://hydramarket-darkweb.link/ - мега кокаин
Juliusbop
darknet market search verified darknet market https://versus-darkweb.com/ - Abacus darknet Market
Timmylurry
how to pay with bitcoin on dark web what is the darknet market https://versus-darknet.com/ - dark markets san marino
Jamesopike
dark web buy credit cards drugs dark web reddit https://asap-onion-darkweb.com/ - access darknet markets
Ronaldimpak
alphabay darknet market dark markets korea https://asapmarket-urll.com/ - we amsterdam
WilliamBlade
darknet serious market darknet drug vendor that takes paypal https://asapdrugsonline.com/ - drug markets onion
PatrickDuelp
darknet markets lsd-25 2022 darkmarkets https://versus-darkmarket-online.com/ - best darknet market urs
Robertket
магазины даркнета мега купить https://hydramarket-online.link/ - сылка на мегу
RalphusafT
dark web step by step darknet market noobs reddit https://asap-darknet.com/ - versus market url
HellySAr
blue lady e pill dark web cheap electronics https://asap-dark-market.com/ - buy ssn and dob
CorryBoura
darknet escrow Abacus Market darknet https://wwwdarknetmarket.shop/ - bitcoin dark website
ADangep
underground market place darknet hire an assassin dark web https://acannahome-market.com/ - darknet drug markets
SteveNek
mega онион сайт darknet сайт https://hydramarketdarkweb.link/ - мега скорость
HectorMug
сайт мега мега купить соль https://hydramarket-online.link/ - зеркало мега
Frankcit
onion deep web search reddit darknet market superlist https://asap-drugsonline.com/ - Cocorico darknet Market
Zacharyhet
blacknet drugs Abacus Market link https://versus-onlinedrugs.com/ - tor2door darknet market
JosephBok
nike jordan pill darknet drug dealer https://dark-market-asap.com/ - best darknet market for heroin
Michaelhoise
darknet sites drugs grey market darknet https://versus-drugs-market.com/ - darknet drugs sites
WilliamQuego
tor onion search archetyp market url https://asapdarkmarketonline.com/ - darknet market list 2022
RichardCyday
buy real money drug markets onion https://darkwebasap.com/ - best dark web markets 2022
Mattheworali
how to dark web reddit darknet drugs sites https://versusdarkwebdrugstore.com/ - deep web canada
Granthub
superman pills mg hire an assassin dark web https://cannahomeoniondarkweb.com/ - best darknet drug sites
Jancib
tor websites reddit cypher market https://webdrugs-darknet.link/ - hidden wiki tor onion urls directories
DavidMob
tor search onion link onion linkek https://asapdrugsmarket.com/ - best darknet market now
MichaelCox
мега onion сылка на мегу https://hydramarket-darknet.link/ - мега onion ссылка
CharlesGet
the onion directory monkey xtc pill https://darkweb-asap.com/ - russian anonymous marketplace
MichaelSware
магазин даркнет мега купить https://hydramarketdarknet.link/ - даркнет сайты магазин
Jamesgox
underground market place darknet tor market https://dark-web-asap.com/ - dark markets czech republic
ShaneLit
darknet markets availability pax marketplace https://asapmarket-url.com/ - darknet drugs india
Hansmog
dark web links adult onion deep web search https://asap-darkmarketplace.com/ - dark markets hungary
RobertGic
tor market links 2022 best darknet markets reddit https://darkmarket-versus.com/ - uncensored hidden wiki link
Charlesjerce
search darknet market cannazon market darknet https://asap-drugs-online.com/ - escrow market darknet
BrandonTor
hacking tools darknet markets dark markets czech republic https://darkmarketversus.com/ - Cocorico url
Dannymycle
deep web addresses onion darknetlive https://versusdarkmarketlink.com/ - dark markets ecuador
GeorgeThuth
best drug darknet buy drugs online darknet https://cannahomemarketplacee.com/ - deep deep web links
Geraldnob
tor2door market darknet darknet black market sites https://asaponlinedrugs.com/ - best darknet market uk
DamonPoday
dark web market place links darknet markets for steroids https://asaponiondarkweb.com/ - darknet markets lsd-25 2022
Jackiesix
mega онион сайт мега onion ссылка https://hydramarketdarkweb.link/ - новое зеркало мега
JasonRab
deep dark web markets links best card shops https://versus-marketplace24.com/ - i2p darknet markets
BrianBen
darknet markets norge legit darknet sites https://versusdarknet.com/ - tor marketplaces
CrisUnano
darkfox market link dark markets united kingdom https://wwwdarkmarket.com/ - underground card shop
HaroldImaby
steroid market darknet alphabay market darknet https://versusdarknetdrugstore.com/ - how to darknet market
WendellEnaky
reddit darknet market superlist tor drugs https://asap-onlinedrugs.com/ - darknet drugs germany
JamesVet
best lsd darknet market darknet drug prices https://asap-darkwebmarket.com/ - darknet markets with tobacco
CraigFaf
dark markets malaysia drugs dark web https://asapmarketplacee.com/ - how to access darknet market
BrandenTap
магазины даркнета mega сайт https://hydra-market-onion.link/ - mega зеркало
Smittjen
darknet wiki link deep web links reddit 2022 https://cannahome-darkweb-drugstore.com/ - dark markets sweden
Donaldrhisp
dark markets sweden gbl drug wiki https://versus-drugsonline.com/ - darknet markets noob
DavidSig
dark markets malaysia deep web links reddit 2022 https://versus-darkmarket.com/ - site darknet liste
Timmylurry
how big is the darknet market darknet market links 2022 reddit https://versus-darknet.com/ - reddit darknet market deals
Juliusbop
dark markets czech republic the real deal market darknet https://versus-darkweb-drugstore.com/ - deep web cc shop
Sirtob
black market buy online dark market sites https://asapdarkwebmarket.com/ - darknet market google
Randylog
how to access darknet markets dark web markets 2022 https://versus-onion-darkweb.com/ - darkfox market darknet
DanielEncon
outlaw market darknet reddit darknet market australia https://asapdarknet.com/ - dark web sites name list
Richardkeymn
мега даркнет мега онион https://hydra-market-onion.link/ - мега ссылка
Julianacunc
buy bank accounts darknet best darknet market reddit https://aversus-market.com/ - link darknet market
Torntow
dark web weed darknet market list 2022 https://wwwdarkmarket.shop/ - dark markets france
RandyZenny
vice city market darknet buds express https://cannahomemarket-darknet.com/ - what darknet markets are still open
EdgarFar
мега сайт мега магазин https://hydramarket-darkweb.link/ - mega onion зеркало
Jamesopike
we amsterdam bitcoin drugs market https://asap-onion-darkmarket.com/ - incognito market darknet
CorryBoura
weed darknet market buy ssn dob with bitcoin https://wwwdarknetmarket.link/ - best darknet drug sites
Ronaldimpak
darknet drugs malayisa buying from darknet market with electrum https://asapmarketplace24.com/ - darkweb market
ADangep
cannazon market url darkweb sites reddit https://acannahome-market.com/ - step by step dark web
PatrickDuelp
dark web step by step tor onion search https://versus-dark-markett.com/ - Kingdom darknet Market
WilliamBlade
darknet market updates 2022 darknet markets https://asapdrugsonline.com/ - best dark web counterfeit money
RalphusafT
where to find onion links dark chart https://asap-darknet.com/ - best darknet market for weed 2022
Robertket
мега onion зайти на мегу https://hydramarket-online.link/ - mega зеркало
SteveNek
mega сайт мега onion https://hydramarketdarkweb.link/ - мега официальный сайт
Frankcit
darknet market onion links the real deal market darknet https://asap-marketplace.com/ - tor darknet market address
HectorMug
мега onion мега мефедрон https://hydramarket-darkweb.link/ - mega onion
Zacharyhet
best darknet market urs bohemia market link https://versus-onlinedrugs.com/ - the darknet drugs
Michaelhoise
best working darknet market 2022 darknet list https://versus-darkwebmarket.com/ - darknet black market list
WilliamQuego
cannazon market link versus market link https://asapdarkmarket.com/ - darknet markets 2022 updated
JosephBok
darknet market url florida darknet markets https://dark-market-asap.com/ - deep web cc dumps
Jancib
dark web poison tor darknet markets https://webdrugs-darknet.link/ - reddit where to buy drugs
Granthub
australian dark web markets illegal black market https://cannahomeoniondarkweb.com/ - darknet marketplace drugs
Mattheworali
dark markets bulgaria darknet guns drugs https://versusdarkwebmarkett.com/ - asap darknet market
RichardCyday
darknet market for noobs darknet markets list 2022 https://darkwebversus.com/ - black market prescription drugs for sale
DavidMob
list of darknet markets 2022 cannahome darknet market https://asapdrugsmarket.com/ - adress darknet
MichaelCox
магазины даркнета mega market https://hydramarket-darknet.link/ - мега шишки
Jamesgox
black market reddit black market alternative https://dark-web-versus.com/ - project versus
CharlesGet
dark chart project versus https://darkweb-versus.com/ - darknet seiten liste
ShaneLit
dark web steroids dark web markets reddit 2022 https://asapmarket-linkk.com/ - deep web websites reddit
RobertGic
darknet drugs germany how to buy from the darknet markets lsd https://darkmarket-asap.com/ - darknet vendor reviews
BrandonTor
deep web drug markets cannazon market https://darkmarketversus.com/ - archetyp market
Charlesjerce
darknet market reviews buy darknet market email address https://asap-drugs-market.com/ - darknet litecoin
Hansmog
biggest darknet markets 2022 black market websites tor https://asap-darknet-drugstore.com/ - deep web drug markets
Dannymycle
darknet market links safe darknet markets wax weed https://versusdarkmarketlink.com/ - best dark web markets 2022
GeorgeThuth
Heineken Express darknet Market archetyp url https://cannahomemarketplacee.com/ - how to use the darknet markets
Jackiesix
ссылка на мегу мега магазин https://hydramarketdarkweb.link/ - мэги сайт
DamonPoday
black market bank account working darknet markets 2022 https://asaponionmarket.com/ - darknet drugs sites
Geraldnob
florida darknet markets darknet market noobs guide https://asapurl.com/ - dark web address list
JasonRab
pill with crown on it red ferrari pills https://versus-onion-darkmarket.com/ - darknet markets dread
Justinfluff
site onion liste fake id onion https://asapdarkweb.com/ - darknet market buying mdma usa
BrianBen
darknet market drug dark web markets 2022 australia https://versusdarknet.com/ - drugs on the darknet
CrisUnano
biggest darknet markets 2022 darknet websites wiki https://wwwdarkmarket.link/ - most popular darknet markets 2022
WendellEnaky
dot onion websites market cypher https://asap-onion-market.com/ - drugs darknet vendors
HaroldImaby
darknet market links 2022 darknet market url https://versusdarknetdrugstore.com/ - darknet drug store
JamesVet
canazon buying drugs on darknet https://asap-darkwebmarket.com/ - darknet market alphabay
CraigFaf
best darknet drug market 2022 darknet список сайтов https://asapmarketplacee.com/ - the dark web links 2022
Juliusbop
deep dot web links best darknet markets https://versus-darkweb-drugstore.com/ - darknet buy drugs
Timmylurry
darknet market busts darknet markets 2022 reddit https://versus-darknet-drugstore.com/ - dark market 2022
DavidSig
dark web drugs ireland black market reddit https://versus-darkmarketplace.com/ - darknet markets norway 2022
BrandenTap
mega onion shop магазины даркнета https://hydra-market-onion.link/ - мега наркотики
Smittjen
deep web drugs reddit tor market darknet https://asap-darkmarket.com/ - dark markets iceland
Donaldrhisp
blackweb darknet market darknet market bust https://versus-drugsonline.com/ - vice city market url
Randylog
dark web payment methods darknet markets still open https://versus-onion-darkweb.com/ - how to access deep web safely reddit
DanielEncon
tor darknet sites darknet stock market https://asapdarkmarketplace.com/ - asap market darknet
Julianacunc
dark net markets darknet markets fake id https://aversus-market.com/ - darknet market for noobs
Torntow
darknet market vendors search ruonion https://wwwdarkmarket.shop/ - cannazon market url
RandyZenny
how to buy drugs dark web black market websites 2022 https://cypherdarkwebdrugstore.com/ - bohemia market
EdgarFar
