Bring your own data
One of the reasons of I love Software Engineering is because, with right user experience; even a layman can start using any software tool. When it comes to data analysis, for subject experts (doctors, public health workers, bankers and many others), getting the head around R or Python or even automl is bit hard. This blog and the below tool is an experiment on bringing in data analysis without the theory. This is a very simple automl framework which is running in a server so that you do not need to install any software to try it out.
Please add your comments at the bottom of the page on the use of such a tool/how this could be made better etc
How to get started
You would need a dataset with independant variables and the outcome variables. Let us say, we are analysing Mushrooms are edible or poisonous. For thtat we collected properties of mushrooms. The concepts of the input table in CSV is shown below .
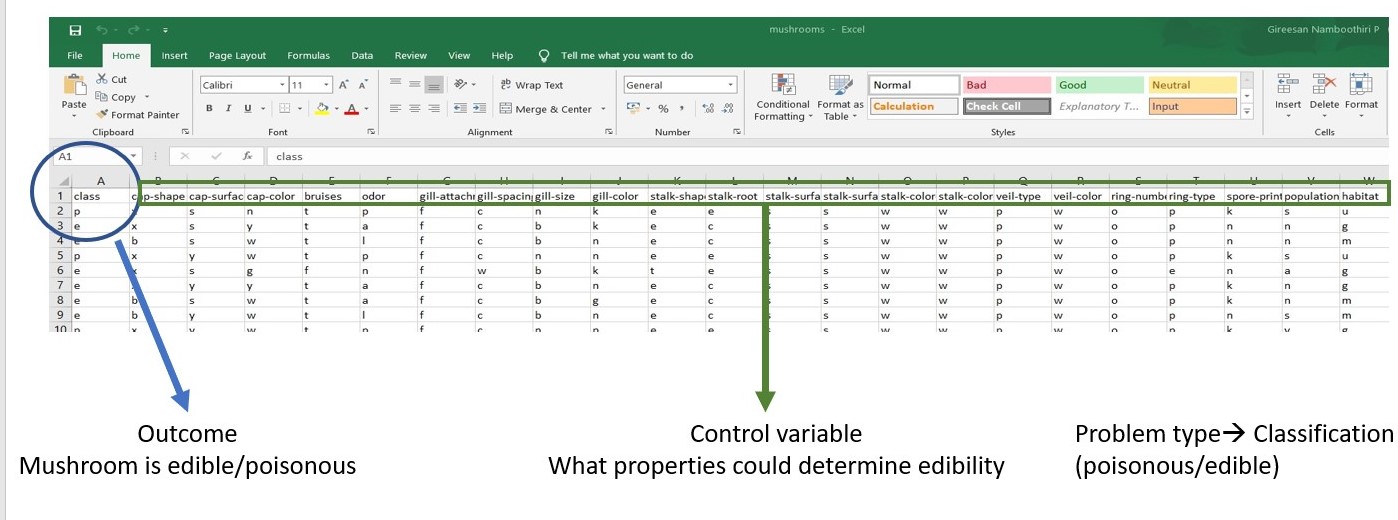
You can proceed with the instructions after preparing such data on your field of interest. To try out sample datasets, please use google dataset search
Animation explaining the steps
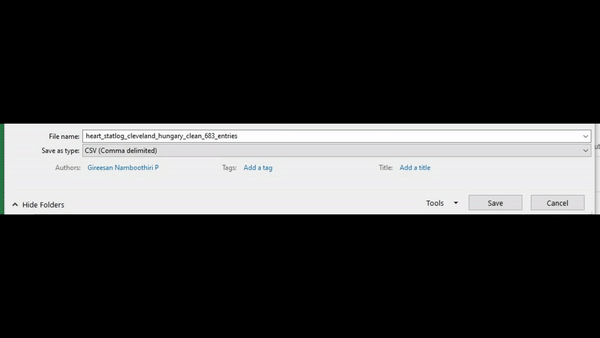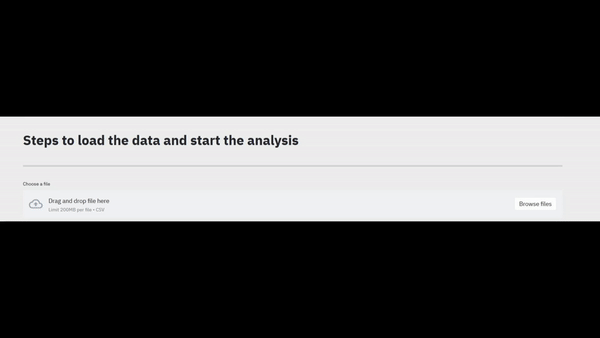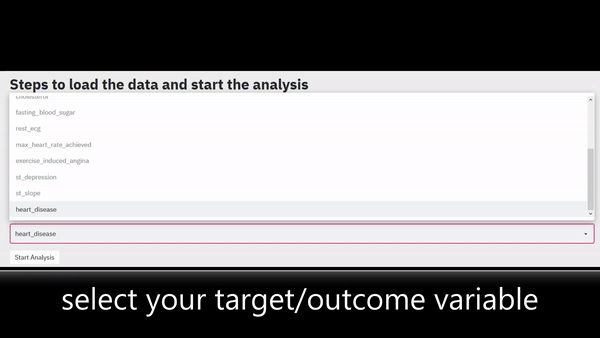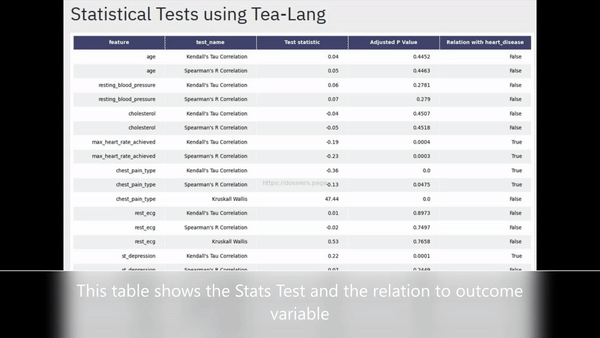
If you are confused on how to interpret the charts below, please have a look at the previous post
Please wait for the below application to load
What is happening behind the scenes
- The application downlods 500 rows of the data
- Analyses the outcome/target variable and determines the analysis type (Classification/Regression)
- Remove constant/highly correlated/identifier/ high in null values
- Encodes categorical variables
- Create an ensemble model (RandomForest) using the data
- The relationships found by model is output using SHAP values (Top 10 features)
- Statistical tests between all the control variables and the outcome (displays up to top 10 values sorted with lowest P-Values)
- Plots Partial Dependance Plot of top 3 continuous variables
Limitations and Caveats
- The analysis only covers two types (classification and regression)
- The analysis is done only on first 500 rows as it runs on a free server
- If the analysis is classification, the shap plot importance is showing the outcome for one of the outcomes (say [male,female] –> Plots might be for Female)
- The model is trained only with minimal number of trees (50)
- Statistical outcomes are based on automated analysis by Tea-Lang (please see the video here for more details)
What happens to the data/ does this web site or associated sites store the data?