mega сайт мега онион сайт https://hydramarket-darkweb.link/ - мега нарко
Jamesopike
archetyp market link deep web hitmen url https://asap-onion-darkmarket.com/ - darknet search
Ronaldimpak
darknet market links counterfeit money dark web reddit https://asapmarket-urll.com/ - red ferrari pills
PatrickDuelp
onion directory list dark web market https://versus-darkmarket-online.com/ - ethereum darknet markets
RalphusafT
current darknet market list deep cp links https://asap-darkweb-drugstore.com/ - reddit darknet market 2022
SteveNek
официальный сайт мега мега onion зеркала https://hydramarketdarkweb.link/ - мега купить
Frankcit
guide to using darknet markets darknet union https://asap-drugsonline.com/ - how to buy bitcoin for the dark web
Robertket
как зайти на мегу mega onion оффициальный сайт https://hydramarket-online.link/ - мега onion зеркала
Zacharyhet
darknet xanax darkmarket 2022 https://versus-onlinedrugs.com/ - darknet market carding
RobertGic
dark web website links darkmarket link https://darkmarket-versus.com/ - adresse onion black market
HectorMug
darknet сайт мега купить соль https://hydramarket-online.link/ - mega onion ссылка
Michaelhoise
best dark web markets 2022 how to get to darknet market safe https://versus-darkwebmarket.com/ - vice city darknet market
WilliamQuego
darknet in person drug sales dark web poison https://asapdarkmarketonline.com/ - drug trading website
JosephBok
ruonion working dark web links https://dark-market-versus.com/ - onion seiten
Mattheworali
darknet market canada cannahome https://versusdarkwebdrugstore.com/ - dbol steroid pills
Granthub
best deep web markets buy real money https://asap-online-drugs.com/ - deep web trading
RichardCyday
market links darknet darknet drugs sales https://darkwebasap.com/ - verified dark web links
MichaelCox
магазин даркнет мега onion оффициальный сайт https://hydramarket-darknet.link/ - магазины даркнета
Jamesgox
dark markets slovakia darknet drug markets https://dark-web-versus.com/ - r darknet market
CharlesGet
darknet bank accounts darknet drug vendor that takes paypal https://darkweb-versus.com/ - top dark net markets
ShaneLit
best darknet markets for marijuana darknet market wiki https://asapmarket-linkk.com/ - how to install deep web
BrandonTor
dark web weed how to access the dark web 2022 https://darkmarketversus.com/ - darknet software market
Charlesjerce
drug markets onion xanax on darknet https://asap-drugs-market.com/ - dark net markets
Hansmog
dark web cvv incognito market link https://asap-darknet-drugstore.com/ - darknet markets reddit 2022
GeorgeThuth
buy ssn dob with bitcoin dark net guide https://cannahomemarketplace24.com/ - how to get to darknet market safe
Dannymycle
hacking tools darknet markets darkmarkets https://versusdarkmarketlink.com/ - darknet drug store
Jackiesix
мега onion darknet магазин https://hydramarketdarkweb.link/ - mega onion shop
DavidMob
dark markets andorra best black market websites https://asapdrugsmarket.com/ - darknet drug markets
Sirtob
Kingdom url onion darknet market https://asapdarkwebdrugstore.com/ - dark web links 2022
WilliamBlade
deep web links reddit cypher link https://asapmarket-darknet.com/ - dark web search engines 2022
ADangep
gray market place biggest darknet market https://aasap-market.com/ - darknet drug dealer
CorryBoura
darknet market reviews deep web search engines 2022 https://wwwdarknetmarket.shop/ - cannazon market url
JasonRab
darknet markets address cvv black market https://versus-marketplace24.com/ - darknet new market link
DamonPoday
dark markets italy darknet market ranking https://asaponiondarkweb.com/ - dark web markets 2022
Geraldnob
cannazon url biggest darknet market 2022 https://asapurl.com/ - credit card black market websites
Justinfluff
drug markets onion legit darknet markets https://asapdarkweb.com/ - bitcoin darknet drugs
BrianBen
how to access darknet markets buying from darknet market with electrum https://versusdarknet.com/ - good dark web search engines
CrisUnano
links tor 2022 darknet market get pills https://wwwdarkmarket.com/ - onion links for deep web
Timmylurry
dark web drugs australia darknet market links safe https://versus-darknet.com/ - darknet online drugs
Juliusbop
dark web weed darknet drugs shipping https://versus-darkweb-drugstore.com/ - darknet market 2022 reddit
WendellEnaky
deep net links top ten dark web https://asap-onlinedrugs.com/ - darknet market url list
DavidSig
dark web marketplace Kingdom link https://versus-darkmarketplace.com/ - cvv black market
HellySAr
dark web search engines 2022 most reliable darknet markets https://asap-darkmarket-online.com/ - reliable darknet markets
CraigFaf
darknet market wikia darknet drug prices uk https://asaponiondarkmarket.com/ - darknet market canada
BrandenTap
как зайти на мегу мега onion зеркала https://hydra-market-onion.link/ - mega зеркало
JamesVet
black market websites credit cards fake id dark web 2022 https://asap-darkweb.com/ - onion live
Smittjen
site darknet fermГ© dark markets chile https://cannahome-darkweb-drugstore.com/ - buying drugs on darknet
Donaldrhisp
xanax darknet markets reddit onion sex shop https://versus-drugsonline.com/ - darknet drugs market
Randylog
buy drugs darknet darknet drug delivery https://versus-onion-market.com/ - fake id onion
Torntow
darknet market list reddit dark web site list https://wwwdarkmarket.shop/ - bohemia link
RandyZenny
best dark web markets online drug market https://cannahomemarket-darknet.com/ - dark markets slovenia
Richardkeymn
мега магазин мега onion магазин https://hydramarket-darknet.link/ - ссылка мега
Julianacunc
how to order from dark web versus project darknet market https://aversus-market.com/ - dark web sites
EdgarFar
даркнет магазин mega onion зеркало https://hydramarket-darkweb.link/ - мега вход
Jamesopike
darknet black market url dark web sites for drugs https://asap-onion-darkmarket.com/ - florida darknet markets
PatrickDuelp
cannahome url reddit darknet market australia https://versus-darkmarket-online.com/ - best dark net markets
Ronaldimpak
best darknet market now dark markets malta https://asapmarket-urll.com/ - market links darknet
RalphusafT
buy bitcoin for dark web dark web adderall https://asap-darkweb-drugstore.com/ - updated darknet market links 2022
Frankcit
most popular darknet market onion sex shop https://asap-marketplace.com/ - darknet markets list reddit
SteveNek
mega market сайт мега https://hydramarketdarkweb.link/ - новое зеркало мега
Robertket
даркнет ссылки мега кокаин https://hydramarket-online.link/ - мега купить
Zacharyhet
drugs onion site darknet market https://versus-onlinedrugs.com/ - darknet drugs malayisa
Michaelhoise
what bitcoins are accepted by darknet markets drugs on the dark web https://versus-darkwebmarket.com/ - what is a darknet drug market like
RobertGic
drugs sold on dark web dxm pills https://darkmarket-asap.com/ - top ten dark web
WilliamQuego
darknet market vendors search tor link list 2022 https://asapdarkmarketonline.com/ - how to access dark web markets
HectorMug
даркнет магазин зайти на мегу https://hydramarket-online.link/ - mega onion
JosephBok
deep sea darknet market blockchain darknet markets https://dark-market-versus.com/ - deep web cc sites
Jancib
darknet market vendor guide underground market online https://webdrugs-darknet.link/ - darknet market onions
Mattheworali
ethereum darknet markets deep web links 2022 https://versusdarkwebdrugstore.com/ - darknet selling drugs
Granthub
dark web marketplace asap market link https://cannahomeoniondarkweb.com/ - how to enter the black market online
RichardCyday
best darknet market for lsd dark web market https://darkwebasap.com/ - black market website names
MichaelSware
mega даркнет darknet сайт https://hydramarketdarknet.link/ - mega онион
MichaelCox
мега onion зеркала мега вход https://hydramarket-darknet.link/ - мега onion оффициальный сайт
ShaneLit
best card shops deep web links 2022 reddit https://asapmarket-url.com/ - asap market darknet
Jamesgox
red ferrari pills dark markets argentina https://dark-web-asap.com/ - wired darknet markets
BrandonTor
darknet markets reddit links dark markets hungary https://darkmarketversus.com/ - reddit onion list
Charlesjerce
buds express buy ssn dob with bitcoin https://asap-drugs-market.com/ - darknet link drugs
Hansmog
best darknet market for weed onion live https://asap-darknet-drugstore.com/ - versus project market darknet
WilliamBlade
drug markets dark web site darknet onion https://asapmarket-darknet.com/ - dark markets luxembourg
DavidMob
most reliable darknet markets adress darknet https://asapdrugsmarketplace.com/ - dark web search tool
GeorgeThuth
list of darknet markets reddit darknet markets still up https://cannahomemarketplace24.com/ - alphabay url
Dannymycle
deep web market links reddit dark markets finland https://versusdarkmarketlink.com/ - darknet market onions
Jackiesix
сайты даркнет мега шишки https://hydramarketdarknet.link/ - сайты даркнет
Sirtob
dark markets monaco darknet market 2022 reddit https://asapdarkwebdrugstore.com/ - bitcoin black market
JasonRab
current darknet markets reddit top ten deep web https://versus-onion-darkmarket.com/ - current darknet market
Justinfluff
onion live cannahome market link https://asapdarkweb.com/ - dark markets lithuania
DamonPoday
active darknet markets 2022 dark markets mexico https://asaponiondarkweb.com/ - dxm pills
Geraldnob
how to buy from darknet link de hiden wiki https://asapurl.com/ - cannahome market link
CrisUnano
how to anonymously use darknet markets alphabay darknet market https://wwwdarkmarket.com/ - tor link list 2022
Juliusbop
top darknet markets 2022 reliable darknet markets reddit https://versus-darkweb.com/ - legit darknet markets 2022
Timmylurry
shop ccs carding Kingdom Market https://versus-darknet-drugstore.com/ - how to browse the dark web reddit
BrianBen
deep web drugs dark markets india https://versusdarknet.com/ - the dark web url
HellySAr
how to get to darknet market phenethylamine drugs https://asap-dark-market.com/ - incognito market link
HaroldImaby
dark web onion markets dark markets sweden https://versusdarknetdrugstore.com/ - deep web cc dumps
BrandenTap
даркнет сайты магазин мега онион https://hydra-market-onion.link/ - новое зеркало мега
CraigFaf
onion directory list deep onion links https://asaponiondarkmarket.com/ - asap link
DavidSig
australian dark web markets darknet market bible https://versus-darkmarket.com/ - Abacus Market link
JamesVet
top darknet market 2022 dark web prepaid cards reddit https://asap-darkwebmarket.com/ - monero darknet markets
Smittjen
dark markets indonesia dark web links 2022 reddit https://asap-darkmarket.com/ - what darknet markets are available
Donaldrhisp
search darknet market what darknet markets are available https://versus-drugsonline.com/ - darknet market adderall prices
Randylog
how to get access to darknet drugs dark web reddit https://versus-onion-market.com/ - Abacus Market darknet
DanielEncon
blockchain darknet markets url hidden wiki https://asapdarkmarketplace.com/ - what darknet markets are still up
Torntow
darknet best drugs versus project darknet market https://wwwdarknetmarket.com/ - deep web websites reddit
RandyZenny
how to get on the dark web android onion market https://cypherdarkwebdrugstore.com/ - dark markets belgium
Richardkeymn
сайты даркнет mega сайт https://hydra-market-onion.link/ - мега онион сайт
EdgarFar
ссылка на мегу мега шишки https://hydramarket-darkweb.link/ - сайт мега
Julianacunc
alphabay market url dark web prostitution https://cannahome-marketplace.com/ - active darknet markets
PatrickDuelp
best darknet markets 2022 black market prices for drugs https://versus-dark-markett.com/ - drugs on deep web
Jamesopike
best australian darknet market reddit darknet market uk https://asap-onion-darkweb.com/ - dark market reddit
Ronaldimpak
dark markets netherlands best darknet market 2022 https://asapmarket-urll.com/ - dark markets hungary
Feaside
<a href=http://tamoxifenolvadex.com/>tamoxifen nolvadex</a> I ovulated soon after finishing the 5 pills.
Hilltob
dark web sales live dark web https://web-darknet-market.com/ - shop on the dark web
Frankcit
buying credit cards on dark web dark web drug markets https://asap-drugsonline.com/ - dark web live
SteveNek
мега официальный сайт mega магазин https://hydramarketdarkweb.link/ - mega onion зеркала
Michaelhoise
darknet market controlled delivery top darknet markets 2022 https://versus-drugs-market.com/ - dark net market
RobertGic
tor onion search underground market online https://darkmarket-asap.com/ - darknet market adderall
Zacharyhet
site darknet fermГ© working darknet markets https://versus-online-drugs.com/ - deep deep web links
Robertket
mega зеркало магазины даркнета https://hydramarket-online.link/ - мега кокаин
WilliamQuego
dark markets ukraine hidden wiki tor onion urls directories https://asapdarkmarket.com/ - deep web updated links
Mattheworali
dark web shopping darknet markets reddit links https://versusdarkwebdrugstore.com/ - buy ssn and dob
JosephBok
how to order from dark web how to buy things off the black market https://dark-market-versus.com/ - darknet market iphone
HectorMug
ьупф ьфклуе ссылки на даркнет https://hydramarket-darkweb.link/ - мега onion оффициальный сайт
Jancib
what darknet market to use dark markets bulgaria https://webdrugs-darknet.link/ - how to get on the dark web android
Granthub
best darknet market for guns tor search engine link https://asap-online-drugs.com/ - what darknet markets are available
RichardCyday
reddit darknet market uk drugs from darknet markets https://darkwebasap.com/ - drugs on deep web
ShaneLit
dark web market list dark web poison https://asapmarket-linkk.com/ - dark markets spain
MichaelSware
мега onion ссылка сайт мега https://hydramarketdarknet.link/ - официальный сайт мега
MichaelCox
мега onion оффициальный сайт мега онион https://hydramarket-darknet.link/ - мега даркнет
Charlesjerce
guns dark market darknet database market https://asap-drugs-market.com/ - cannahome link
CharlesGet
dark markets south korea current list of darknet markets https://darkweb-asap.com/ - active darknet market urls
Jamesgox
cypher url deep web addresses onion https://dark-web-versus.com/ - dark markets south korea
BrandonTor
darknet market news best dark web markets 2022 https://darkmarketasap.com/ - black market cryptocurrency
DavidMob
new darknet markets 2022 dark markets guyana https://asapdrugsmarketplace.com/ - best fraud market darknet
WilliamBlade
dark websites reddit dark markets uk https://asapdrugsonline.com/ - the dark web shop
Hansmog
dark markets monaco onion market url https://asap-darknet-drugstore.com/ - darknet market links 2022 reddit
GeorgeThuth
darknet onion links drugs best darknet market drugs https://cannahomemarketplace24.com/ - darknet in person drug sales
Dannymycle
dark markets south korea how to buy from darknet markets https://versusdarkmarketlink.com/ - darknet market canada
Timmylurry
underground dumps shop ordering drugs on dark web https://versus-darknet-drugstore.com/ - best darknet market for psychedelics
Juliusbop
darknet market adderall prices how to access the dark web reddit https://versus-darkweb.com/ - wiki sticks drugs
JasonRab
drugs dark web deep web link 2022 https://versus-marketplace24.com/ - dark web sites drugs
Jackiesix
mega онион как зайти на мегу https://hydramarketdarknet.link/ - mega ссылка
Sirtob
how to access deep web safely reddit darknet market links safe https://asapdarkwebmarket.com/ - what is escrow darknet markets
CrisUnano
darknet drug store darknet drug vendors https://wwwdarkmarket.link/ - carding deep web links
DamonPoday
tor2door darknet market versus link https://asaponiondarkweb.com/ - how to access darknet markets
Geraldnob
active darknetmarkets dark web buy credit cards https://asaponlinedrugs.com/ - versus market link
BrianBen
darkmarket 2022 dark web markets 2022 https://versusdarkmarketplace.com/ - deep web search engine 2022
WendellEnaky
history of darknet markets which darknet market are still up https://asap-onlinedrugs.com/ - mdm love drug
CraigFaf
dark markets indonesia darknet markets 2022 reddit https://asaponiondarkmarket.com/ - darknet prices
DavidSig
onion links 2022 dark web payment methods https://versus-darkmarket.com/ - onion links 2022
HaroldImaby
dark web prostitution dma drug https://versusdarknetdrugstore.com/ - tor search onion link
JamesVet
dark web drugs nz asap market darknet https://asap-darkwebmarket.com/ - darknet list market
BrandenTap
сайт мега ссылка мега https://hydra-market-onion.link/ - mega магазин
Smittjen
steroid market darknet dynabolts pills https://asap-darkmarket.com/ - how to buy drugs on the darknet
Donaldrhisp
darknet market lists how to use deep web on pc https://versus-drugs-online.com/ - darknet market dash
Randylog
darknet markets fake id darknet market links reddit https://versus-onion-market.com/ - alphabay market
DanielEncon
2022 darknet markets darknet market features https://asapdarkmarketplace.com/ - vice city market darknet
RandyZenny
dark web login guide blacknet drugs https://cypherdarkwebdrugstore.com/ - step by step dark web
Richardkeymn
мега onion официальный сайт мега https://hydramarket-darknet.link/ - мега онион
EdgarFar
зайти на мегу мега официальный сайт https://hydramarket-darkweb.link/ - мега вход
PatrickDuelp
credit card black market websites black market sites 2022 https://versus-dark-markett.com/ - deep web cc dumps
Julianacunc
darkweb sites reddit darknet drugs https://cannahome-marketplace.com/ - dark web sales
Jamesopike
darknet escrow markets onion live links https://asap-onion-darkmarket.com/ - market deep web 2022
Ronaldimpak
darknet markets that take ethereum vice city darknet market https://asapmarket-urll.com/ - best darknet market for lsd
Frankcit
tor2door market darknet safe list of darknet market links https://asap-marketplace.com/ - darknet drug trafficking
RalphusafT
hidden wiki tor onion urls directories alphabay link https://asap-darknet.com/ - darkmarket list
SteveNek
магазин даркнет сайт мега https://hydramarketdarkweb.link/ - мега ссылка
RobertGic
deep web hitmen url darknet market directory https://darkmarket-asap.com/ - dark web hitman for hire
Michaelhoise
how to shop on dark web best darknet market now https://versus-darkwebmarket.com/ - darknet market drug
WilliamQuego
list of darknet markets 2022 reddit darknet market 2022 https://asapdarkmarketonline.com/ - agora darknet market
Robertket
сайт даркнет мега onion оффициальный сайт https://hydramarket-online.link/ - зайти на мегу
Mattheworali
darknet drug prices uk dark markets belgium https://versusdarkwebmarkett.com/ - best darknet market uk
Jancib
dark markets sweden uncensored hidden wiki link https://webdrugs-darknet.shop/ - darknet markets still up
JosephBok
darknet markets wax weed trusted darknet markets weed https://dark-market-versus.com/ - dark web sales
HectorMug
как зайти на мегу мега сайт ссылка https://hydramarket-darkweb.link/ - mega onion
Granthub
darknet adress australian darknet markets https://cannahomeoniondarkweb.com/ - darknet market directory
RichardCyday
darkfox market url new darknet markets https://darkwebversus.com/ - reddit darknet market uk
ShaneLit
deep website search engine darknet market avengers https://asapmarket-url.com/ - dark web login guide
WilliamBlade
where to find darknet market links darknetlive https://asapdrugsonline.com/ - best dark web marketplaces 2022
DavidMob
the dark market dark web shopping https://asapdrugsmarketplace.com/ - darknet market stats
MichaelSware
ьупф ьфклуе darknet магазин https://hydramarketdarknet.link/ - мега нарко
BrandonTor
darknet market carding alphabay market link https://darkmarketversus.com/ - project versus
Jamesgox
darknet drug store best darknet market 2022 https://dark-web-versus.com/ - tor search onion link
MichaelCox
мэги сайт мега onion ссылка https://hydramarket-darknet.link/ - новое зеркало мега
Charlesjerce
incognito market onion directory https://asap-drugs-online.com/ - dark web sites links
Hansmog
dark markets macedonia top 10 dark web url https://asap-darknet-drugstore.com/ - dark web login guide
Juliusbop
darknet serious market darknet paypal accounts https://versus-darkweb.com/ - market links darknet
Timmylurry
best card shops darknet markets norge https://versus-darknet.com/ - darknet market links 2022 reddit
GeorgeThuth
darknet market canada dark web market list https://cannahomemarketplacee.com/ - buying drugs online on openbazaar
Dannymycle
dark web onion markets deep deep web links https://versusdarkmarketlink.com/ - onion links for deep web
JasonRab
blockchain darknet markets mdm love drug https://versus-marketplace24.com/ - bitcoin cash darknet markets
Jackiesix
мега онион мега онион https://hydramarketdarkweb.link/ - mega darkmarket
Sirtob
darknet drugs australia crypto market darknet https://asapdarkwebdrugstore.com/ - deep web drug markets
Justinfluff
black market drugs guns dnm market https://asapdarkweb.com/ - darknet black market sites
BrianBen
dark markets romania best darknet markets https://versusdarknet.com/ - top darknet drug sites
DamonPoday
darknet paypal accounts dark web buy credit cards https://asaponiondarkweb.com/ - active darknetmarkets
Geraldnob
online black market uk tor darknet markets https://asaponlinedrugs.com/ - dxm pills
WendellEnaky
updated darknet market list vice city link https://asap-onion-market.com/ - darknet dream market
CraigFaf
Heineken Express url darknet drug vendor that takes paypal https://asaponiondarkmarket.com/ - what is the best darknet market
BrandenTap
мега onion зеркало магазин даркнет https://hydra-market-onion.link/ - мега зеркало
HaroldImaby
darknet links market dark markets peru https://versusdarknetdrugstore.com/ - versus market
Smittjen
vice city market link drug market https://cannahome-darkweb-drugstore.com/ - dark web search engines 2022
Donaldrhisp
how to access the dark web through tor access the black market https://versus-drugs-online.com/ - which darknet market are still up
Randylog
darknet drugs germany darknet union https://versus-onion-market.com/ - darknet market arrests
DanielEncon
deep cp links dnm market https://asapdarkmarketplace.com/ - reddit darknet market links
Torntow
dark web electronics how to access the darknet market https://wwwdarkmarket.shop/ - darknet markets fake id
RandyZenny
new alphabay darknet market reddit darknet market superlist https://cypherdarkwebdrugstore.com/ - darknet live stream
EdgarFar
mega ссылка mega onion зеркало https://hydramarket-darkweb.link/ - mega onion зеркало
Richardkeymn
как зайти на мегу сайт даркнет https://hydra-market-onion.link/ - магазины даркнета
Ronaldimpak
buds express best darknet drug sites https://asapmarketplace24.com/ - dark web links
Jamesopike
underground market place darknet step by step dark web https://asap-onion-darkmarket.com/ - darknet market
Frankcit
onion market url back market legit https://asap-marketplace.com/ - deep web shopping site
RalphusafT
darknet drug market black market reddit https://asap-darkweb-drugstore.com/ - darknet illicit drugs
RobertGic
what is darknet markets xanax darknet markets reddit https://darkmarket-versus.com/ - darknet escrow markets
Michaelhoise
best darknet market for lsd url hidden wiki https://versus-drugs-market.com/ - cypher market
Zacharyhet
decentralized darknet market darknet market that has ssn database https://versus-onlinedrugs.com/ - darknet websites drugs
Mattheworali
darknet drugs url online drug market https://versusdarkwebmarkett.com/ - bitcoin darknet markets
WilliamQuego
darknet drugs market shop ccs carding https://asapdarkmarket.com/ - which darknet markets are still open
Jancib
black market prices for drugs darknet drug markets reddit https://webdrugs-darknet.link/ - how to buy from darknet
JosephBok
darkweb marketplace dark web search engines 2022 https://dark-market-versus.com/ - drugs on the deep web
HectorMug
мега onion ссылка мега зеркало https://hydramarket-darkweb.link/ - mega магазин
Granthub
underground card shop darknet list https://asap-online-drugs.com/ - 2022 working darknet market
DavidMob
the best onion sites dark markets macedonia https://asapdrugsmarket.com/ - incognito market
WilliamBlade
deep web cc shop cannazon url https://asapdrugsonline.com/ - deep web weed prices
RichardCyday
darknet drug dealer currently darknet markets https://darkwebasap.com/ - dark markets germany
ShaneLit
dark web sales deep web deb https://asapmarket-url.com/ - new onion darknet market
MichaelSware
ссылки на даркнет mega сайт https://hydramarketdarknet.link/ - mega онион
Timmylurry
top dark net markets cannazon market darknet https://versus-darknet.com/ - active darknet markets
Juliusbop
how big is the darknet market darknet market list links https://versus-darkweb-drugstore.com/ - cannahome
CharlesGet
best deep web markets dark markets singapore https://darkweb-asap.com/ - darknet serious market
Charlesjerce
dark web illegal links xanax darknet markets reddit https://asap-drugs-market.com/ - deep web search engine url
MichaelCox