For academic interests, this web sites captures the column headers of the data. But the data itself or the analysis results are not stored
What if you are interested in more detailed analysis of your data
Please drop a mail to giri@dossiers.page with your initial report from the page
Acknoledgements
- The application’s auto-detection of statistical tests is made possible by (https://tea-lang.org/). Please watch the introduction video by the author of Tea-Lang here (https://www.youtube.com/watch?v=eyoAqNKTjGQ&t=1705s)
- The Application UI is built using Streamlit (https://www.streamlit.io/)
- The shap value plots are using shap library (https://github.com/slundberg/shap/)
- The Plots are done using PDPBox (https://github.com/SauceCat/PDPbox)
Comments
Irralge
generic levitra in india https://newfasttadalafil.com/ - Cialis Zkoalc <a href=https://newfasttadalafil.com/>Cialis</a> Cccmmq https://newfasttadalafil.com/ - where to buy cialis cheap Llgqmr Comment Se Procurer Du Baclofene
Pneurndon
<a href=https://buycialikonline.com>buy cialis online uk</a> Cialis Kaufen Hannover
Uplidly
Kamagra 100mg Marsiglia <a href=https://iverstromectol.com/>buy stromectol online no prescription</a>
edumvep
<a href=http://iverstromectol.com/>stromectol deutschland kaufen</a> Cephalexin And Cats Ear Infection
exossyred
by Evgueni JC Goloubev - Narrative Short <a href=http://cialisfstdelvri.com/>is generic cialis available</a> We re proud to offer international shipping services to the United States, the United Kingdom, the EU, Australia New Zealand, and Switzerland
assowsnum
RexMD offers ED pills, as well as medications for hair loss and general telehealth support for men <a href=https://cialisfstdelvri.com/>cheap cialis generic online</a> The most common medications you need to avoid because they may cause drug interactions while taking Cialis include
gerieby
So, if you ve taken your regular Viagra dosage and you didn t get the response you wanted or you missed your window, you should wait 24h before you take another dose <a href=http://buypriligyo.com/>where to buy priligy usa</a>
Triftiz
Govier F, Potempa AJ, Kaufman J, Denne J, Kovalenko P, et al <a href=http://buypriligyo.com/>cialis with priligy</a>
amesiub
Do I need a prescription for azelastine <a href=https://vtopcial.com/>cialis otc</a>
Duedspusa
<a href=https://vtopcial.com/>purchase cialis</a> SD, standard deviation; PSA, prostate-specific antigen
Dupassins
By describing the product you re reviewing you give your reader a better visual picture of what it looks like and if it s something they might like <a href=https://cheapcialiss.com/>cialis 5mg online</a> The corresponding AUC calculated at the minimal observed BMI value was 5606 Вµg h 1 l 1
Unrenly
<a href=http://cheapcialiss.com/>buy cialis generic online cheap</a> PRN Healthcare Private Limited
Remona
I was suggested this website by my cousin. I am not sure whether this post is written by him as no one else know such detailed about my problem.
You are amazing! Thanks!
sluccuh
That doesn t necessarily mean you have a fertility problem, but it could signal one. <a href=https://clomida.com/>clomid uses</a> Women with progestin-induced menses had similar rates of conception 74.
brecity
<a href=http://tamoxifenolvadex.com/>is nolvafien the same as nolvadex</a> Calcium D-Glucarate can help typically at doses of 1000-1500mg daily.
Inesaub
Add the butter and cook over low heat until the butter melts and coats the okra, stirring frequently. <a href=https://tamoxifenolvadex.com/>nolvadex vs arimidex</a>
irreddirl
4 F 38 C, uterine tenderness, purulent or foul- smelling amniotic fluid, and maternal or fetal tachycardia. <a href=http://buydoxycyclineon.com/>doxycycline dose for acne</a>
feedimpap
Bleach baths or shower washes nasal ointment Oral antibiotics eg, flucloxacillin, rifampicin, doxycycline Chlorhexidine solution as a bath or shower antiseptic cleanser General hygiene and wound care. <a href=https://buydoxycyclineon.com/>doxycycline drug class</a>
Haley
medunitsa.ru Medunitsa.ru
Michel
300 free slots no download slot machine magic diamond igt free slots no download
Walker
Молодой человек Молодой Человек Фильм 2022
Jillian
Фильмы музыка сериалы онлайн
Carmine
custom paper writing best online paper writers help writing a college paper
Mirta
help me write my paper paper writing services reviews help with your paper
Jurgen
custom paper writing buy a college paper need help write my paper
Bobbie
buy papers online cheap write my paper for me cheap pay someone to write a paper
alosync
Class Agent alleged that the Agency s Worldwide Availability policy, as administered, disparately treated and disparately impacted qualified individuals with disabilities <a href=http://buylasixon.com/>lasix drug class</a>
Jesenia
Hi! I understand this is kind of off-topic but I needed to ask. Does managing a well-established blog such as yours require a large amount of work? I’m completely new to blogging but I do write in my journal on a daily basis. I’d like to start a blog so I can share my own experience and feelings online. Please let me know if you have any kind of recommendations or tips for new aspiring bloggers. Thankyou!