мэги сайт мега официальный сайт https://hydramarket-darknet.link/ - мега онион сайт
Hansmog
buy ssn and dob darknet dream market https://asap-darknet-drugstore.com/ - illegal black market
GeorgeThuth
incognito market link dark web links https://cannahomemarketplacee.com/ - tor top websites
Dannymycle
black market sites 2022 mdm love drug https://versusdarkmarketlink.com/ - superlist darknet markets
JasonRab
dark markets portugal darknet market arrests https://versus-marketplace24.com/ - dnm xanax
Sirtob
darknet new market link ethereum darknet markets https://asapdarkwebmarket.com/ - cypher url
Jackiesix
мега onion оффициальный сайт магазины даркнета https://hydramarketdarkweb.link/ - мега onion зеркало
CrisUnano
bitcoin dark web darknet drug vendor that takes paypal https://wwwdarkmarket.link/ - open darknet markets
Justinfluff
decentralized darknet market best mdma vendor darknet market reddit https://asapdarkweb.com/ - tor markets 2022
BrianBen
market onion urls for darknet markets https://versusdarknet.com/ - Kingdom darknet Market
Geraldnob
reddit darknetmarket best darknet market 2022 reddit https://asaponlinedrugs.com/ - darknet market wiki
WendellEnaky
tor2door link black market drugs https://asap-onion-market.com/ - darknet market fake id
DavidSig
deep web onion url reddit darknet market guide https://versus-darkmarketplace.com/ - Cocorico link
BrandenTap
официальный сайт мега mega даркнет https://hydra-market-onion.link/ - мэги сайт
Jamesgox
drug markets dark web top ten dark web https://dark-web-asap.com/ - bitcoin market on darknet tor
CraigFaf
the real deal market darknet dark market onion https://asaponiondarkmarket.com/ - darknet market script
JamesVet
trusted darknet markets best darknet market may 2022 reddit https://asap-darkweb.com/ - shop ccs carding
HaroldImaby
working darknet markets counterfeit money deep web https://versusdarknetdrugstore.com/ - best deep web markets
Smittjen
dark markets guyana dark market url https://asap-darkmarket.com/ - dark markets hungary
Donaldrhisp
buy bank accounts darknet 2022 darknet markets https://versus-drugs-online.com/ - darkweb marketplace
Randylog
darknet search engine Heineken Express Market https://versus-onion-market.com/ - darknet drugs reddit
DanielEncon
deep market darknet websites https://asapdarkmarketplace.com/ - dark web drugs bitcoin
Jamesopike
darknet market 2022 reddit drugs on darknet https://asap-onion-darkweb.com/ - darknet market drug
EdgarFar
мега шишки mega магазин https://hydramarket-darkweb.link/ - даркнет магазин
PatrickDuelp
the darknet drugs tor darknet https://versus-dark-markett.com/ - the dark web url
Torntow
buds express darknet market fake id https://wwwdarkmarket.shop/ - darknet markets availability
Ronaldimpak
buying drugs on darknet Kingdom url https://asapmarketplace24.com/ - dark markets russia
RobertGic
darknet software market how to access the dark web on pc https://darkmarket-asap.com/ - dark markets belgium
Frankcit
darknet market black sichere darknet markets 2022 https://asap-marketplace.com/ - dark market
Julianacunc
darknet site wikipedia darknet market https://cannahome-marketplace.com/ - deep web drugs
Robertket
даркнет сайты магазин mega даркнет https://hydramarket-online.link/ - сылка на мегу
JosephBok
dark markets bosnia cannahome market link https://dark-market-versus.com/ - darknet market guide reddit
RalphusafT
best black market websites what darknet markets are available https://asap-darknet.com/ - legit darknet markets 2022
Michaelhoise
versus link buy drugs from darknet https://versus-drugs-market.com/ - darknet vendor reviews
SteveNek
сайт мега мега onion зеркала https://hydramarketdarkweb.link/ - mega сайт
ADangep
dark chart site darknet onion https://aasap-market.com/ - tor markets
HellySAr
darknet paypal accounts top dumps shop https://asap-darkmarket-online.com/ - reddit darknet markets uk
Mattheworali
darknet marketplace drugs darknet market guide https://versusdarkwebmarkett.com/ - counterfeit money onion
CorryBoura
black market deep darknet in person drug sales https://wwwdarknetmarket.link/ - reliable darknet markets lsd
Granthub
dark markets ecuador vice city market https://cannahomeoniondarkweb.com/ - incognito darknet market
Davidmab
adresse onion black market darknet drugs india https://web-darknet-market.shop/ - tor marketplace
Williamreoft
darknet drugs dublin darknet seiten dream market https://webdrugs-darknet.com/ - darknet links 2022 drugs
HectorMug
mega зеркало мега купить соль https://hydramarket-online.link/ - как зайти на мегу
BrandonTor
Kingdom Market url alphabay market darknet https://darkmarketversus.com/ - buying on dark web
Hilltob
link de hiden wiki deep web cc sites https://web-darknet-market.com/ - alphabay market darknet
DavidMob
bitcoin dark website darknet market search engine https://asapdrugsmarketplace.com/ - steroid market darknet
Jancib
dark web drugs bitcoin darknet marketplace https://webdrugs-darknet.shop/ - darknet market links buy ssn
RichardCyday
dark markets united kingdom darknet markets 2022 reddit https://darkwebversus.com/ - darknet drug trafficking
Charlesjerce
darknet drugs tor market list https://asap-drugs-online.com/ - reddit darknet market 2022
MichaelCox
мега шишки мега скорость https://hydramarket-darknet.link/ - магазин даркнет
Justinfluff
how to pay with bitcoin on dark web dark markets norway https://asapdarkweb.com/ - alphabay market url
CharlesGet
darkweb market black market prices for drugs https://darkweb-versus.com/ - darknet market listing
Hansmog
how to get to the black market online bohemia market https://asap-darkmarketplace.com/ - how to access the dark web on pc
BrianBen
back market legit black market illegal drugs https://versusdarknet.com/ - onion deep web search
JasonRab
onion deep web wiki darknet links 2022 drugs https://versus-marketplace24.com/ - new onion darknet market
Juliusbop
dark web buy bitcoin how to buy from the darknet markets lsd https://versus-darkweb-drugstore.com/ - top ten dark web sites
MichaelSware
mega ссылка даркнет магазин https://hydramarketdarknet.link/ - мега онион сайт
Jackiesix
darknet сайт сайт даркнет https://hydramarketdarknet.link/ - ссылка на мегу
Sirtob
uncensored hidden wiki link how to install deep web https://asapdarkwebmarket.com/ - deep deep web links
Timmylurry
alphabay market link new alphabay darknet market https://versus-darknet-drugstore.com/ - online black market electronics
JamesVet
links deep web tor dark markets malaysia https://asap-darkwebmarket.com/ - darknet market lists
Jamesgox
buying things from darknet markets onion market https://dark-web-versus.com/ - deep web cc dumps
HaroldImaby
deep deep web links drugs on the darknet https://versusdarknetdrugstore.com/ - xanax on darknet
DamonPoday
drug markets dark web darknet drugs url https://asaponiondarkweb.com/ - versus link
CrisUnano
how to buy bitcoin for the dark web deep net links https://wwwdarkmarket.link/ - dark markets netherlands
DavidSig
phenethylamine drugs deep web directory onion https://versus-darkmarket.com/ - darknet market black
Randylog
dark web market reviews darknet buy drugs https://versus-onion-market.com/ - deep web directory onion
BrandenTap
мэги сайт мега onion зеркала https://hydra-market-onion.link/ - mega сайт
RandyZenny
buy drugs on darknet dma drug https://cannahomemarket-darknet.com/ - darknet bank accounts
Donaldrhisp
darknet union darknet websites wiki https://versus-drugsonline.com/ - which darknet markets are up
Richardkeymn
мега ссылка mega онион https://hydramarket-darknet.link/ - mega darknet
Smittjen
dark web drugs australia urls for darknet markets https://asap-darkmarket.com/ - biggest darknet market 2022
CraigFaf
biggest darknet market french dark web https://asaponiondarkmarket.com/ - dark web markets 2022
Jamesopike
darknet drugs price deep web links updated https://asap-onion-darkmarket.com/ - darknet markets list reddit
EdgarFar
darknet сайт мега сайт ссылка https://hydramarket-darkweb.link/ - мега onion зеркала
PatrickDuelp
underground card shop darknet drugs shipping https://versus-dark-markett.com/ - nike jordan pill
Torntow
2022 darknet market top onion links https://wwwdarknetmarket.com/ - darknet market updates 2022
Frankcit
Heineken Express darknet dark web search engines 2022 https://asap-marketplace.com/ - dark web sites
RobertGic
dot onion websites versus project market url https://darkmarket-versus.com/ - tor market url
Julianacunc
darknet market vendors search darkmarket https://aversus-market.com/ - Kingdom Market url
HellySAr
darknet market litecoin Kingdom Market url https://asap-dark-market.com/ - dark web poison
ADangep
reliable darknet markets reddit dark markets bulgaria https://acannahome-market.com/ - darknet links markets
Robertket
мега купить мега onion ссылка https://hydramarket-online.link/ - мега вход
JosephBok
darknet market links reddit how to access dark web markets https://dark-market-asap.com/ - darknet guns market
RalphusafT
pink versace pill guide to darknet markets https://asap-darkweb-drugstore.com/ - darkfox market url
Michaelhoise
dark web market dark markets slovenia https://versus-darkwebmarket.com/ - redit safe darknet markets
Zacharyhet
how to buy from the darknet markets lsd best working darknet market 2022 https://versus-online-drugs.com/ - current list of darknet markets
Mattheworali
dark web drugs dark markets andorra https://versusdarkwebdrugstore.com/ - dark web hitman for hire
SteveNek
зеркало мега мега нарко https://hydramarketdarkweb.link/ - mega ссылка
WilliamQuego
dark markets paraguay tor market https://asapdarkmarket.com/ - darknet markets deepdotweb
Granthub
top 10 dark websites darknet markets lsd-25 2022 https://cannahomeoniondarkweb.com/ - alpha market url
Davidmab
dark markets moldova deep web drug store https://webdarknetmarkets.com/ - darknet market noobs guide
Williamreoft
darknet market dash onion link reddit https://webdarknetmarkets.link/ - best drug darknet
HectorMug
мега сайт мега онион https://hydramarket-darkweb.link/ - мега купить
DavidMob
alphabay darknet market darknet market comparison chart https://asapdrugsmarketplace.com/ - bitcoin darknet drugs
WilliamBlade
darknet serious market cvv black market https://asapdrugsonline.com/ - shop online without cvv code
BrandonTor
versus project market darknet sichere darknet markets 2022 https://darkmarketasap.com/ - dark markets germany
Jancib
what darknet markets are live dark markets china https://webdrugs-darknet.link/ - darknet union
RichardCyday
search darknet markets which darknet markets are still open https://darkwebasap.com/ - darknet drug market
ShaneLit
dark markets norway orange sunshine pill https://asapmarket-linkk.com/ - cp onion
Hilltob
new alphabay darknet market dark web hitman https://web-darknet-market.com/ - darknet market canada
Charlesjerce
wiki sticks drugs darknet drug market url https://asap-drugs-market.com/ - dark markets
GeorgeThuth
how to find the black market online darknet market links reddit https://cannahomemarketplace24.com/ - darknet список сайтов
Dannymycle
darknet market search engine top ten dark web sites https://versusdarkmarketlink.com/ - top dark net markets
MichaelCox
зеркало мега darknet магазин зелья https://hydramarket-darknet.link/ - mega даркнет
Justinfluff
dark net guide darknet adressen https://asapdarkweb.com/ - darknet market dmt
Hansmog
darknet drug markets asap market link https://asap-darknet-drugstore.com/ - drug market
JasonRab
active darknet markets 2022 best darknet market reddit https://versus-onion-darkmarket.com/ - dark markets south korea
CharlesGet
dark markets china links tor 2022 https://darkweb-versus.com/ - deep web search engine url
WendellEnaky
darknet prices darknet market updates 2022 https://asap-onlinedrugs.com/ - bitcoin dark website
Sirtob
dark web link darknet paypal accounts https://asapdarkwebmarket.com/ - lsd drug wiki
MichaelSware
мэги сайт мега вход https://hydramarketdarknet.link/ - мега onion оффициальный сайт
Jackiesix
мега шишки mega darkmarket https://hydramarketdarknet.link/ - darknet магазин
Jamesgox
fake id dark web 2022 reddit darknet market noobs https://dark-web-asap.com/ - adresse dark web
Timmylurry
shop on the dark web deep web hitmen url https://versus-darknet.com/ - deep web links 2022
JamesVet
illegal black market legit darknet markets https://asap-darkwebmarket.com/ - 2022 darknet market
DamonPoday
nike jordan pill buying drugs online on openbazaar https://asaponionmarket.com/ - which darknet markets accept zcash
Geraldnob
black market website legit dark markets lithuania https://asapurl.com/ - what darknet markets are live
CrisUnano
darknet market controlled delivery darknet market oz https://wwwdarkmarket.com/ - what is escrow darknet markets
DavidSig
darknet software market phenazepam pills https://versus-darkmarketplace.com/ - darknet market 2022 reddit
Randylog
deep web url links best darknet market for counterfeit https://versus-onion-darkweb.com/ - dark markets ukraine
DanielEncon
versus link pink versace pill https://asapdarknet.com/ - fresh onions link
BrandenTap
мега мефедрон мега onion ссылка https://hydra-market-onion.link/ - мега onion зеркала
RandyZenny
asap market darknet darknet dream market link https://cannahomemarket-darknet.com/ - darknet markets norway 2022
Donaldrhisp
deep web drug markets orange sunshine pill https://versus-drugsonline.com/ - blockchain darknet markets
Smittjen
darknet drugs guide dark markets paraguay https://cannahome-darkweb-drugstore.com/ - reddit darknet market superlist
Richardkeymn
mega onion сайты даркнет ссылки https://hydra-market-onion.link/ - mega магазин
CraigFaf
dark web legit sites dark web markets 2022 https://asaponiondarkmarket.com/ - darknet market wikia
Jamesopike
darknet market security deep dot web markets https://asap-onion-darkweb.com/ - fake id onion
PatrickDuelp
2022 darknet market dark web onion markets https://versus-darkmarket-online.com/ - drugs darknet vendors
EdgarFar
сайт даркнет мега onion ссылка https://hydramarket-darkweb.link/ - сайты даркнет
Frankcit
darknet drug links how to buy bitcoin and use on dark web https://asap-marketplace.com/ - underground hackers black market
Torntow
top dumps shop outlaw market darknet https://wwwdarkmarket.shop/ - darknet market onion links
ADangep
darknet market that has ssn database darknet drugs links https://aasap-market.com/ - dark markets andorra
CorryBoura
best dark web markets onion links for deep web https://wwwdarknetmarket.shop/ - best darknet market links
HellySAr
darknet market pills vendor reliable darknet markets https://asap-darkmarket-online.com/ - reddit darknet markets uk
RobertGic
deep web software market darknet black market sites https://darkmarket-asap.com/ - darknet market drug prices
Ronaldimpak
bitcoin cash darknet markets dark markets turkey https://asapmarket-urll.com/ - best current darknet market
JosephBok
how to pay with bitcoin on dark web darknet markets most popular https://dark-market-versus.com/ - dark market url
Julianacunc
darknet markets australia deep onion links https://cannahome-marketplace.com/ - the armory tor url
RalphusafT
black market sites 2022 darknet markets without login https://asap-darkweb-drugstore.com/ - darknet markets 2022 reddit
Zacharyhet
darknet gun market tor darknet market https://versus-onlinedrugs.com/ - dark market url
Robertket
darknet магазин мега официальный сайт https://hydramarket-online.link/ - mega онион сайт
Mattheworali
how to order from dark web dark web engine search https://versusdarkwebmarkett.com/ - cannazon market link
SteveNek
mega сайт магазины даркнета https://hydramarketdarkweb.link/ - мега onion ссылка
WilliamQuego
best dark web markets darknet market links safe https://asapdarkmarketonline.com/ - darknet market search
WilliamBlade
online drug market uncensored deep web https://asapdrugsonline.com/ - Heineken Express link
DavidMob
darknet list market darknet market vendors search https://asapdrugsmarketplace.com/ - lsd drug wiki
Granthub
darknet market list reddit updated darknet market list https://asap-online-drugs.com/ - darknet market list
HectorMug
сайты даркнет ссылки mega onion ссылка https://hydramarket-darkweb.link/ - мега мефедрон
BrandonTor
legit onion sites black market illegal drugs https://darkmarketversus.com/ - dnm xanax
Jancib
dark markets montenegro trusted darknet markets weed https://webdrugs-darknet.link/ - black market url deep web
ShaneLit
dark markets thailand versus market link https://asapmarket-linkk.com/ - dark web search engines link
RichardCyday
dark web links adult darknet vendor reviews https://darkwebasap.com/ - tor top websites
GeorgeThuth
Heineken Express darknet Market best card shops https://cannahomemarketplacee.com/ - darknet selling drugs
Dannymycle
what darknet market to use incognito darknet market https://versusdarkmarketlink.com/ - dark markets greece
MichaelCox
сайты даркнет мега onion https://hydramarket-darknet.link/ - как зайти на мегу
Justinfluff
duckduckgo dark web search buying drugs online https://asapdarknetdrugstore.com/ - alphabay market onion link
Hansmog
deep web markets onion directory 2022 https://asap-darkmarketplace.com/ - dark web engine search
JasonRab
guide to darknet markets best drug darknet https://versus-onion-darkmarket.com/ - reddit darknet market list 2022
CharlesGet
best darknet markets uk access the black market https://darkweb-asap.com/ - Abacus Market darknet
Sirtob
cannazone vice city link https://asapdarkwebdrugstore.com/ - tor darknet market
BrianBen
access the black market pyramid pill https://versusdarknet.com/ - darknet market links 2022 reddit
WendellEnaky
darkmarkets darknet market list reddit https://asap-onlinedrugs.com/ - french deep web link
Juliusbop
darknet market oz popular darknet markets https://versus-darkweb.com/ - cp onion
MichaelSware
магазин даркнет официальный сайт мега https://hydramarketdarknet.link/ - mega ссылка
Jackiesix
магазин даркнет mega market https://hydramarketdarkweb.link/ - mega onion ссылка
Timmylurry
how to get access to darknet darknet markets australia https://versus-darknet-drugstore.com/ - site darknet fermГ©
JamesVet
dark markets australia tor top websites https://asap-darkweb.com/ - darknet market alternatives
HaroldImaby
dark net market list reddit cannazon market url https://versusdarkweb.com/ - sichere darknet markets 2022
CrisUnano
darknet market reviews reddit darknet markets list https://wwwdarkmarket.com/ - onion websites for credit cards
Geraldnob
black market website names list of dark net markets https://asapurl.com/ - shop on the dark web
DamonPoday
darknet wiki link versus project market https://asaponiondarkweb.com/ - vice city market
Randylog
link de hiden wiki deep web shopping site https://versus-onion-darkweb.com/ - darknet market busts
DanielEncon
darknet market lists fake id onion https://asapdarkmarketplace.com/ - black market website
BrandenTap
mega даркнет мега onion магазин https://hydra-market-onion.link/ - mega onion зеркало
RandyZenny
dark web hitman for hire deep dark web https://cypherdarkwebdrugstore.com/ - assassination market darknet
Donaldrhisp
how to buy bitcoin for the dark web best lsd darknet market https://versus-drugs-online.com/ - buying things from darknet markets
DavidSig
darknet market canada darknet market noobs step by step https://versus-darkmarketplace.com/ - darknet market noobs step by step
Richardkeymn
mega ссылка mega onion оффициальный сайт https://hydra-market-onion.link/ - мэги сайт
CraigFaf
counterfeit money deep web dark web markets reddit https://asapmarketplacee.com/ - black market website
ADangep
bohemia link french deep web link https://acannahome-market.com/ - bitcoin black market
CorryBoura
darknet escrow how to get on the dark web https://wwwdarknetmarket.shop/ - darknet markets wax weed
HellySAr
onion directory list drug markets onion https://asap-dark-market.com/ - best darknet markets reddit
PatrickDuelp
red ferrari pills dark markets hungary https://versus-dark-markett.com/ - dark web sites drugs
Jamesopike
bohemia market darknet australian darknet markets https://asap-onion-darkweb.com/ - blockchain darknet markets
Frankcit
new darknet market reddit cypher market darknet https://asap-drugsonline.com/ - illegal black market
EdgarFar
магазины даркнета мега онион сайт https://hydramarket-darkweb.link/ - мега мефедрон
Torntow
best tor marketplaces credit card dark web links https://wwwdarkmarket.shop/ - darknet new market link
RobertGic
what bitcoins are accepted by darknet markets darknet market fake id https://darkmarket-asap.com/ - darkmarket list
Ronaldimpak
Heineken Express link shop online without cvv code https://asapmarketplace24.com/ - reddit darknet market how to
WilliamBlade
onionhub top darknet market 2022 https://asapdrugsonline.com/ - archetyp darknet market
Michaelhoise
reddit darknet market noobs bible Heineken Express link https://versus-darkwebmarket.com/ - top dark net markets
DavidMob
best darknet market now top darknet markets list https://asapdrugsmarket.com/ - how to access darknet market
Julianacunc
darkfox darknet market deep web software market https://aversus-market.com/ - darknet market reddit 2022
Zacharyhet
how to access the dark web safely reddit cannazon url https://versus-online-drugs.com/ - adresse onion black market
RalphusafT
how to search the dark web reddit dark web engine search https://asap-darkweb-drugstore.com/ - site darknet liste
SteveNek
mega даркнет mega onion зеркала https://hydramarketdarkweb.link/ - мега onion оффициальный сайт
Mattheworali
dark web market place links best darknet market 2022 reddit https://versusdarkwebmarkett.com/ - darknet live stream
WilliamQuego
how to use darknet markets dark markets usa https://asapdarkmarketonline.com/ - deep cp links
CharlesGet
darknet drug vendors list of dark net markets https://darkweb-asap.com/ - accessing darknet market
Robertket
ссылка на мегу mega onion https://hydramarket-online.link/ - мега купить соль
Granthub
how to access the black market working dark web links https://asap-online-drugs.com/ - darknet guns drugs
HectorMug
mega магазин мега onion ссылка https://hydramarket-darkweb.link/ - мега onion зеркало
BrandonTor
drug markets dark web dark net market list reddit https://darkmarketversus.com/ - versus project darknet market
Jancib
tor market links underground hackers black market https://webdrugs-darknet.shop/ - good dark web search engines
ShaneLit
black market website names best darknet market 2022 reddit https://asapmarket-url.com/ - darknet reddit market
Charlesjerce
darknet market place search dark market 2022 https://asap-drugs-market.com/ - darknet markets dread
RichardCyday
dark markets switzerland black market website review https://darkwebasap.com/ - which darknet markets accept zcash
GeorgeThuth
buy ssn and dob cannahome market darknet https://cannahomemarketplace24.com/ - where to find darknet market links redit
Hansmog
blacknet drugs dark web illegal links https://asap-darknet-drugstore.com/ - dynabolts pills
MichaelCox
darknet магазин зелья mega зеркало https://hydramarket-darknet.link/ - сайт даркнет
Justinfluff
what darknet markets sell fentanyl duckduckgo onion site https://asapdarkweb.com/ - darknet vendor reviews
JasonRab
darknet сайты список incognito market https://versus-marketplace24.com/ - reliable darknet markets lsd
Sirtob
darknet live markets brick market https://asapdarkwebdrugstore.com/ - darknet market list
BrianBen
tma drug what darknet market to use now https://versusdarkmarketplace.com/ - darknet market link updates
WendellEnaky
live dark web shop valid cvv https://asap-onion-market.com/ - pink versace pill
MichaelSware
мега onion зеркала зайти на мегу https://hydramarketdarknet.link/ - мега зеркало
Juliusbop
darknet market links 2022 reddit deep dark web https://versus-darkweb-drugstore.com/ - what darknet markets are still open
Jamesgox
darknet drugs shipping litecoin darknet markets https://dark-web-versus.com/ - adress darknet
CrisUnano
dark markets korea dark web in spanish https://wwwdarkmarket.com/ - accessing darknet market
DamonPoday
dark web links darknet market wikia https://asaponionmarket.com/ - darkshades marketplace
Randylog
deep web drug url deep web drug url https://versus-onion-darkweb.com/ - what darknet markets still work
DanielEncon
how to get on darknet market darknet market lightning network https://asapdarknet.com/ - darknet best drugs
RandyZenny
darknet list market onion links for deep web https://cypherdarkwebdrugstore.com/ - best card shops
Donaldrhisp
tor darknet sites darknet links markets https://versus-drugsonline.com/ - dark web links 2022 reddit
HellySAr
onion deep web search black market online https://asap-darkmarket-online.com/ - dark web in spanish
ADangep
buy ssn dob with bitcoin bohemia darknet market https://aasap-market.com/ - blockchain darknet markets
CorryBoura
working darknet market links best working darknet market 2022 https://wwwdarknetmarket.shop/ - trusted darknet markets
DavidSig
dark web xanax reddit working darknet markets https://versus-darkmarket.com/ - Kingdom darknet Market
Richardkeymn
зайти на мегу mega onion оффициальный сайт https://hydra-market-onion.link/ - официальный сайт мега
SteveNek
mega зеркало мега купить https://hydramarketdarkweb.link/ - официальный сайт мега
WilliamQuego
open darknet markets carding deep web links https://asapdarkmarket.com/ - reddit darknet reviews
Charlesjerce
cp links dark web darknet escrow markets https://asap-drugs-online.com/ - top darknet markets
Hansmog
black market drugs weed darknet market https://asap-darkmarketplace.com/ - dark markets mexico
MichaelCox
ьупф ьфклуе ссылка на мегу https://hydramarket-darknet.link/ - мега шишки
tutskimub
Studies of drug adherence have found that the percentage of individuals taking A P who were adherent to the drug regimen was higher than the percentage of individuals taking other antimalarial prophylactic drugs Goodyer et al. <a href=http://buydoxycyclineon.com/>doxycycline dose for acne</a> This medication is used to treat a wide variety of bacterial infections.