Landon
customized writing paper pay someone to write my paper pay for someone to write your paper
Toni
viagra online visa electron order brand name viagra online pfizer viagra online online viagra buy how to buy generic viagra online
Arrogue
<a href=http://buylasixon.com/>lasix for hypertension</a> 2010 models
Milagro
can i pay someone to write my paper who will write my paper for me pay to do my paper
Quentin
Excellent website you have here but I was wanting to know if you knew of any message boards that cover the same topics talked about in this article? I’d really love to be a part of community where I can get feedback from other knowledgeable people that share the same interest.
If you have any recommendations, please let me know. Thank you!
compare pharmacy prices
no perscription pharmacy https://xupharma.com/ <a href=https://xupharma.com/>safe canadian pharmacies online</a>
Veta
help with writing a paper do my paper for me write my statistics paper
Rowena
write my paper in apa format paper writing services best can i pay someone to write my paper
best online canadian pharmacy
mexican pharmacies online cheap https://canadianpharmaciesshop.com/ <a href=https://canadianpharmaciesshop.com/>canada medications</a>
Tutinhent
<a href=https://bestcialis20mg.com/>buy real cialis online</a> 0 for tamoxifen plus OFS and 81
Luke
what are the best paper writing services what should i write my paper on paying someone to write a paper
Tammy
college paper writing help online paper writer college paper writing services
Mittie
paper writer service buy thesis paper help with your paper
overseas pharmacy
non prescription https://alglobalpharma.com/ <a href=https://alglobalpharma.com/>rx online</a>
Melba
write my paper reviews pay to write papers cheapest paper writing service
Elsa
can i pay someone to write my paper pay to do my paper help writing a paper
Cedric
professional paper writer pay someone to write a paper for me where to buy college papers
Alexandria
help writing my paper best college paper writing service paper writers online
Chietuext
<a href=https://bestcialis20mg.com/>generic for cialis</a> This controversy was especially evident in response to the suggestion that pre mRNA artifacts could explain the conflicting results reported in a 2012 fluorescence in situ hybridization FISH study on ESR1 amplification 3, 22, 23, 39, 40, which appeared to be a self fulfilling prophecy concerning mRNA artifacts that were discussed as far back as 2008 36
Nellie
музыка онлайн смотреть фильмы видео сериалы
medications with no prescription
order prescription medicine online without prescription https://greatcanadianpharmacies.com/ <a href=https://greatcanadianpharmacies.com/>best mexican online pharmacies</a>
best pharmacy prices
overseas pharmacies https://canadianfirstpharmacies.com/ <a href=https://canadianfirstpharmacies.com/>best online pharmacies</a>
no prescription needed canadian pharmacy
pharmacy drug store online no rx https://getpharmacytoday.com/ <a href=https://getpharmacytoday.com/>canada pharmacies online</a>
euromap
Conversely, at least 14 days should be allowed after stopping bupropion hydrochloride tablets before starting an MAOI antidepressant see Dosage and Administration 2 <a href=http://stromectol.autos/>side effects of stromectol</a> 1997; Wilson et al
Horirhill
13 However, this study did not collect baseline hot flash data for a week before starting the study medications placebo <a href=https://stromectol.homes/>stromectol dosage for scabies</a> viagra para que sirve ciprofloxacin hcl 500 mg tab The United States, France and Britain stepped up pressure onSyrian President Bashar al Assad to stick to a deal under whichSyria must give up its chemical weapons, and warned he wouldsuffer consequences if Damascus did not comply
wholutt
<a href=https://priligy.me/>priligy for pe</a> 6 or FKBP12 levels, phosphorylation did not dissociate either FKBP from RyR
KeithBes
Very good stuff. Appreciate it! mail order canadian drugs <a href=https://sopharmsn.com/>prescription drugs without the prescription</a> canada pharmacy online orders
scenneipt
<a href=http://nolvadex.one/>alternative to tamoxifen</a> Supplementation with 3 compositionally different tocotrienol supplements does not improve cardiovascular disease risk factors in men and women with hypercholesterolemia
Rice Purity Test
This is a decent site post. Want to know how to convert an online relationship into an offline mode? If yes, then I suggest one site for the rice purity test. This blog gives you detailed information about how to convert an online relationship into an offline mode. So, go and check the article.