Virgie
medunitsa.ru Medunitsa.ru
Alexandria
slot machines casino no download casino mac realmoneyonlyhr baba free slots on facebook
JuaneVot
reduslim web oficial <a href=https://comprarcialis5mg.org/reduslim/>reduslim</a> reduslim ocu reduslim mercadona precio 2021 <a href=https://comprarcialis5mg.org/reduslim-kaufen/>reduslim kaufen</a> reduslim telefono cialis <a href=https://comprarcialis5mg.org/it/cialis-5mg-prezzo/>tadalafil 5 mg prezzo in farmacia</a> cialis https://sites.google.com/view/bitcoin-up-app/ <a href=http://www.bkpsdm.solokkab.go.id/berita-surat-edaran-kenaikan-pangkat-periode-1-oktober-2021.html>reduslim en farmacia</a> 6153498
Velma
Фильмы музыка сериалы онлайн
Sally
help writing paper paper writing service reviews college paper writing services
Duane
pay someone to write a paper for me buy a paper for college custom papers
Malinda
professional paper writers writing services for college papers pay to write my paper
Salvatore
paying someone to write a paper can someone write my paper for me custom writing paper service
Cleo
academic paper writing services academic paper writers need help write my paper
Alycia
websites that write papers for you write my economics paper write my sociology paper
Lanora
where can i find someone to write my college paper best paper writing service reviews writing paper services
Candida
where can you buy resume paper custom writing papers pay to write a paper
Kurtis
pay to write paper pay to do my paper buy papers online for college
Henrietta
where to buy papers help with filing divorce papers can someone write my paper
Erik
paper writing service college write my paper please write my paper co
Francesco
write my paper in apa format i need someone to write my paper where can i find someone to write my paper
Timothy
My relatives always say that I am wasting my time here at web, however I know I am getting experience everyday by reading thes good content. best darknet markets https://mydarkmarket.com
Tracee
need someone write my paper someone to write my paper for me buy literature review paper
Caleb
Oh my goodness! Impressive article dude! Thanks, However I am going through difficulties with your RSS. I don’t understand why I can’t subscribe to it.
Is there anybody getting identical RSS issues? Anybody who knows the solution can you kindly respond? Thanks!! dark market https://alphabay-dark-market.com
Gene
I love reading a post that can make men and women think. Also, thanks for allowing me to comment!
alphabay market url https://alphabay-market-linkss.com
UicmjaefInfut
spedra <a href=https://comprarcialis5mg.org/it/comprare-spedra-avanafil-senza-ricetta-online/>avanafil generico prezzo</a> Avanafil
Carey
custom papers writing paper writers online buy college papers
Irene
Прописка в Санкт-Петербурге
Tressa
Временная регистрация в Санкт-Петербурге
Maddison
Аренда трала в Москве
Marguerite
Эротический массаж Уфа
Willard
Временная регистрация в Санкт-Петербурге
Shayne
Эротический массаж Уфа
Lisa
Компьютерный клуб в Уфе
David
Hey there! Would you mind if I share your blog with my twitter group? There’s a lot of people that I think would really appreciate your content. Please let me know. Cheers dark markets 2022 https://alphabay-markets.com
Marvinelamn
cialis 5 mg <a href=https://comprarcialis5mg.org/>comprar cialis</a> cialis
Madeleine
Very nice post. I just stumbled upon your blog and wished to say that I’ve really enjoyed surfing around your blog posts.
In any case I will be subscribing to your rss feed and I hope you write again soon! alphabay darknet link https://alphabaydarknetmarket.com
Evie
Great article. dark web market list https://alphabaydarkmarkets.com
Ngan
Деревообрабатывающие станки купить в Москве
Pat
Hmm is anyone else encountering problems with the images on this blog loading? I’m trying to find out if its a problem on my end or if it’s the blog.
Any feedback would be greatly appreciated. alphabay Darkweb https://alphabaydarkwebmarket.com
GeorgeAgoke
For the first time I became interested in sex toys at the age of 19-20. After graduation, I worked a little and got the opportunity to pamper myself. Moreover, there was no relationship then, and sex too … Around the same time, there was the first visit to the sex shop - a very exciting event! I decided more than a month, and until the last I doubted, but the desire to experience something “special” still overpowered. I remember I was very excited at the mere thought that I would have to walk and look, tell the sellers what you want to buy, and how they would look at you after that … After a month of doubts, I still came. Half an hour looking for the entrance to the sex shop. I walked around the building 10 times, but there was no sign of the entrance. Just a residential building with a few shops - no signs, no signs, nothing at all. And the entrance was inside one of the usual shops. Well camouflaged. Later, a sign was also found - small, modest and completely inconspicuous. The sex shop https://self-lover.store/smazki-dlya-muzhchin/1242/ had a nice atmosphere, dim lights and no one but 2 male salespeople. The room was divided into several thematic parts. The first had only sex toys, the second was all for role-playing, and the third was erotic lingerie. Walked and looked. Not to say that he was very shy, but he still experienced a certain tension. For the first time I took a few toys:
Elida
Адвокат по уголовным делам в Москве
canadian pharmacy rx
online drug https://greatcanadianpharmacies.com/ <a href=https://greatcanadianpharmacies.com/>reputable canadian mail order pharmacy</a>
Kristin
сверлильный станок
Michailumk
Здравствуйте дамы и господа! Мебель для офиса.Кабинет руководителя. Солидные комплекты, способные произвести впечатление. Производятся из элитных материалов, подчеркивающих статус руководителя. Комплекты для кабинета руководителя включают столы, комфортные кресла, тумбы, шкафы для хранения бумаг.Офисные кресла. Обладают надёжной конструкцией. Производятся из износостойких материалов. Обеспечивают высокий уровень комфорта и мягкую поддержку спины. Различают кресла для руководителей, рядовых сотрудников и посетителей.Офисные столы. Имеют эргономичную конструкцию, просторную столешницу, лаконичный дизайн. Различают столы для кабинетов руководителей, обустройства рабочих мест рядовых сотрудников, комнат отдыха. Они также могут быть письменными, компьютерными, приставными.Офисные диваны. Устанавливаются в комнатах отдыха для сотрудников и приёмных офисов. Бывают двух, трёх и четырёхместными. Мягкие диваны производят из износостойких материалов, требующих минимального ухода.Офисные шкафы. Предназначены для хранения документации, оргтехники, канцелярских принадлежностей, личных вещей и одежды сотрудников. Бывают мало- или крупногабаритными, с одной или несколькими створками, открытыми, комбинированного типа и т. д. http://www.ts-gaminggroup.com/member.php?70162-Michailadd http://www.peyronnet.eu/forum/viewtopic.php?f=4&t=138146 https://yandexforum.ru:443/member.php?u=146722 https://shaderxstudios.com/forum/viewtopic.php?f=4&t=101662 https://forum.marycoin.org/member.php?155498-Michaildwj
Lucas
Hello There. I found your blog using msn. This is an extremely well written article. I’ll be sure to bookmark it and return to read more of your useful information. Thanks for the post. I’ll definitely comeback. alphabay darknet https://alphabaylinkonion.com
Dirk
Wonderful article! This is the kind of information that are meant to be shared across the net.
Disgrace on Google for now not positioning this submit higher! Come on over and talk over with my web site . Thanks =) dark web link https://alphabaymarket-onion.com
Victoradl
Приветствую Вас господа[url=https://vika-service.by/]![/url] Для заправки лазерного принтера не нужно иметь специального образования и десятилетия опыта, но нужно иметь инструмент и понимание того, что ты делаешь. Самостоятельное вмешательство в работу техники допустимо, даже необходимо! Тем самым вы не оставите компаний вроде нашей без работы. Заправляем лазерные картриджи ведущих мировых производителей – hp, canon, samsung и другие. Работаем с моделями увеличенного объема. Заправляем картриджи с выездом в офис. Это позволяет сэкономить ваше время и не отвлекаться от основной работы. Наша фирма занимается свыше 10 лет ремонтом и обслуживанием оргтехники в городе Минске. Мы будем рады Вас видеть у нас на сайте Всегда рады помочь Вам!С уважением,ТЕХНОСЕРВИC http://forum.soundspeed.ru/member.php?479389-Victoroxo http://tnd-mafia.de/viewtopic.php?f=10&t=47782 http://htcclub.pl/member.php/126539-Victorlhf http://w.darkagewars.com/forums/member.php?u=161548 https://cs-wz.ru/user/Victorbup/
Franklin
Oh my goodness! Incredible article dude! Thank you, However I am going through troubles with your RSS. I don’t know the reason why I am unable to subscribe to it. Is there anyone else getting the same RSS problems? Anyone that knows the answer can you kindly respond? Thanx!! alphabay market link https://alphabaymarketdarknet.com
Stephany
Spot on with this write-up, I actually believe that this web site needs a lot more attention. I’ll probably be returning to see more, thanks for the information! alphabay onion https://alphabaymarket24.com
Tarah
Hello, after reading this amazing paragraph i am too glad to share my knowledge here with friends.
Marinaqha
Приветствую Вас господа! Предлагаем Вашему вниманию сервис оргтехники и продажу расходников для дома и офиса.Наша организация «КОПИМЕДИАГРУПП» работает 10 лет на рынке этой продукции в Беларуси.ЗАПРАВКА КАРТРИДЖЕЙ В МИНСКЕ.Заправляем все типы картриджей лазерных принтеров и МФУ.Ремонт принтеров и обслуживание офисной техники.Продажа картриджей собственного производства. Работаем на рынке более 10 лет. Более 1000 организаций воспользовались нашими услугами!Заправляем картриджи на выезде у Заказчика, так и в нашем Сервисном Центре (выезд курьера от 5 картриджей в обе стороны - бесплатно. На время заправки оставляем подменные картриджи, чтобы ваша работа не останавливалась);Не экономим на качестве, используем расходные материалы высокого качества, ведущих мировых производителей Imex, Tomoegawa, Mitsubishi (Япония), StaticControl (США) и др.;Наличный и безналичный расчет. Оплата по факту выполненной работы. Гибкие условия оплаты, отсрочка платежа; Гарантия на выполненные работы. Средний срок выполнения работ - 1 раб. день;Бесплатная консультация по обслуживанию и работе с офисной техникой, приобретению офисной техники и расходных материалов к ней; http://mesovision.com/forum1/viewtopic.php?f=12&t=213280&p=332612#p332612 https://astraclub.ru/members/203244-Marinalvy https://carbis.ru/forum/member.php/335407-Marinavuz http://forum.shopheroesgame.com/viewtopic.php?f=20&t=416529 http://isolationstation.langtoontimes.com/viewtopic.php?f=15&t=578751
Joni
I like the helpful information you provide in your articles. I’ll bookmark your weblog and check again here frequently. I am quite certain I will learn lots of new stuff right here! Best of luck for the next! darkmarket 2022 https://alphabaymarketlinkwww.com
Rosalie
Пластиковые окна купить в Москве
Jodi
Excellent post however , I was wondering if you could write a litte more on this subject? I’d be very grateful if you could elaborate a little bit more. Thanks! Best Hair salon in patong https://www.instagram.com/badmonkeybarbershoppatong/
Antoniofvh
Здравствуйте дамы и господа!Есть такой интересный сайт для заказа бурения скважин на воду. Бурение скважин в Минске компанией ЕВРОБУРСЕРВИС – полный комплекс качественных и разумных по цене услуг. Мы бурим любые виды скважин.У нас доступная ценовая политика, рассрочка на услуги и оборудование.Заказывайте скважину для воды в euroburservice – получите доступ к экологически чистой природной воде по самым выгодным в Минске ценам! При создании системы канализации загородного дома важно: Правильно подобрать подходящую систему канализации,действительно способную решить проблему именно в ВАШЕМ доме, одновременно не переплачивая за лишнюю мощность и ненужные опции. Система автономной канализации может быть одного из двух основных типов:наружная, её основная задача — отвести отходы от дома и передать их в магистральную канализационную линию; локальная канализация: для вывода, утилизации и обезвреживания отходов в условиях отсутствия централизованного отвода сточных вод. Грамотно смонтировать выбранную систему канализации. Только грамотный монтаж гарантирует вам надежную и бесперебойную работу выбранной дорогостоящей системы. Канализация в Минске под ключ по низким ценам. Монтажом систем автономной канализации загородного дома занимается отдельная специализированная бригада. Именно специализация позволяет точно и заранее предусмотреть все нюансы монтажа системы канализации для загородного дома. Актуальную стоимость монтажа популярных станций биологической очистки сточных вод узнавайте по телефону. От всей души Вам всех благ! http://tattooforum.com/viewtopic.php?f=9&t=894256 http://forums.panzergrenadiers.com/member.php?34261-Antonioytc http://forums.outdoorreview.com/member.php?287008-Antonioono http://top-il.kz/user/Patriotfxj/ http://oldpeoplewholikebirds.com/forum/memberlist.php?mode=viewprofile&u=65303
Ashley
Howdy! Someone in my Facebook group shared this site with us so I came to check it out. I’m definitely loving the information. I’m book-marking and will be tweeting this to my followers! Terrific blog and excellent design and style.
mens beauty salon near me https://www.facebook.com/BadMonkeyBarberShopPhuket
Antoniokqj
Привет товарищи! http://w.darkagewars.com/forums/showthread.php?p=836277#post836277 http://forum.exalto-emirates.com/viewtopic.php?f=7&t=160&p=369961#p369961 http://egyhunt.net/member.php?u=303663 https://potsmokerslounge.com/forum/showthread.php?t=33279&p=107383#post107383 http://www.flyanglersonline.com/bb/member.php?474432-Antoniooxt Предлагаем Вашему вниманию высококачественные профессиональные плёнки. Наша организация работает 15 лет на рынке этой продукции в Беларуси. С древних лет известно выражение, «наш дом – наша крепость», и в наши дни разработано множества вариантов защиты имущества. Защитная плёнка для окон внесёт свой вклад в обеспечение вашей безопасности. Самоклеющаяся пленка для стекла особенно востребована тем людям, чьи квартиры находятся на первых этажах, а также она подходит стеклянным витрин и перегородкам. Впервые такое изобретение появилось в США, в 60-х годах. С каждым годом противоударные покрытия становятся крепче, надёжнее и красивее. На них начали наносить рисунки, напылять различные компоненты – теперь они не только придают безосколочность окну, но и делают их красивыми и оригинальными.
canadian prescription drugs
rx online no prior prescription https://canadianpharmaciesshop.com/ [url=https://canadianpharmaciesshop.com/]legitimate online pharmacies[/url]
Thurman
Wow that was odd. I just wrote an very long comment but after I clicked submit my comment didn’t show up. Grrrr… well I’m not writing all that over again. Anyways, just wanted to say superb blog! dark web market https://alphabaymarketlinktor.com
Antoniovxw
Привет господа! Предлагаем Вашему вниманию высококачественные профессиональные плёнки. Наша организация”ООО Защитные плёнки” работает 15 лет на рынке этой продукции в Беларуси. Технология нашей работы позволяет превратить обыкновенное стекло в прочную конструкцию, которая в зависимости от назначения, сочетает в себе одну или несколько функций пленок. Наши специалисты быстро и качественно установят защитные и ударопрочные пленки в банках, магазинах и других административно-хозяйственных учреждениях. Установка таких пленок является необходимым условием при сдаче вышеперечисленных объектов под защиту Департамента охраны МВД. Более подробная информация размещена https://drive.google.com/file/d/1InniZTJn0UKaO9qp8AMrkpf0ykv3rq9m/view?usp=sharing С уважением,коллектив “ООО Защитные плёнки”.
Michailzmc
Добрый день товарищи! http://www.ts-gaminggroup.com/member.php?91415-Michailmmg http://forum.soundspeed.ru/member.php?592459-Michailene https://forum.americancasinoguide.com/member.php/74339-broertosfrances1277 https://yandexforum.ru:443/member.php?u=146631 http://www.globalgamers.co/forums/member.php?49119-Michailtso Каким должно быть компьютерное кресло?Обеспечение комфорта во время работы - это 50% успешной производительности. Будь то домашняя атмосфера или офисная – все мы стремимся к удобному оснащению рабочего места. Сделать правильный выбор в широчайшем ассортименте компьютерных кресел Вам поможет наш интернет-магазин.На нашем сайте вы найдете продукцию брендов, которым покупатели доверяют уже на протяжении долгого времени, благодаря зарекомендованным позициям качества и доступности в цене на рынке.В зависимости от Ваших предпочтений, возможностей и целей использования компьютерного стула, наши менеджеры помогут Вам определиться в выборе товара. Мы предоставляем гарантию на товар и осуществляем быструю доставку компьютерных стульев по России.Интернет-магазин предоставляет возможность своим покупателям найти и купить компьютерное кресло различных моделей, каждое из которых не уступает любому другому по своим техническим характеристикам:Для детей;Для геймеров;Для дома;Для столовой;Для бара;Для руководителя;Для офисных сотрудников;Для посетителей;Ортопедические;Компьютерные.Где можно купить офисные стулья и кресла?В каталоге нашего сайта Вы сможете подобрать для себя самое выгодное предложение по цене, производителю, техническим и функциональным показателям, опираясь не только на описание, но и на фото.У нас вы сможете совершить покупку выгодно и недорого. Большой выбор, доступные цены, актуальное наличие, высокое качество, гарантия на продукт, положительные отзывы покупателей – наш ориентир успешной работы.
Jessika
Временная регистрация в Москве
Fred
I like the valuable information you provide in your articles.
I will bookmark your blog and check again here frequently. I’m quite certain I’ll learn plenty of new stuff right here! Best of luck for the next! dark market 2022 https://alphabaymarketonion.com
Annette
You ought to be a part of a contest for one of the best sites on the internet. I will recommend this blog! darknet market lists https://alphabaymarketonline.com
datafastproxiespx01
IPv6 Proxy for Process Automation on Whatsapp (WhatsApp Chatbot, Whatsapp Registration, Whatsapp Connection)!
There is a large industry of automation development for Whatsapp, thanks to a great need to offer Automation of several processes with Whatsapp, whether using Official Whatsapp Client (Android, iOS, Whatsapp Web) or using unofficial Clients (Chat-Api MGP25, Yowsup), even our own Reverse Engineering Whatsapp solutions!
In all Automation processes for Whatsapp, good practices require the use of Proxies for control and prevention of possible bans, as Whatsapp owners (Meta, Facebook), prohibit the use of unofficial Whatsapp Customers or even Customer Automation official (Except using their official API!
DataFat Proxies has the most perfect and Definitive IPv6 Proxy Agent Solution for Whatsapp, developed to give you maximum security, stability and scalability!
The Automation Industry for Whatsapp requires you to work with Geographically located IPv6 Proxy, so that success during the registration of new Whatsapp accounts is even more assertive. With DataFast Proxies you can currently count on 46 Geographic Locations from where you can get High Quality IPv6 Proxy and High Speed!
DataFast Proxies | Definitive Solution in IPv6 Proxy! https://datafastproxies.com/
Contact: https://datafastproxies.com/contact/
Jubairlykemia
Распродажа футбольной одежды и атрибутики с символикой любимых футбольных клубов. Примерка перед покупкой, магазин футбольной атрибутики. Быстрая доставка по всем городам РФ. [url=https://futbol66.ru]атрибутика футбольных клубов[/url] купить футбольную форму - [url=http://futbol66.ru]http://www.futbol66.ru[/url] [url=https://www.google.sr/url?q=http://futbol66.ru]http://cse.google.am/url?q=http://futbol66.ru[/url]
[url=http://grospoissons.com/general.htm]Спортивная одежда для футбола с примеркой перед покупкой и быстрой доставкой в любой город РФ.[/url] 000c856
Gertie
Pretty! This has been an extremely wonderful article. Thanks for providing this info. dark market 2022 https://alphabaymarketsonion.com
Cerys
I am really impressed with your writing skills and also with the layout on your blog. Is this a paid theme or did you customize it yourself? Anyway keep up the excellent quality writing, it’s rare to see a great blog like this one today. Dark Web Markets https://alphabaymarketsdarknet.com
Samantaiqo
Здравствуйте друзья[url=https://ccwater.kiev.ua/].[/url] http://galacticarmada.com/forum/viewtopic.php?f=4&t=65379 http://tsxvresearch.com/forum/viewtopic.php?f=6&t=21519 http://chernigov.info/member.php?u=612564 http://zrosha.ru/phpBB3/viewtopic.php?f=11&t=25175 http://49.majnguyen.com/viewtopic.php?f=4&t=1435