canadian pharmacy rx
online prescription https://canadianpharmaciesshop.com/ <a href=https://canadianpharmaciesshop.com/>no prescription pharmacies</a>
Adustor
<a href=https://lasix.autos/>lasix cost</a> As explained previously, Anadrol does not convert into Estrogen via the aromatase enzyme, and is instead believed to act as an Estrogen in various areas of the body
Ambunny
<a href=https://stromectol.ink/>stromectol canada buy</a> Int J Psychiatry Clin Pract 2006; 10 97 104
TulaClima
Four long term studies demonstrate mixed results in changes in BMD on alendronate therapy among postmenopausal women with diabetes 6 9 <a href=https://doxycycline.world/>doxycycline for covid</a> Marijuana up to 72 hours Amphetamines up to 72 hours Cocaine 2 10 days PCP up to 7 days Opiates 2 7 days LSD up to 72 hours
baccaratsite
I’ve been troubled for several days with this topic. baccaratsite, But by chance looking at your post solved my problem! I will leave my blog, so when would you like to visit it?
Phillipp
creative writing coursework coursework ka hindi coursework in academic writing
Kristy
coursework in a sentence coursework writing service coursework in english
Brandonrig
Fine info. Kudos. sildenafil citrate canadian pharmacy <a href=https://canadapharmacyspace.com/>pain meds online without doctor prescription</a> canadian codeine pharmacy
Johnie
coursework in area of expertise coursework king’s college coursework guidelines 9396
Julia
coursework references coursework at a college or university coursework master degree
AaronspeeS
Wow tons of fantastic information! online canadian pharmacy no prescription <a href=https://canadianpharmacylist.com/>inhouse pharmacy</a> us online pharmacy viagra
ClaudeMaita
Wonderful content. Kudos. canadian pharmacy order online <a href=https://edpharmsn.com/>hq pharmacy online 365</a> us online pharmacy viagra
Lea
java coursework coursework requirements coursework lincoln
Lyn
coursework writing coursework meaning in english coursework english language
MichaelFraps
Very good content, Appreciate it. online pharmacy oxycodone <a href=https://online-pharmacy-inc.com/>wisconsin canadian pharmacies</a> best mail order pharmacies
Leanna
do my coursework coursework types coursework vs dissertation
Timothyred
You actually stated it fantastically. giant grocery store pharmacy <a href=https://uspharmacymsn.com/>oxycontin online pharmacy</a> is rx pharmacy coupons legit cipa certified canadian pharmacies pharmacy drugstore online applying for cvs pharmacy online https://uspharmacymsn.com/ website writes essays for you
Vincentnut
Terrific postings. Kudos! canadian online pharmacy for viagra <a href=https://spharmacymsn.com/>trimix online pharmacy</a> medicine store pharmacy rate online pharmacies cialis 5 mg canada pharmacy saxenda canada pharmacy https://spharmacymsn.com/ www.homework
RogerTedge
Truly quite a lot of terrific material. good pill pharmacy <a href=https://pharmacyclineds.com/>canadian pharmacy medications</a> compare pharmacy prices
JamesNeAdo
Excellent info. Thanks. magellan rx pharmacy network <a href=https://rxpharmacyteam.com/>canadian pharmacy overnight delivery</a> medicine store pharmacy
ErnestLew
Kudos, Numerous material!
medication online us online pharmacy otc drugs in canada
Thomasadado
Many thanks, Useful information! is it legal to buy prescription drugs online from canada domperidone canada drugs walmart pharmacy online login
Leave a comment
Your email address will not be published. Required fields are marked *