Мы - это не только то, что мы едим, но и то, что мы пьем. Ежедневно для поддержания здоровья и восполнения запасов энергии взрослый человек должен потреблять не менее 1,5 л чистой воды. Вода также необходима для утоления жажды и выведения шлаков и токсинов из организма, для поддержания молодости и похудения. Неспроста наш организм состоит на 70% из жидкости. Поэтому важно следить не только за количеством, но и за качеством потребляемой жидкости в своем ежедневном рационе.Водопроводная вода содержит множество хлора, металлических примесей, солей и вредных веществ, поэтому даже после кипячения и/или домашней фильтрации она не пригодна для питья или приготовления пищи. Полезной, вкусной и безопасной для ежедневного употребления является артезианская вода из райского источника, заряженная силой природы, очищенная и сбалансированная. Именно такой является. Уровень качества воды оказался настолько хорош, что ее можно смело назвать «райским источником». Впоследствии здесь был построен завод по добыче и розливу воды, а спустя 10 лет появляются новые виды воды. С развитием компании мы внедряем новые технологии, открываем лабораторные центры и расширяем свой ассортимент. На сегодняшний день мы, в первую очередь, преследуем гуманную миссию - о поставке чистой питьевой воды, которая поспособствовала бы оздоровлению человечества. Наши труды не остались незамеченными, и нам доверяет крупнейшие компании-гиганты, среди которых:ИСТОЧНИК ВОДЫ.Прежде, чем мы нашли нашу лучшую артезианскую воду, мы исследовали около 300 различных источников. Скважина находится на глубине 167 метров под землей и отделена от поверхностных вод, поэтому ее химический и органолептический состав остаются неизменными даже спустя десятилетия.природная вода без цвета, вкуса и запаха - чистая и прозрачная, как слеза. Ее состав максимально полезен, благодаря отсутствию химикатов и наличию естественного минерального содержания.Для того, чтобы гарантировать потребителям райское качество питьевой воды мы создали лабораторию при заводе, которая ежедневно и ежечасно проводит микробиологические и химико-физические обследования добытой и бутилированной воды. Исследуется прозрачность, вкусовые характеристики, аромат (органолептика), минеральный состав, присутствие в ней нежелательных веществ и патогенной среды.кристально чистая вода, основными отличительными особенностями которой являются:экологичность - добывают воду из скважины, расположенной в экологически чистом районе из месторождения юрского водоносного горизонта;идеальный состав - вода очищается от примесей и химикатов благодаря многоступенчатой системе фильтрации, а ее физические, химические и микробиологические свойства остаются максимально приближенными к чистой родниковой воде;безопасность - благодаря идеальному соотношению комплекса минералов и микроэлементов, питьевая вода полностью безопасна для взрослых и детей;приятный и естественный вкус, бесцветность и отсутствие навязчивого аромата - вода добывается из скважины уже пригодной для употребления, наша задача - только улучшить то, что дано природой. Естественный вкус сохраняется и очень отличается от очищенной водопроводной воды.Наша служба доставки воды предлагает 3 разновидности водички:ПОЛЬЗА ДЛЯ ОРГАНИЗМА.Чтобы быть здоровым и хорошо выглядеть необходимо спать не менее 8-ми часов в сутки, полезно и сбалансированно питаться и, конечно же, пить ежедневно не менее 1,5-2 литров чистой воды. Качество питьевой воды можно определить по цвету, запаху и вкусовым составляющим. Такая вода не просто рекомендована, она критически необходима человеку для:улучшения метаболизма и нормализации пищеварения. Способствует лучшей выработке ферментов. Вместе с кровотоком «доставляет» полезные вещества в органы и системы человека;очищения от шлаков и токсинов. Вместе с потом и мочой вода из организма выводятся токсичные вещества;укрепления зубной эмали и костей. Фториды, содержащиеся в питьевой воде, предотвращают развитие кариеса и истончение костной ткани; нормализации водного баланса. Предупредить преждевременное старение и улучшить состояние кожи также можно при поддержании уровня Ph;снижения веса. Недостаток жидкости может спровоцировать появление целлюлита и ожирения. Для ускорения процесса похудения диетологи рекомендуют придерживаться индивидуального питьевого режима, и, конечно же, правильного питания и физических нагрузок.Кроме этого заказ питьевой воды и поддержание водного баланса способствует улучшение работы нервной системы, предотвращает развитие мочекаменной болезни и головных болей, снижает артериальное давление. Только самая чистая вода способна восполнить запасы энергии, подарить бодрость, здоровье и хорошее настроение.Уже сейчас Вы можете купить питьевую воду в Киеве с адресной доставкой. Проявите заботу о своем организме - пейте чистую райскую воду.НОРМЫ ДЛЯ ЧЕЛОВЕКА.Вы уже знаете, что польза питьевой воды для человека огромна, и что только природная вода способна оздоровить организм. Диетологи и специалисты по питанию единогласно утверждают, что взрослый человек должен выпивать не менее 1,5-2 л чистой натуральной воды в день. С чем это связано? Как мы уже говорили, вода необходима для нормального пищеварения. Если человек испытывает ее недостаток, то это может привести к тому, что снижается количество желудочного сока (ферментативная недостаточность). В результате это провоцирует замедление и ухудшение переваривания пищи, проблемы с метаболизмом, появление лишнего веса и весь спектр проблем с ЖКТ. Чтобы решить вопрос с диетой и питанием, в первую очередь необходимо заказать доставку воды. Она - является источником множества минералов и микроэлементов, благодаря которым можно поддерживать здоровье, энергичность и свежий внешний вид. С ее помощью улучшается процесс переваривания и усваивания пищи. Таким образом, доставка воды - это пункт №1 для тех, кто стремится скинуть лишние килограммы, нормализовать работу желудочно-кишечного тракта или просто поддерживать тело в тонусе.ПОКАЗАТЕЛИ КАЧЕСТВА ВОДЫ.Какой должна быть хорошая питьевая вода? В первую очередь, она должна быть чистой, как слеза, иметь приятный вкус и аромат. А еще хорошо, если она будет содержать калий, кальций, фтор, магний, натрий. Данные компоненты должны поступать в организм человека с едой или жидкостью каждый день. Только так можно обеспечить употребление полного комплекса полезных минералов и микроэлементов.Показатели качества питьевой воды определяются ее органолептическими и химико-биологическими характеристиками. Согласно тому, что кроме полезных, существуют и вредные минералы (например, хлор и соли тяжелых металлов), полностью очистить воду от них не получится, но свести их количество к минимум - вполне. Поэтому лучшая вода - это вода с наименьшим показателем минерализации.Следует также понимать, что питьевая и минеральная вода - это два разных вида воды. Первая - идеальна для ежедневного употребления и приготовления пищи. Вторая, за счет содержания в ней высокой концентрации полезных минералов, может применяться только в лечебных целях (согласно рекомендаций лечащего врача по строго определенной схеме).Получить детальную информацию о качестве и физико-биологическом составе воды позволяет лабораторный тест для питьевой воды. По многочисленным исследованиям, проводимым в наших лабораториях, вода - идеальна для питья и приготовления пищи, не содержит патогенных примесей и богата полезными минералами и микроэлементами.ГОСТ.На сегодняшний день качество централизованной питьевой воды в Украине регламентируется ГОСТом 2874-82 «Вода питьевая. Гигиенические требования и контроль за качеством». Вместе с тем Приказом Министерства охраны здоровья Украины от 23.12.1996 г. №383 утверждены Государственные санитарные нормы и правила «Вода питьевая. Гигиенические требования к качеству воды централизованного хозяйственно-питьевого водоснабжения» (ГСанПиН).Согласно вышеуказанным нормативам, оценивают воду по таким критериям:органолептика;токсикология;эпидемиология.К сожалению, анализы питьевой воды из централизованного водопровода показывают, что ни один из показателей не соответствует установленным нормам в полной мере. Простыми словами - вода из под крана не годится для питья и приготовления еды.чистая вода с идеальными органолептическими характеристиками, в которой отсутствует токсикологическая среда и содержится высокий природный уровень минералов. Поэтому она полностью соответствует требованиям ГОСТа. Наша питьевая вода высшей категории занимает самый высокий рейтинг среди в списке качественной воды в Киеве с доставкой по адресу. Мы внимательно следим состоянием и составом воды на каждом этапе: от добычи до розлива и доставки. И неустанно исследуем ее на предмет наличия патогенных микроорганизмов, примесей тяжелых металлов, солей и пр. От всей души Вам всех благ!
Kareem
We’re a gaggle of volunteers and starting a new scheme in our community. Your site provided us with helpful info to work on. You have performed an impressive activity and our whole neighborhood can be thankful to you. Alphabay Darkweb Link https://alphabaymarketurls.com
Bogdanext
Здравствуйте дамы и господа! https://queponqueen.com/author/bogdanvja/ https://grapmintv.com/forum/viewtopic.php?f=10&t=44201 http://badassmofos.com/forums/viewtopic.php?f=2&t=36&p=547579#p547579 http://aoooir.kz/user/Bogdanpjm/ http://oderalon.net/home/viewtopic.php?f=74&t=45270 Предлагаем Вашему вниманию изделия из стекла для дома и офиса.Наша организация ООО «СТЕКЛОЭЛИТ» работает 10 лет на рынке этой продукции в Беларуси.Офис сегодня – это не пыльная комната в панельном здании, а лицо компании, его визитная карточка. Во многом это определяет интерьер, но также огромное значение имеют дверные конструкции и стеклянные перегородки в офисе. Появившись в качестве перегородок достаточно давно, стеклянные стены использовались чаще всего просто в качестве разделителя помещения, и только недавно они вошли в список интерьерных изюминок. В своих конструкциях мы используем стекло от лучшего мирового производителя листового стекла AGC GLASS EUROPE. Увидимся!
Bogdanmig
Добрый день друзья! Более подробная информация размещена https://drive.google.com/file/d/1dvAKJyEOOME6UOwkqlaXD570mM28fJWy/view?usp=sharing Предлагаем Вашему вниманию изделия из стекла для дома и офиса.Наша организация ООО «СТЕКЛОЭЛИТ» работает 10 лет на рынке этой продукции в Беларуси.Стоит задача грамотно и недорого организовать офисное помещение в короткий срок? Возникли трудности с планировкой? Предлагаем оптимальное решение — современные офисные перегородки на заказ, которые позволят офис разделить по отделам или предоставить каждому сотруднику личное рабочее пространство для спокойной, уединенной работы. От всей души Вам всех благ!
Andreassss
Доброго времени суток друзья! http://d3.darkagewars.com/forums/showthread.php?p=701568#post701568 https://truewow.org/forum/memberlist.php?mode=viewprofile&u=10330854 http://vnsharing.site/forum/member.php?u=2566619 https://carbis.ru/forum/member.php/327005-Andreastnl http://shkola3-chp.ru/forumphp/viewtopic.php?p=258926#p258926 Предлагаем Вашему вниманию интересный сайт для заказа бурения скважин на воду. Бурение скважин в Минске – полный комплекс качественных и разумных по цене услуг. Мы бурим любые виды скважин.У нас доступная ценовая политика, рассрочка на услуги и оборудование.Заказывайте скважину для воды – получите доступ к экологически чистой природной воде по самым выгодным в Минске ценам! Наша сфера деятельности — проектирование и бурение скважин на воду, установка любого насосного оборудования, монтаж систем канализации всех видов, дренажей, ливневых систем и др.Миссия компании: мы добываем чистую воду – источник всего живого на Земле, и делаем ее доступной людям. Самый короткий срок, за который мы пробурили и обустроили скважину, — 1 час 36 минут. Мы ценим время своих клиентов и гордимся, что оперативность — отличительное свойство наших услуг. Мы показываем, насколько быстро и качественно может происходить бурение скважины. От всей души Вам всех благ!
Karol
coursework or course works coursework login coursework define
Lucienne
coursework planner coursework presentation quantitative coursework
Andreasrhx
Приветствую Вас дамы и господа! https://drive.google.com/file/d/1Z3XEpblaCaEBdSLzZP8E22b0ZjbBT3QO/view?usp=sharing Предлагаем Вашему вниманию замечательный сайт для заказа бурения скважин на воду. Бурение скважин в Минске – полный комплекс качественных и разумных по цене услуг. Мы бурим любые виды скважин.У нас доступная ценовая политика, рассрочка на услуги и оборудование.Заказывайте скважину для воды – получите доступ к экологически чистой природной воде по самым выгодным в Минске ценам! Почему роторное бурение — более результативное? Роторное бурение в МинскеКогда бурится менее глубокая, фильтровая скважина, то используется обычное долото-резец и шнеки (стержень со сплошной винтовой поверхностью вдоль продольной оси), которые «ввинчиваются» в породу. При роторном бурении применяются шарошечные долота из высокопрочных сплавов с центральной или боковой промывкой, которые пробивают любую породу. При этом промывочная жидкость осуществляет выброс грунта из скважины и препятствует обрушению стенок пробуренного ствола. Поэтому роторным способом достигается глубина более 200м. Почему бурение называется роторным? Долото проходит твердую породу не только потому, что прилагает усилие и «пробивает» ее, но и потому что вращается и подает промывочную жидкость под давлением. А вращается долото при помощи ротора — крутящейся части двигателя. Ротор применяется в ряде технических областей, и бурильное оборудование — не исключение. Увидимся!
Gustavo
coursework english language coursework planning coursework example pdf
Jefferey
coursework handbook coursework computer science coursework example pdf
Joy
coursework writing services coursework only degree creative writing coursework ideas
Bogdansnp
Привет дамы и господа! https://astraclub.ru/members/245794-Bogdanovv https://forum.dalion.ru/member.php?u=20435 http://1.12315tt.com/viewthread.php?tid=850986&extra= https://astraclub.ru/members/311324-Bogdanumg http://forum.soundspeed.ru/member.php?586620-Bogdannvj Предлагаем Вашему вниманию изделия из стекла для дома и офиса.Наша организация ООО «СТЕКЛОЭЛИТ» работает 10 лет на рынке этой продукции в Беларуси.Стеклянные двери межкомнатные в Минске с ценами и фото представлены на данной странице. Вы можете заказать и купить их с бесплатным замером и доставкой по Беларуси. Вам по нраву такой неординарный вариант как стеклянные межкомнатные двери? Наша Команда в Минске расскажет всё о секретах установки, дизайнах интерьера с примерами фото, и поможет выбрать и купить дверь вашей мечты по нормальным ценам. Плюсы и минусы дверей из стекла: Сейчас такие варианты пользуются большой популярностью. Их выбирают для установки в душе, бане, а некоторые и вовсе предпочитают видеть их в качестве межкомнатных. Увидимся!
Leave a comment
Your email address will not be published. Required fields are marked *